Zone MongoDB
Per comprendere le zone MongoDB, dobbiamo prima capire cos'è una zona:un gruppo di shard basato su un insieme specifico di tag.
Le zone MongoDB aiutano nella distribuzione di blocchi basati su tag, tra shard. Tutto il lavoro (lettura e scrittura) relativo ai documenti all'interno di una zona viene eseguito su frammenti corrispondenti a quella zona.
Possono esserci diversi scenari in cui i cluster partizionati (basati sulla zona) possono rivelarsi molto utili. Diciamo:
- Un'applicazione geograficamente distribuita può richiedere il frontend, così come il datastore
- Un'applicazione ha un'architettura di livello n tale che alcuni record vengono recuperati da un hardware di livello superiore (bassa latenza), mentre altri potrebbero essere recuperati da un hardware di livello basso (che induce una latenza elevata)
Vantaggi dell'utilizzo delle zone MongoDB
Con l'aiuto delle zone MongoDB, i DBA possono realizzare soluzioni di archiviazione a livelli che supportano il ciclo di vita dei dati, con i dati utilizzati di frequente archiviati in memoria, i dati meno utilizzati archiviati sul server e, al momento opportuno, archiviati offline.
Come impostare le zone
Nei cluster partizionati, puoi creare zone che rappresentano un gruppo di partizioni e associare uno o più intervalli di valori di chiavi partizione a quella zona. MongoDB indirizza tutte le letture e tutte le scritture che entrano in un intervallo di zona solo a quegli shard all'interno della zona. Puoi associare ciascuna zona a uno o più shard nel cluster e uno shard può essere associato a un numero qualsiasi di zone.
Alcuni dei modelli di distribuzione più comuni in cui è possibile applicare le zone sono i seguenti:
- Isola un sottoinsieme specifico di dati su un insieme specifico di frammenti.
- Assicurando che i dati più rilevanti risiedano su shard geograficamente più vicini ai server delle applicazioni.
- Indirizza i dati agli shard in base alle prestazioni dell'hardware dello shard.
L'immagine seguente illustra un cluster partizionato con tre partizioni e due zone. La zona A rappresenta un intervallo con un limite inferiore di 0 e un limite superiore di 10. La zona B mostra un intervallo con un limite inferiore di 10 e un limite superiore di 20. I frammenti ROSSO e BLU hanno la zona A. Shard BLUE ha anche la zona B. Shard GREEN non ha zone ad esso associate. Il cluster è in uno stato stazionario e nessun blocco viola nessuna delle zone
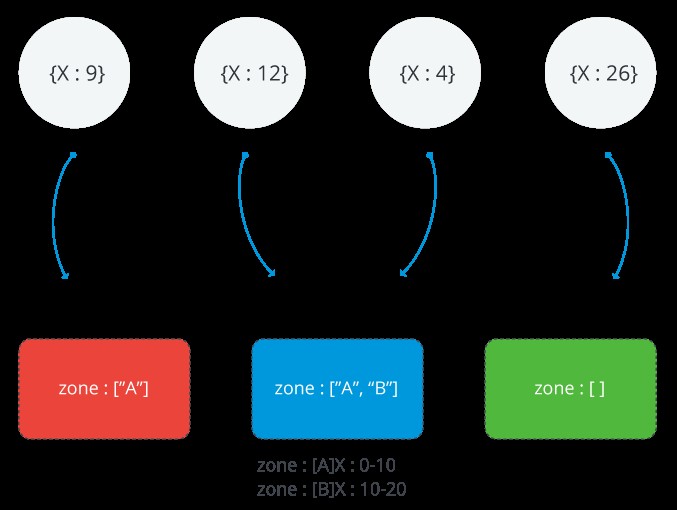
Intervallo di una zona MongoDB
Ciascuna zona copre uno o più intervalli di valori di chiave shard. Ogni intervallo coperto da una zona è sempre comprensivo del suo limite inferiore ed esclusivo del suo limite superiore.
RICORDA: Le zone non possono condividere intervalli e non possono avere intervalli sovrapposti.
Aggiunta di frammenti a una zona
Il metodo sh.addShardTag() viene utilizzato per aggiungere zone a uno shard. Un singolo shard può avere più zone e anche più shard possono avere la stessa zona. L'esempio seguente aggiunge la zona A a uno shard.
sh.addShardTag("shard0000", "A")Rimozione di frammenti in una zona
Per rimuovere una zona da uno shard, viene utilizzato il metodo sh.removeShardTag(). L'esempio seguente rimuove la zona A da uno shard.
sh.removeShardTag("shard0002", "A")Suggerimenti per le zone MongoDB
Mantieni i documenti semplici
MongoDB è un database privo di schemi. Ciò significa che non esiste uno schema predefinito per impostazione predefinita. Possiamo aggiungere uno schema predefinito nelle versioni più recenti, ma non è obbligatorio. Non sottovalutare le difficoltà che si verificano quando si lavora con documenti e array, poiché può diventare davvero difficile analizzare i dati nel processo lato applicazione/ETL. Inoltre, gli array possono compromettere le prestazioni di replica:per ogni modifica nell'array, tutti i valori dell'array vengono replicati.
Il miglior hardware non è sempre l'opzione migliore
L'uso di un buon hardware aiuta sicuramente per una buona prestazione. Ma cosa potrebbe succedere in un ambiente quando un'istanza di una grande macchina muore? La risposta è "failover".
Avere più macchine di piccole dimensioni (anziché una o due) in un ambiente distribuito può garantire che le interruzioni riguardino solo alcune parti dello shard con poca o nessuna percezione da parte dell'applicazione. Ma allo stesso tempo, più macchine implicano un'alta probabilità di avere un guasto. Considera questo compromesso quando progetti il tuo ambiente. Le scelte giuste influiscono sulle prestazioni.
Set da lavoro
Quanto è grande il set di lavoro? Di solito, un'applicazione non utilizza tutti i dati. Alcuni dati vengono aggiornati spesso, mentre altri no. Il tuo set di dati di lavoro si adatta alla RAM? Le prestazioni ottimali si ottengono quando tutto il set di dati di lavoro è nella RAM.



