Introduzione
Capire quale tipo di infrastruttura di database è necessaria per soddisfare i requisiti di prestazioni, affidabilità e scalabilità delle applicazioni può essere un compito difficile. Le scelte effettuate per la topologia del database possono influire sul modo in cui l'intero stack dell'applicazione risponde a diversi tipi di utilizzo e sugli scenari di errore che possono essere presi in considerazione. Per questo motivo, è importante comprendere le tue opzioni e prendere una decisione informata in linea con i tuoi obiettivi.
Esistono molti modi diversi per passare da un unico database che gestisce tutte le esigenze dell'infrastruttura a sistemi più complessi. Insieme a questo, ci sono molti compromessi da considerare.
In questa guida verranno introdotti alcuni dei modelli più comuni per l'infrastruttura di database relazionali e il modo in cui si allineano ai diversi modelli di utilizzo. Illustreremo quali vantaggi offre ciascuna configurazione e alcune delle carenze di cui è necessario tenere conto. Parleremo anche dell'impatto di diverse decisioni sulla complessità complessiva delle operazioni. Una volta terminato, dovresti essere in grado di prendere una decisione migliore su quali design sono più adatti alle tue esigenze attuali e quali opzioni potresti voler sperimentare man mano che le tue esigenze cambiano.
Ridimensionamento verticale
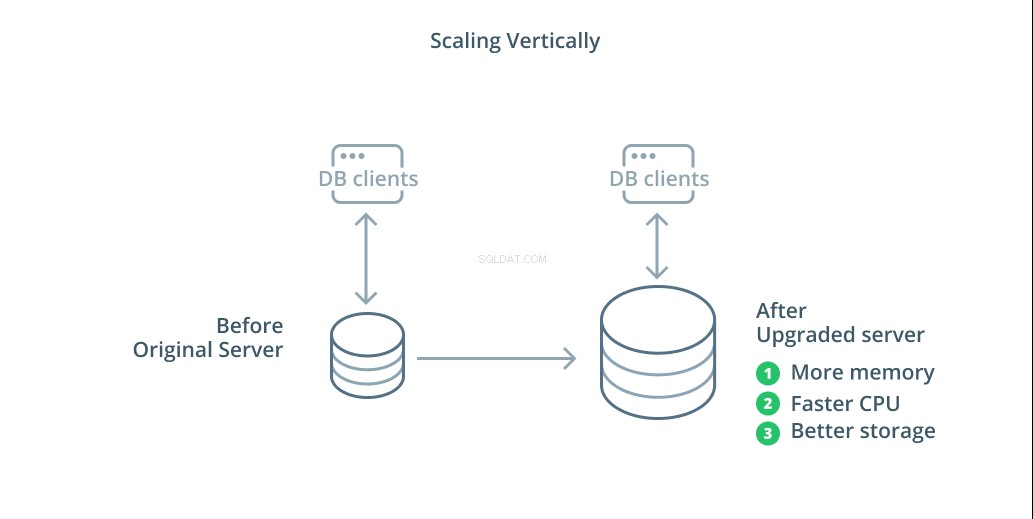
Il modo più semplice per ridimensionare un sistema di database è il ridimensionamento verticale. Ridimensionamento verticale , chiamato anche aumento scalare , significa aggiungere capacità al server che gestisce il tuo database. Aumentando la potenza di elaborazione, l'allocazione della memoria o la capacità di archiviazione, puoi aumentare le prestazioni e il volume che un sistema di database può gestire senza aumentare la complessità del sistema nel suo insieme.
Come regola generale, il ridimensionamento del database è un buon primo passo in quanto aumenta le capacità del database senza influire sulla topologia dell'infrastruttura. Anche il ridimensionamento è in genere abbastanza semplice, poiché una macchina di capacità maggiore può essere configurata come follower di replica fino a quando non viene sincronizzata e quindi può essere attivato un failover per farne il nuovo server primario.
Tuttavia, il ridimensionamento ha i suoi limiti perché la quantità di risorse che possono essere ragionevolmente allocate a una macchina è limitata. Rappresenta anche un singolo punto di errore se nessun follower di replica è configurato per subentrare quando si verificano problemi. Questi problemi vengono affrontati da alcune delle altre opzioni di ridimensionamento.
Segregazione della responsabilità delle query di comando (CQRS) e repliche di sola lettura
L'altro modo principale per ridimensionare l'infrastruttura del database è la scalabilità orizzontale. Ridimensionamento significa che invece di aumentare la capacità di un singolo server, aumenti il numero di server dedicati a soddisfare una specifica esigenza. Quindi aggiungi capacità aggiungendo macchine aggiuntive alla tua infrastruttura.
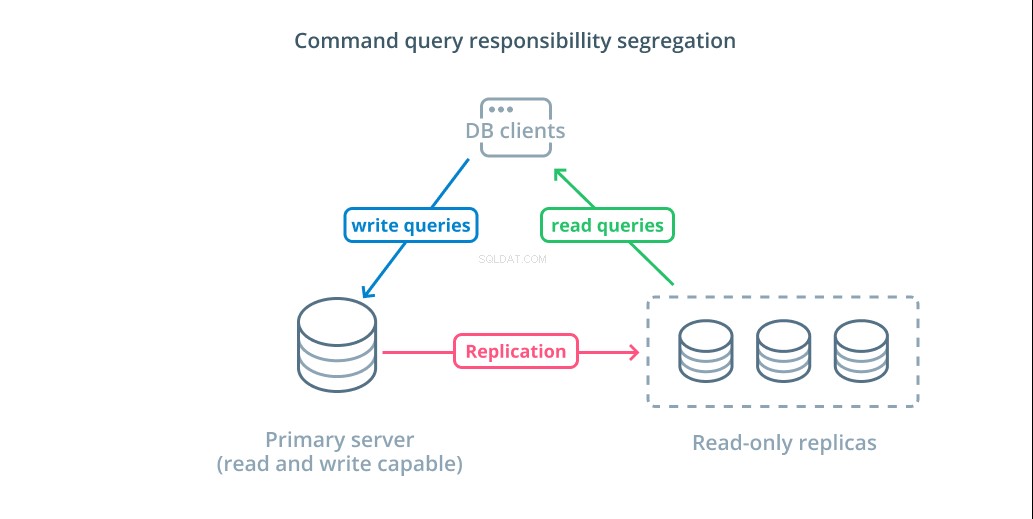
Segregazione della responsabilità delle query di comando (CQRS) è un termine usato per descrivere l'aggiunta di logica per separare le query che mutano i dati (scrittura di query) da quelle che non lo fanno (lettura di query). Ciò ti consente di instradare queste diverse categorie di richieste a host diversi per distribuire il carico.
L'infrastruttura più semplice per sfruttare questa progettazione è un server primario in grado di accettare query di lettura e scrittura combinate con uno o più server di replica che seguono il server primario in grado di accettare query di lettura. Questo design è appropriato per i modelli di utilizzo delle applicazioni che richiedono molta lettura, poiché le operazioni di lettura possono essere gestite da qualsiasi server di database.
Inoltre, questo sistema fornisce una certa ridondanza alla tua architettura poiché il sistema continuerà a funzionare se uno qualsiasi dei server si interrompe. Se un follower si interrompe, le richieste di lettura possono essere instradate agli altri server. Se il server primario si interrompe, uno dei follower della replica può essere promosso ad accettare query di scrittura.
Replica multi-primaria
Sebbene l'utilizzo di CQRS con repliche di sola lettura consenta di indirizzare un numero maggiore di richieste di lettura, non influisce in modo significativo sulle prestazioni di scrittura dell'infrastruttura. Per aumentare il numero di scritture che la tua architettura può gestire, devi considerare se puoi adottare un progetto di replica multiprimaria.
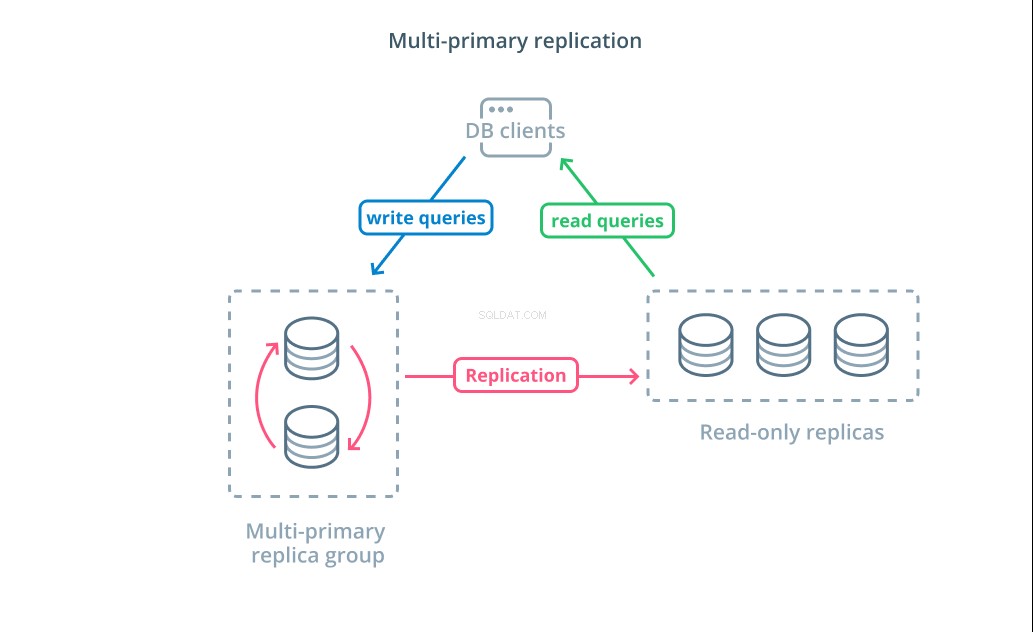
Replica multiprimaria è una forma di replica in cui più server possono accettare richieste di scrittura. Alcuni sistemi sono configurati in modo che qualsiasi server possa elaborare le richieste di scrittura, mentre altri sono progettati in modo che un gruppo principale di server primari gestisca le scritture con un numero maggiore di follower di sola lettura. Indipendentemente dall'implementazione, la replica multiprimaria aumenta il numero di server responsabili delle query di scrittura.
Sebbene questo design sembri l'ideale all'inizio, ci sono alcune sfide importanti che impediscono che questo sia un modello ampiamente adottato. Sebbene più server possano gestire le richieste di scrittura, devono comunque coordinarsi per replicare le modifiche tra i loro server e per risolvere i conflitti nelle modifiche ai dati. Ciò può portare a lunghi tempi di risposta durante la negoziazione di conflitti o alla possibilità di dati incoerenti.
Ogni sistema sceglie il proprio approccio per gestire queste sfide. Questa è una dimostrazione del Teorema CAP — una dichiarazione che descrive l'interazione tra coerenza, disponibilità e tolleranza della partizione nei sistemi distribuiti — in azione. Alcuni sistemi offrono garanzie di coerenza più deboli per mantenere la disponibilità, mentre altri database si rifiutano di accettare le modifiche se i loro peer non sono in grado di coordinare la transazione al momento della scrittura. La scelta dell'approccio più adatto alle proprie esigenze è un fattore importante quando si decide tra le varie implementazioni.
Leggi la memorizzazione nella cache delle query
Sebbene l'utilizzo delle repliche di sola lettura sia un modo per aumentare i database disponibili in grado di rispondere alle richieste di lettura, non migliora le prestazioni delle query di base di operazioni di lettura complesse. Uno dei server dovrebbe comunque eseguire l'operazione di lettura ogni volta che viene effettuata una richiesta, anche se i risultati sono identici alla ricerca precedente.
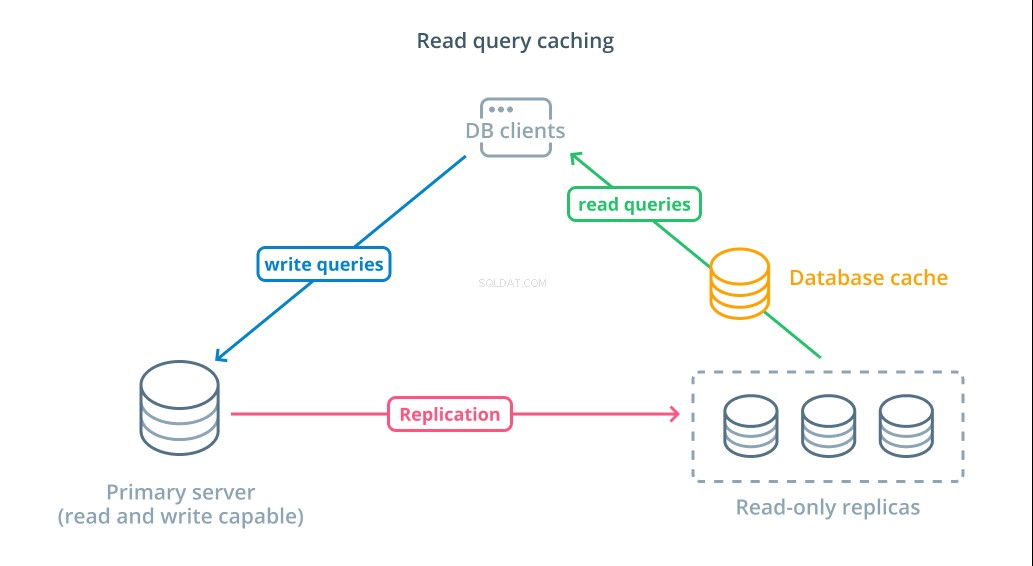
Per ridurre i tempi di risposta, una lettura della cache delle query strato può essere introdotto. L'aggiunta di una cache tra i client del database e i database stessi può ridurre notevolmente il tempo di query per le richieste comuni. L'applicazione può richiedere risultati di lettura dalla cache e riceverli quasi immediatamente se disponibili. Nei casi in cui i risultati non vengono trovati nella cache, vengono recuperati dal database stesso e aggiunti alla cache per la prossima volta.
La configurazione della memorizzazione nella cache in questo modo è incredibilmente efficiente per scenari in cui è improbabile che i dati cambino ogni volta che viene effettuata la richiesta. È particolarmente utile per query di lettura costose che consultano più tabelle e includono operazioni di join complesse. Questi risultati possono essere eseguiti una volta e poi salvati per query future.
Nei casi in cui i dati cambiano più rapidamente, una cache di lettura potrebbe non aiutare altrettanto. A seconda del comportamento configurato, le cache rischiano di restituire dati obsoleti in queste situazioni e dovrebbero essere implementate strategie ponderate di invalidamento della cache per rimuovere i dati obsoleti dalla cache quando vengono modificati.
Sharding dei dati
Finora, i progetti che abbiamo discusso hanno componenti di database segmentati in base al fatto che rispondano o meno alle richieste di scrittura. Tuttavia, un altro modo per dividere la responsabilità è suddividere il set di dati effettivo in più parti.
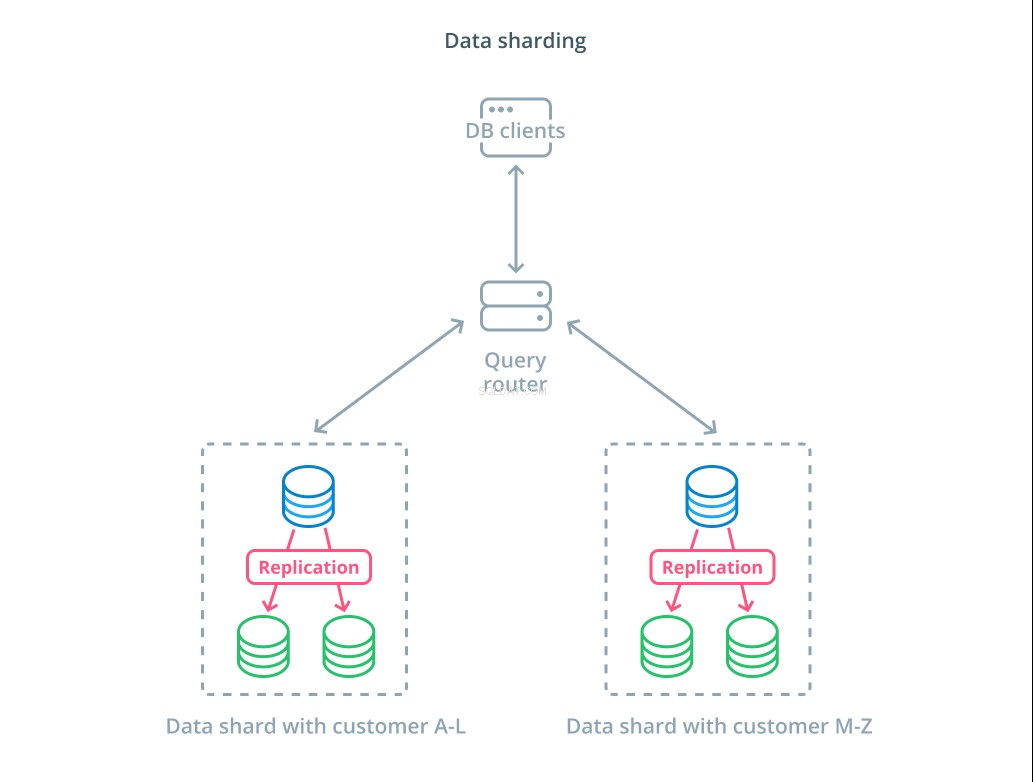
Sharding è il processo di suddivisione di un set di dati logici in sottoinsiemi più piccoli per distribuirne la gestione a macchine diverse. Ogni server di database gestisce solo una parte dei dati e viene introdotta una meccanica di routing che comprende quali macchine sono responsabili di quali dati.
In genere, il partizionamento orizzontale viene eseguito in scenari in cui l'operazione sull'intero set di dati in una volta non è necessaria o non è comune. Il set di dati viene segmentato in base al valore di ciascun record per una chiave specifica, nota come chiave di partizionamento orizzontale . Ad esempio, puoi dividere manualmente i dati in base alla posizione dei clienti. Puoi anche eseguire lo shard automaticamente utilizzando un algoritmo di hashing per determinare quali nodi devono gestire quali chiavi. Questo può aiutare il tuo sistema a evitare una distribuzione sbilanciata nei casi in cui lo spazio delle chiavi shard non è distribuito in modo uniforme.
Lo sharding introduce un po' di complessità nei sistemi di dati e non è appropriato per tutti gli scenari. Le operazioni che interagiscono con più shard subiranno significative penalizzazioni delle prestazioni mentre recuperano i risultati da ciascun membro. Ciò può verificarsi per query aggregate o se la chiave shard specifica non è nota in anticipo. Inoltre, l'allocazione non uniforme degli shard può anche causare inefficienze e colli di bottiglia che devono essere corretti riequilibrando la distribuzione dell'intero set di dati.
Gestione decentralizzata dei dati funzionali
Anziché suddividere i valori di un set di dati in più segmenti, in molti casi ha più senso utilizzare database diversi per scopi funzionali diversi. Ad esempio, se disponi di un servizio di account e di un servizio di prodotti, disporre di database dedicati che coincidono con ciascuna preoccupazione può aiutarti a ridimensionare diversi componenti in modo indipendente.
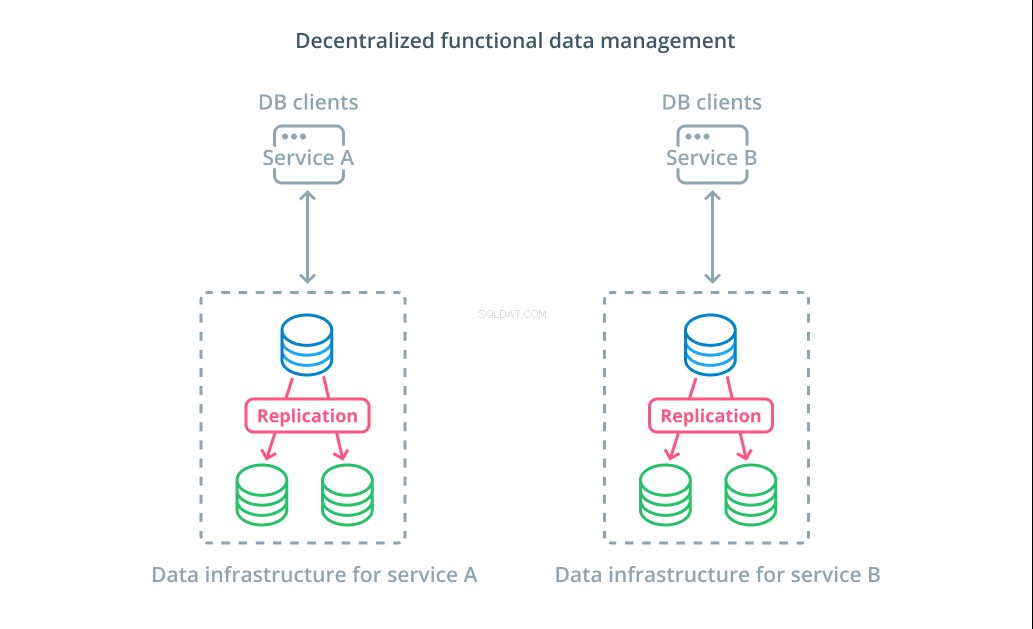
La gestione dei dati funzionali ti consente di scomporre la tua infrastruttura di database e gestire ogni parte in base alle esigenze dei suoi clienti. Ogni parte funzionale può essere ridimensionata utilizzando la strategia più sensata. Ti consente di progettare lo schema del database e distribuirlo in una posizione che corrisponda meglio ai modelli di un caso d'uso specifico invece di richiederlo per servire l'intera organizzazione.
Per molte organizzazioni, questa strategia presenta importanti vantaggi che vanno oltre le proprietà dei sistemi effettivi. La decentralizzazione della gestione dei dati può consentire ai team più piccoli di possedere i propri dati senza coordinare le modifiche con altre parti. Si allinea bene con la separazione mirata delle preoccupazioni promossa dalle architetture applicative orientate ai microservizi.
Database serverless
I diversi compromessi che devi valutare e la quantità di infrastruttura che potresti dover gestire per una scalabilità adeguata possono essere schiaccianti per molte persone. Un'opzione per scaricare questa complessità è sfruttare i servizi di database che gestiscono l'infrastruttura e la scalabilità per te.
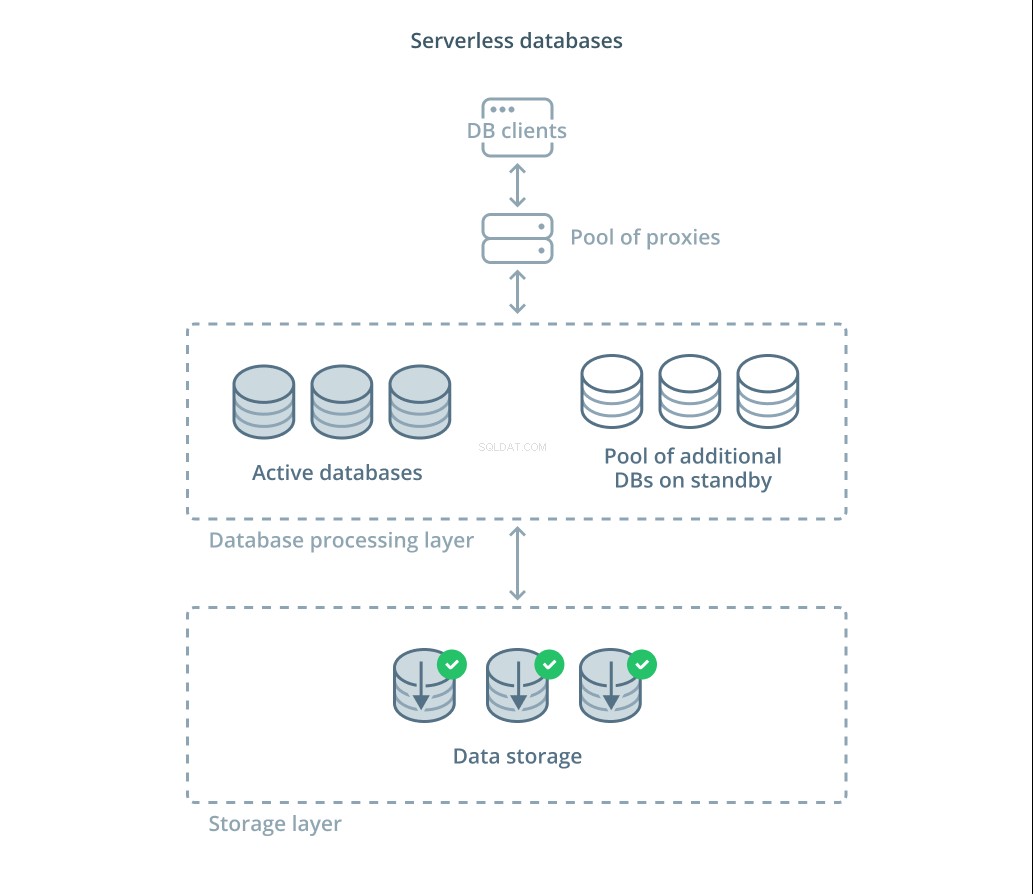
Database serverless sono una categoria di servizi che separa l'archiviazione dei dati dall'elaborazione dei dati per ridimensionare facilmente le risorse in risposta ai cambiamenti della domanda.
Un livello di archiviazione dei dati è responsabile del mantenimento dei dati effettivi gestiti dal sistema. Davanti a questo livello, viene distribuito un livello di unità di elaborazione del database scalabili per gestire l'elaborazione effettiva delle query rispetto ai set di dati. Il numero di unità attive in un dato momento è legato direttamente all'utilizzo corrente, quindi più risorse vengono allocate quando la domanda raggiunge i picchi e le unità di elaborazione vengono riportate in standby se le cose si calmano.
Le query vengono inoltrate ai processori del database tramite un proxy di routing che sa come inoltrare le richieste ai nodi attivi e quando richiedere risorse aggiuntive.
I database serverless hanno molte delle stesse proprietà dei servizi di database tradizionali che implementano funzionalità di scalabilità automatica. Entrambi possono allocare capacità in base alla domanda. Tuttavia, i database serverless consentono di separare i costi di archiviazione dai costi di elaborazione e possono ridurre l'elaborazione fino a zero quando non è necessario. Inoltre, le soluzioni serverless tendono a essere in grado di aumentare molto più rapidamente per soddisfare la domanda rispetto alla scalabilità automatica offerta dalle offerte tradizionali.
Sebbene i database serverless possano essere adatti ad alcuni, non sono un proiettile d'argento. Nei casi in cui i processori del database erano ridotto a zero, possono verificarsi nuovamente ritardi nell'elaborazione a causa di avviamenti a freddo. Inoltre, l'abbandono dovuto alle connessioni tra i vari componenti in uno stack di database serverless può portare a una latenza aggiuntiva.
Anche le piattaforme di database serverless possono essere difficili dal punto di vista operativo. Le distribuzioni e le modifiche al database possono essere più difficili da ragionare e monitorare. L'ambiente di sviluppo locale può anche differire in modo significativo dall'ambiente di produzione a causa dello stato dinamico del sistema di database. E infine, come con qualsiasi altro servizio cloud, l'utilizzo di database serverless può potenzialmente metterti in pericolo di blocco del fornitore. È importante ricordare questi compromessi quando si progetta attorno a una piattaforma serverless.
Conclusione
Esistono molti modi per progettare, distribuire e gestire l'infrastruttura del database man mano che i requisiti delle applicazioni diventano più seri. Ogni soluzione ha i suoi punti di forza e i suoi limiti che è importante comprendere quando si cerca di trovare una soluzione adatta al proprio ambiente.
L'apprendimento dell'impatto dell'infrastruttura del database sulla disponibilità, sulle prestazioni e sull'integrità dei dati consente di evitare errori costosi e implementazioni che non forniscono le garanzie necessarie. Se uno dei progetti di cui sopra non soddisfa i tuoi requisiti, potresti essere in grado di combinare alcuni degli elementi di approcci diversi per ottenere ulteriori vantaggi.
Se desideri saperne di più sui modelli generali trattati sopra, ecco alcune risorse aggiuntive che potresti voler controllare:
- Ridimensionamento rispetto a scalabilità orizzontale
- Segregazione della responsabilità delle query di comando
- Replica multiprimaria
- Memorizza nella cache le query di lettura
- Sharding dei dati
- Gestione decentralizzata dei dati
- Database serverless