Questa è la versione scritta del mio nuovo video su YouTube ✍️ 🙂
In questo tutorial su Redis imparerai a conoscere Redis e come Redis può essere utilizzato come database primario per applicazioni complesse che devono archiviare i dati in più formati.
Panoramica 📝
- Cos'è Redis e i suoi usi così come perché è adatto per le moderne applicazioni di microservizi complessi?
- Come Redis supporta l'archiviazione di più formati di dati per scopi diversi attraverso i suoi moduli ?
- In che modo Redis come database in memoria può persistenza dei dati e ripristino dalla perdita di dati ?
- Come scalare e replicare Redis ?
- Infine, poiché una delle piattaforme più popolari per l'esecuzione di microservizi è Kubernetes e poiché eseguire applicazioni stateful in Kubernetes è un po' impegnativo, vedremo come puoi facilmente eseguire Redis in Kubernetes
Che cos'è Redis?
Redis sta per re mote dic s tionary sempre
Redis è un database in memoria . Quindi molte persone l'hanno usato come cache in cima ad altri database per migliorare le prestazioni dell'applicazione. 🤓
Tuttavia, ciò che molte persone non sanno è che Redis è un database primario a tutti gli effetti che può essere utilizzato per archiviare e mantenere più formati di dati per applicazioni complesse. 😎
Quindi vediamo i casi d'uso per questo.
Perché database multimodello?
Diamo un'occhiata a una configurazione comune per un'applicazione di microservizi.
Diciamo che abbiamo un'applicazione di social media complessa con milioni di utenti. Per questo, potrebbe essere necessario archiviare formati di dati diversi in database diversi:
- Banca dati relazionale , come Mysql, per archiviare i nostri dati
- Ricerca elastica per ricerca e filtraggio rapidi
- Database grafico rappresentare le connessioni degli utenti
- Database dei documenti , come MongoDB per archiviare contenuti multimediali condivisi dai nostri utenti quotidianamente
- Servizio cache per una migliore performance dell'applicazione
È ovvio che si tratta di una configurazione piuttosto complessa.
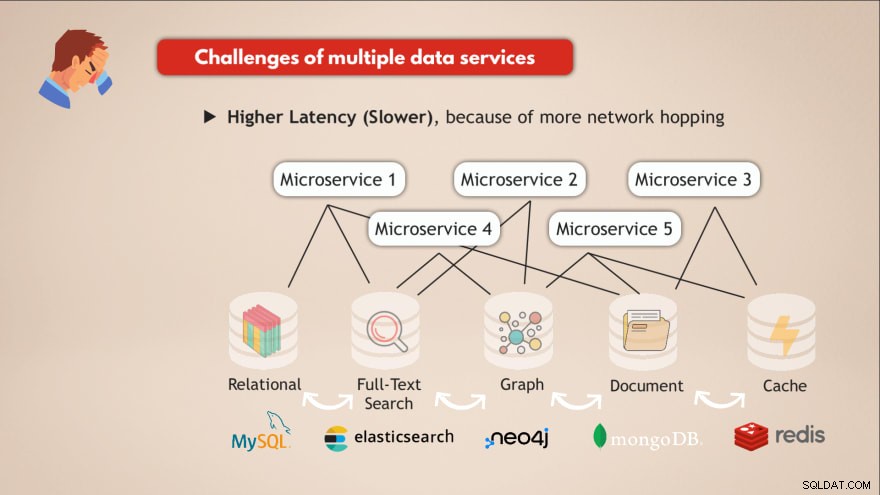
Le sfide di avere più servizi dati
- ❌ Ogni servizio dati deve essere distribuito e mantenuto
- ❌ Know-How necessario per ogni servizio dati
- ❌ Diversi requisiti di scalabilità e infrastruttura
- ❌ Codice applicativo più complesso per interagire con tutti questi diversi DB
- ❌ Latenza più alta (più lenta), a causa di più salti di rete
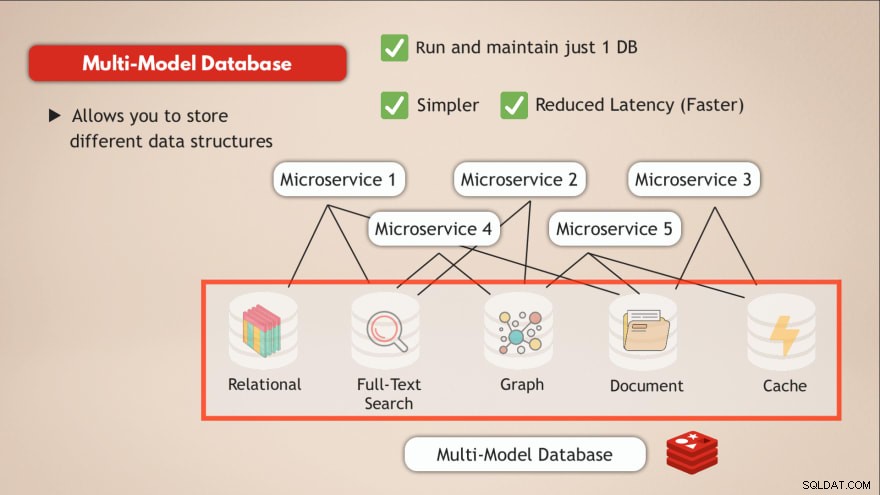
Avere un database multi-modello
Rispetto a un database multimodello, risolvi la maggior parte di queste sfide. Prima di tutto esegui e mantieni un solo servizio dati . Quindi la tua applicazione deve anche comunicare con un singolo archivio dati e ciò richiede solo un'interfaccia programmatica per quel servizio dati.
Inoltre, la latenza verrà ridotta passando a un singolo endpoint di dati ed eliminando diversi hub di rete interni.
Quindi avere un database, come Redis, che ti consente di archiviare diversi tipi di dati o sostanzialmente ti consente di avere più tipi di database in uno e fungere da cache risolve tali problemi.
- ✅ Esegui e mantieni un solo database
- ✅ Più semplice
- ✅ Latenza ridotta (più veloce)
Come funziona Redis?
Moduli Redis 📦
Il modo in cui funziona è che hai Redis Core, che è un key value store che supporta già la memorizzazione di più tipi di dati e quindi puoi estendere quel core con quelli che vengono chiamati moduli per diversi tipi di dati , di cui la tua applicazione ha bisogno per scopi diversi. Ad esempio, RediSearch per funzionalità di ricerca come ElasticSearch o Redis Graph per l'archiviazione dei dati dei grafici e così via:

E la cosa grandiosa di questo è che è modulare . Quindi questi diversi tipi di funzionalità di database non sono strettamente integrate in un database, ma puoi scegliere esattamente quale funzionalità del servizio dati è necessaria per la tua applicazione e quindi aggiungere sostanzialmente quel modulo.
Cache pronta all'uso ⚡️
Ovviamente quando usi Redis come database primario non hai bisogno di una cache aggiuntiva, perché con Redis lo hai automaticamente pronto all'uso. Ciò significa ancora una volta meno complessità nella tua applicazione, perché non è necessario implementare la logica per gestire il popolamento e l'invalidazione della cache.
Redis è veloce 🚀
Essendo un database in memoria (i dati sono archiviati nella RAM), Redis è super veloce e performante, il che ovviamente rende l'applicazione stessa più veloce.
Ma a questo punto ti starai chiedendo:
Come può un database in memoria mantenere i dati? 🤔
In che modo Redis può persistere i dati e riprendersi dalla perdita di dati? 🧐
Se il processo Redis o il server su cui è in esecuzione Redis non riesce, tutti i dati in memoria sono andati, giusto? Quindi, come vengono mantenuti i dati e fondamentalmente come posso essere sicuro che i miei dati siano al sicuro? 👀
Replicare Redis?
Bene, il modo più semplice per eseguire il backup dei dati è replicare Redis . Pertanto, se l'istanza master Redis si interrompe, le repliche saranno ancora in esecuzione e conterranno tutti i dati. Quindi, se hai un Redis replicato, le repliche avranno i dati.
Ma ovviamente se tutte le istanze Redis si interrompono, perderai i dati, perché non rimarranno repliche. 🤯Quindi abbiamo bisogno di una vera tenacia .
Istantanee e AOF
Redis dispone di molteplici meccanismi per la persistenza dei dati e la loro sicurezza.
Istantanee
Primo:gli snapshot, che puoi configurare in base al tempo, al numero di richieste ecc. Quindi gli snapshot dei tuoi dati verranno archiviati su un disco , che puoi utilizzare per recuperare i tuoi dati se l'intero database Redis è scomparso.
Ma tieni presente che perderai gli ultimi minuti di dati , perché di solito esegui gli snapshot ogni cinque minuti o un'ora a seconda delle tue esigenze. 😐
AOF
Quindi, in alternativa, Redis usa qualcosa chiamato AOF , che sta per A spend O solo F ile.
In questo caso ogni modifica viene salvata continuamente sul disco per la persistenza . E al riavvio di Redis o dopo un'interruzione, Redis riprodurrà i registri di aggiunta di solo file per ricostruire lo stato.
Quindi AOF è più durevole , ma può essere più lento dello snapshot.
Opzione migliore 💡 :usa una combinazione di AOF e snapshot, in cui l'AOF persiste i dati dalla memoria al disco continuamente, inoltre hai istantanee regolari in mezzo per salvare lo stato dei dati nel caso sia necessario ripristinarlo:

Come ridimensionare un database Redis?
Diciamo che la mia istanza Redis 1 esaurisce la memoria, quindi i dati diventano troppo grandi per essere mantenuti in memoria o Redis diventa un collo di bottiglia e non può gestire altre richieste. In tal caso, come posso aumentare la capacità e la dimensione della memoria per il mio database Redis? 🤔
Abbiamo diverse opzioni per questo:
1. Raggruppamento
Innanzitutto, Redis supporta il clustering . Ciò significa che puoi avere un'istanza Redis primaria o master, che può essere utilizzata per leggere e scrivere dati e puoi avere più repliche di tale istanza primaria per leggere i dati :
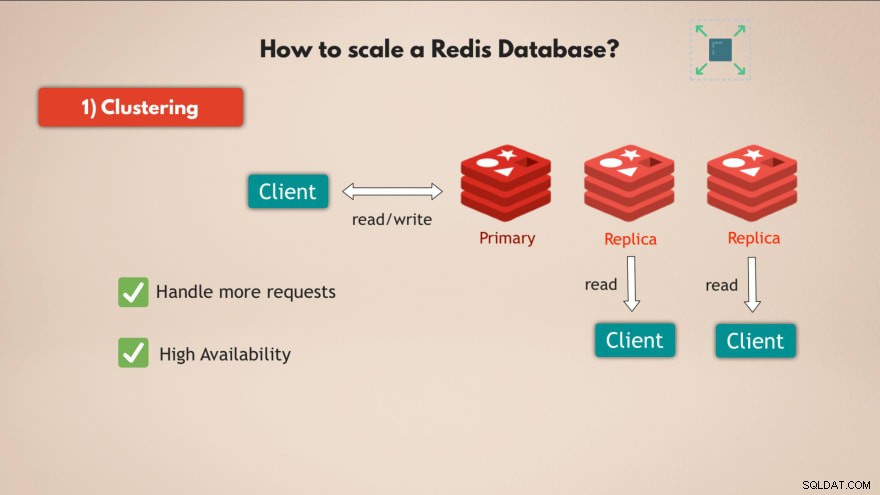
In questo modo puoi ridimensionare Redis per gestire più richieste e inoltre aumentare l'elevata disponibilità del tuo database, perché se il master fallisce 1 delle repliche può prendere il sopravvento e il tuo database Redis può sostanzialmente continuare a funzionare senza problemi.
2. Frammentazione
Bene, sembra abbastanza buono, ma se
- il tuo set di dati diventa troppo grande per stare in una memoria su un singolo server .
- Inoltre abbiamo ridimensionato le letture nel database, quindi tutte le richieste che in pratica si limitano a interrogare i dati. Ma la nostra istanza master è ancora sola e deve ancora gestire tutte le scritture .
Allora qual è la soluzione qui? 🤔
Per questo utilizziamo il concetto di sharding , che è un concetto generale nei database e che supporta anche Redis.
Quindi sharding fondamentalmente significa che prendete il vostro set di dati completo e lo dividete in blocchi o sottoinsiemi di dati più piccoli , dove ogni shard è responsabile del proprio sottoinsieme di dati.
Ciò significa che invece di avere un'istanza master che gestisce tutte le scritture sul set di dati completo, puoi dividerlo in, diciamo, 4 frammenti, ciascuno responsabile delle letture e delle scritture in un sottoinsieme dei dati . 💡
E ogni shard necessita anche di minore capacità di memoria , perché hanno solo un quarto dei dati. Ciò significa che puoi distribuire ed eseguire shard su nodi più piccoli e sostanzialmente ridimensionare il tuo cluster orizzontalmente:
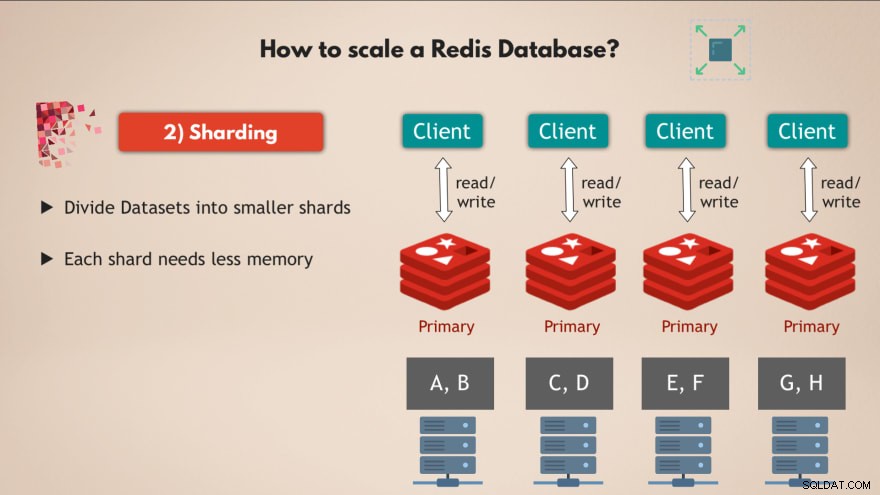
Quindi avere più nodi , che eseguono più repliche di Redis che sono tutti partizionati ti offre un database Redis molto performante e altamente disponibile in grado di gestire molte più richieste senza creare colli di bottiglia 👍
Altri argomenti...
Guarda il mio video qui sotto per gli ultimi 2 argomenti e scenari:
- Applicazioni che richiedono disponibilità e prestazioni ancora più elevate in più località geografiche
- Il nuovo standard per l'esecuzione di microservizi è la piattaforma Kubernetes, quindi eseguire Redis in Kubernetes è un caso d'uso molto interessante e comune
Il video completo è disponibile qui:🤓
Spero che questo sia stato utile e interessante per alcuni di voi! 😊
Mi piace, condividi e seguimi 😍 per ulteriori contenuti:
- Instagram - Postare molte cose dietro le quinte
- Gruppo FB privato



