Probabilmente sai come inserire record in una tabella utilizzando una o più clausole VALUES. Sai anche come eseguire inserimenti in blocco utilizzando SQL INSERT INTO SELECT. Ma hai comunque cliccato sull'articolo. Si tratta di gestire i duplicati?
Molti articoli trattano SQL INSERT INTO SELECT. Google o Bing it e scegli il titolo che ti piace di più:lo farà. Non tratterò nemmeno esempi di base di come è fatto. Invece, vedrai esempi di come usarlo E gestire i duplicati allo stesso tempo . Quindi, puoi trarre questo messaggio familiare dai tuoi sforzi INSERT:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Ma prima le cose.

[sendpulse-form id=”12989″]
Prepara i dati di test per SQL INSERT IN SELECT Code Samples
Sto pensando alla pasta questa volta. Quindi, userò i dati sui piatti di pasta. Ho trovato un buon elenco di piatti di pasta in Wikipedia che possiamo usare ed estrarre in Power BI utilizzando un'origine dati Web. Ho inserito l'URL di Wikipedia. Quindi ho specificato i dati a 2 tabelle dalla pagina. Ripulito un po' e copiato i dati in Excel.
Ora abbiamo i dati:puoi scaricarli da qui. È grezzo perché ne creeremo 2 tabelle relazionali. L'uso di INSERT INTO SELECT ci aiuterà a svolgere questo compito,
Importa i dati in SQL Server
Puoi utilizzare SQL Server Management Studio o dbForge Studio per SQL Server per importare 2 fogli nel file Excel.
Creare un database vuoto prima di importare i dati. Ho chiamato le tabelle dbo.ItalianPastaDishes e dbo.NonItalianPastaDishes .
Crea altre 2 tabelle
Definiamo le due tabelle di output con il comando SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Nota:esistono indici univoci creati su due tabelle. Ci impedirà di inserire record duplicati in un secondo momento. Le restrizioni renderanno questo viaggio un po' più difficile ma emozionante.
Ora che siamo pronti, tuffiamoci.
5 semplici modi per gestire i duplicati utilizzando SQL INSERT INTO SELECT
Il modo più semplice per gestire i duplicati è rimuovere i vincoli univoci, giusto?
Sbagliato!
Con l'eliminazione dei vincoli univoci, è facile commettere un errore e inserire i dati due o più volte. Non lo vogliamo. E se avessimo un'interfaccia utente con un elenco a discesa per selezionare l'origine del piatto di pasta? I duplicati renderanno felici i tuoi utenti?
Pertanto, la rimozione dei vincoli univoci non è uno dei cinque modi per gestire o eliminare record duplicati in SQL. Abbiamo opzioni migliori.
1. Usando INSERT INTO SELECT DISTINCT
La prima opzione per identificare i record SQL in SQL consiste nell'usare DISTINCT in SELECT. Per esplorare il caso, compileremo Origin tavolo. Ma prima, usiamo il metodo sbagliato:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Ciò attiverà i seguenti errori duplicati:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Si verifica un problema quando si tenta di selezionare righe duplicate in SQL. Per avviare il controllo SQL per i duplicati che esistevano prima, ho eseguito la parte SELECT dell'istruzione INSERT INTO SELECT:
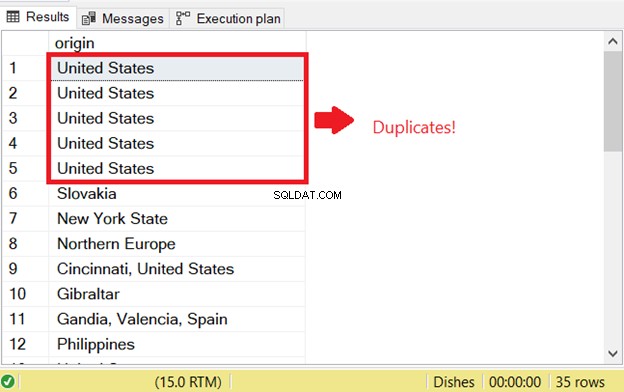
Questo è il motivo del primo errore di duplicato SQL. Per prevenirlo, aggiungi la parola chiave DISTINCT per rendere unico il set di risultati. Ecco il codice corretto:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Inserisce i record con successo. E abbiamo finito con l'Origin tabella.
L'uso di DISTINCT creerà record univoci dall'istruzione SELECT. Tuttavia, non garantisce che non esistano duplicati nella tabella di destinazione. È utile quando sei sicuro che la tabella di destinazione non abbia i valori che desideri inserire.
Quindi, non eseguire queste istruzioni più di una volta.
2. Usando WHERE NOT IN
Successivamente, compileremo i PastaDishs tavolo. Per questo, dobbiamo prima inserire i record da ItalianPastaDishs tavolo. Ecco il codice:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Dal momento che PastaDishes Italiani contiene dati grezzi, dobbiamo unirci a Origin testo invece di OriginID . Ora, prova a eseguire lo stesso codice due volte. La seconda volta che viene eseguito non avrà record inseriti. Succede a causa della clausola WHERE con l'operatore NOT IN. Filtra i record già esistenti nella tabella di destinazione.
Successivamente, dobbiamo popolare i PastaDishes tabella dei Non ItalianPastaDishes tavolo. Poiché siamo solo al secondo punto di questo post, non inseriamo tutto.
Abbiamo scelto piatti di pasta dagli Stati Uniti e dalle Filippine. Ecco:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Sono stati inseriti 9 record da questa dichiarazione – vedere la Figura 2 di seguito:
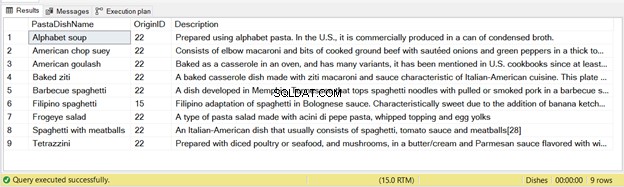
Anche in questo caso, se esegui il codice sopra due volte, la seconda esecuzione non avrà record inseriti.
3. Usando DOVE NON ESISTE
Un altro modo per trovare duplicati in SQL consiste nell'usare NOT EXISTS nella clausola WHERE. Proviamolo con le stesse condizioni della sezione precedente:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Il codice sopra inserirà gli stessi 9 record che hai visto nella Figura 2. Eviterà di inserire gli stessi record più di una volta.
4. Usando SE NON ESISTE
A volte potrebbe essere necessario distribuire una tabella nel database ed è necessario verificare se esiste già una tabella con lo stesso nome per evitare duplicati. In questo caso, il comando SQL DROP TABLE IF EXISTS può essere di grande aiuto. Un altro modo per assicurarti di non inserire duplicati è usare SE NON ESISTE. Anche in questo caso, utilizzeremo le stesse condizioni della sezione precedente:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Il codice sopra verificherà prima l'esistenza di 9 record. Se restituisce true, INSERT procederà.
5. Utilizzando COUNT(*) =0
Infine, l'uso di COUNT(*) nella clausola WHERE può anche garantire di non inserire duplicati. Ecco un esempio:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Per evitare duplicati, il COUNT o i record restituiti dalla sottoquery precedente devono essere zero.
Nota :puoi progettare visivamente qualsiasi query in un diagramma utilizzando la funzionalità Generatore di query di dbForge Studio per SQL Server.
Confronto tra diversi modi per gestire i duplicati con SQL INSERT INTO SELECT
4 sezioni utilizzavano lo stesso output ma approcci diversi per inserire record di massa con un'istruzione SELECT. Potresti chiederti se la differenza è solo in superficie. Possiamo controllare le loro letture logiche da STATISTICS IO per vedere quanto sono diversi.
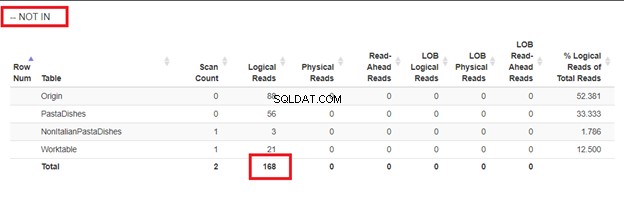
Usando WHERE NOT IN:
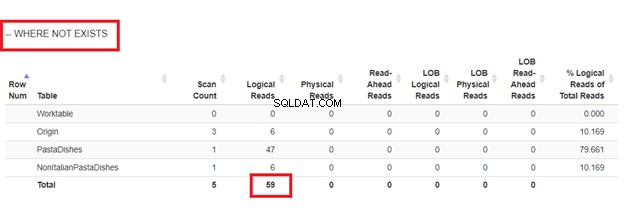
Usando NON ESISTE:
Usando SE NON ESISTE:
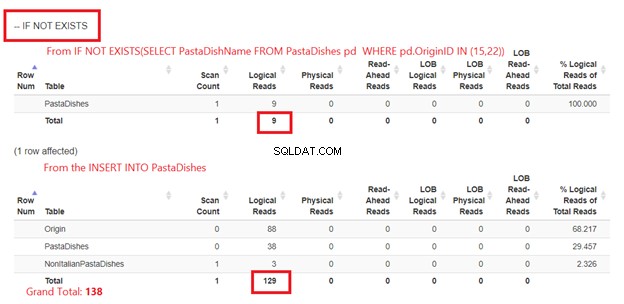
La figura 5 è leggermente diversa. Vengono visualizzate 2 letture logiche per i PastaDishs tavolo. Il primo è da SE NON ESISTE(SELECT PastaDishName da PastaPiatti DOVE OriginID IN (15,22)). Il secondo è dall'istruzione INSERT.
Infine, utilizzando COUNT(*) =0
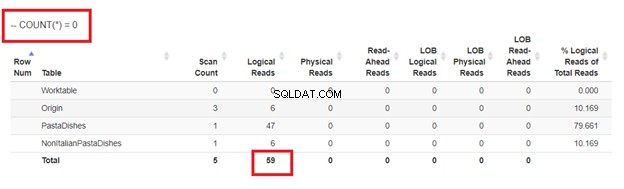
Dalle letture logiche di 4 approcci che abbiamo avuto, la scelta migliore è WHERE NOT EXISTS o COUNT(*) =0. Quando ispezioniamo i loro piani di esecuzione, vediamo che hanno lo stesso QueryHashPlan . Quindi, hanno piani simili. Nel frattempo, quello meno efficiente sta usando NOT IN.
Vuol dire che WHERE NOT EXISTS è sempre meglio di NOT IN? Per niente.
Ispeziona sempre le letture logiche e il Piano di esecuzione delle tue query!
Ma prima di concludere, dobbiamo finire il compito a portata di mano. Quindi inseriremo il resto dei record e ispezioneremo i risultati.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Sfogliare dalla lista di 179 primi piatti dall'Asia all'Europa mi fa venire fame. Dai un'occhiata a una parte dell'elenco da Italia, Russia e altro da qui sotto:

Conclusione
Evitare i duplicati in SQL INSERT INTO SELECT non è poi così difficile. Hai operatori e funzioni a portata di mano per portarti a quel livello. È anche una buona abitudine controllare il Piano di esecuzione e le letture logiche per confrontare quale è migliore.
Se pensi che qualcun altro trarrà vantaggio da questo post, condividilo sulle tue piattaforme di social media preferite. E se hai qualcosa da aggiungere che abbiamo dimenticato, faccelo sapere nella sezione Commenti qui sotto.