La manutenzione è qualcosa che un team operativo non può evitare. I server devono stare al passo con il software, l'hardware e la tecnologia più recenti per garantire che i sistemi siano stabili e funzionino con il minor rischio possibile, sfruttando al contempo le funzionalità più recenti per migliorare le prestazioni complessive.
Indubbiamente, esiste un lungo elenco di attività di manutenzione che devono essere eseguite dagli amministratori di sistema, soprattutto quando si tratta di sistemi critici. Alcune delle attività devono essere eseguite a intervalli regolari, come giornalieri, settimanali, mensili e annuali. Alcuni devono essere fatti subito, con urgenza. Tuttavia, qualsiasi operazione di manutenzione non dovrebbe comportare un altro problema più grande e qualsiasi manutenzione deve essere gestita con la massima attenzione per evitare qualsiasi interruzione dell'attività.
Ottenere stato discutibile e falsi allarmi è comune mentre la manutenzione è in corso. Ciò è previsto perché durante il periodo di manutenzione, il server non funzionerà come dovrebbe fino al completamento dell'attività di manutenzione. ClusterControl, la piattaforma di gestione e monitoraggio all-inclusive per i tuoi database open source, può essere configurata per comprendere queste circostanze e semplificare le tue routine di manutenzione, senza sacrificare le funzionalità di monitoraggio e automazione che offre.
Modalità di manutenzione
ClusterControl ha introdotto la modalità di manutenzione nella versione 1.4.0, in cui è possibile mettere in manutenzione un singolo nodo, impedendo a ClusterControl di generare allarmi e inviare notifiche per la durata specificata. La modalità di manutenzione può essere configurata dall'interfaccia utente di ClusterControl e anche utilizzando lo strumento ClusterControl CLI chiamato "s9s". Dall'interfaccia utente, vai su Nodi -> scegli un nodo -> Azioni nodo -> Pianifica modalità di manutenzione :
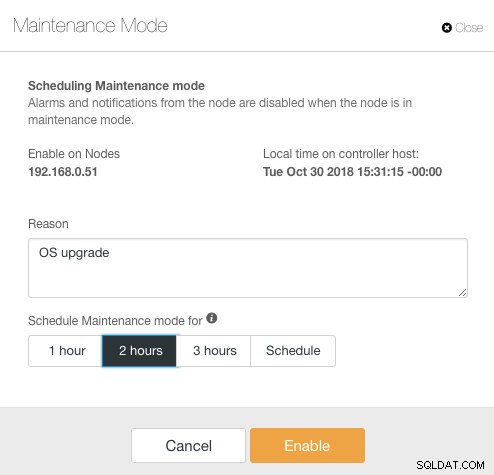
Qui è possibile impostare il periodo di manutenzione per un tempo predefinito o programmarlo di conseguenza. Puoi anche annotare il motivo della pianificazione dell'aggiornamento, utile ai fini del controllo. Dovresti vedere la seguente notifica quando la modalità di manutenzione è attiva:
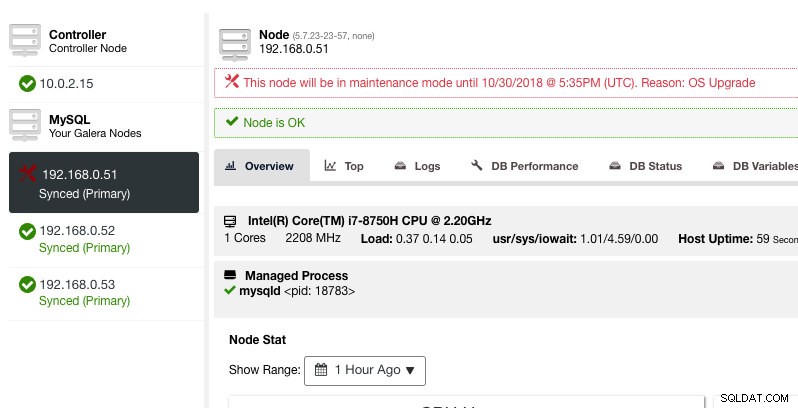
ClusterControl non degraderà il nodo, quindi lo stato del nodo rimane invariato a meno che non si esegua un'azione che modifichi lo stato. Gli allarmi e le notifiche per questo nodo verranno riattivati una volta terminato il periodo di manutenzione, oppure l'operatore lo disabilita esplicitamente andando su Azioni nodo -> Disattiva modalità manutenzione .
Tenere presente che se è abilitato il ripristino automatico del nodo, ClusterControl ripristinerà sempre un nodo indipendentemente dallo stato della modalità di manutenzione. Non dimenticare di disabilitare il ripristino del nodo per evitare che ClusterControl interferisca con le tue attività di manutenzione, questo può essere fatto dalla barra di riepilogo in alto.
La modalità di manutenzione può essere configurata anche tramite ClusterControl CLI o "s9s". È possibile utilizzare il comando "s9s maintenance" per elencare e manipolare i periodi di manutenzione. La seguente riga di comando pianifica una finestra di manutenzione di un'ora per il nodo 192.168.1.121 domani:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Per ulteriori dettagli ed esempi, vedere la documentazione di manutenzione di s9s.
Modalità di manutenzione a livello di cluster
Al momento della stesura di questo documento, la configurazione della modalità di manutenzione deve essere configurata per nodo gestito. Per la manutenzione a livello di cluster, è necessario ripetere il processo di pianificazione per ogni nodo gestito del cluster. Questo può non essere pratico se hai un numero elevato di nodi nel tuo cluster o se l'intervallo di manutenzione è molto breve tra due attività.
Fortunatamente, ClusterControl CLI (aka s9s) può essere utilizzato come soluzione alternativa per superare questa limitazione. È possibile utilizzare "s9s nodes" per elencare e manipolare i nodi gestiti in un cluster. Questo elenco può essere ripetuto per pianificare una modalità di manutenzione a livello di cluster in un dato momento utilizzando il comando "s9s maintenance".
Diamo un'occhiata a un esempio per capirlo meglio. Considera il seguente cluster Percona XtraDB a tre nodi che abbiamo:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Il cluster ha un totale di 4 nodi:3 nodi di database con un nodo ClusterControl. La prima colonna, STAT, mostra il ruolo e lo stato del nodo. Il primo carattere è il ruolo del nodo:"c" significa controller e "g" significa nodo del database Galera. Supponiamo di voler programmare solo i nodi del database per la manutenzione, possiamo filtrare l'output per ottenere il nome host o l'indirizzo IP in cui lo STAT riportato ha "g" all'inizio:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Con una semplice iterazione, possiamo quindi pianificare una finestra di manutenzione a livello di cluster per ogni nodo del cluster. Il comando seguente esegue un'iterazione della creazione della manutenzione in base a tutti gli indirizzi IP trovati nel cluster utilizzando un ciclo for, in cui prevediamo di iniziare l'operazione di manutenzione alla stessa ora domani e terminare un'ora dopo:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bDovresti vedere una stampa di 3 UUID, la stringa univoca che identifica ogni periodo di manutenzione. Possiamo quindi verificare con il seguente comando:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Dall'output di cui sopra, abbiamo ottenuto un elenco dei tempi di manutenzione programmati per ogni nodo del database. Durante il tempo programmato, ClusterControl non emetterà allarmi né invierà notifiche se rileva irregolarità al cluster.
Iterazione della modalità di manutenzione
Alcune routine di manutenzione devono essere eseguite a intervalli regolari, ad esempio backup, attività di pulizia e pulizia. Durante il periodo di manutenzione, ci aspetteremmo che il server si comporti diversamente. Tuttavia, qualsiasi errore del servizio, inaccessibilità temporanea o carico elevato causerebbe sicuramente il caos nel nostro sistema di monitoraggio. Per intervalli di manutenzione frequenti ea intervalli brevi, questo potrebbe rivelarsi molto fastidioso e saltare i falsi allarmi generati potrebbe darti un sonno migliore durante la notte.
Tuttavia, l'abilitazione della modalità di manutenzione può anche esporre il server a un rischio maggiore poiché il monitoraggio rigoroso viene ignorato per il periodo di tempo. Pertanto, è probabilmente una buona idea comprendere la natura dell'operazione di manutenzione che vorremmo eseguire prima di abilitare la modalità di manutenzione. Il seguente elenco di controllo dovrebbe aiutarci a determinare la nostra politica sulla modalità di manutenzione:
- Nodi interessati:quali nodi sono coinvolti nella manutenzione?
- Conseguenze - Cosa succede al nodo quando l'operazione di manutenzione è in corso? Sarà inaccessibile, caricato o riavviato?
- Durata:quanto tempo è necessario per completare l'operazione di manutenzione?
- Frequenza - Con quale frequenza deve essere eseguita l'operazione di manutenzione?
Mettiamolo in un caso d'uso. Si consideri un cluster Percona XtraDB a tre nodi con un nodo ClusterControl. Supponiamo che i nostri server siano tutti in esecuzione su macchine virtuali e che la policy di backup delle VM richieda il backup di tutte le VM ogni giorno a partire dall'01:00, un nodo alla volta. Durante questa operazione di backup, il nodo verrà bloccato per circa 10 minuti al massimo e il nodo che viene gestito e monitorato da ClusterControl sarà inaccessibile fino al termine del backup. Dal punto di vista del cluster Galera, questa operazione non riduce l'intero cluster poiché il cluster rimane in quorum e il componente primario non è interessato.
In base alla natura dell'attività di manutenzione, possiamo riassumerla come segue:
- Nodi interessati:tutti i nodi per l'ID cluster 1 (3 nodi database e 1 nodo ClusterControl).
- Conseguenza:la VM di cui è stato eseguito il backup sarà inaccessibile fino al completamento.
- Durata:il completamento di ciascuna operazione di backup della VM richiede dai 5 ai 10 minuti circa.
- Frequenza:l'esecuzione del backup della VM è pianificata ogni giorno, a partire dall'01:00 sul primo nodo.
Possiamo quindi elaborare un piano di esecuzione per programmare la nostra modalità di manutenzione:
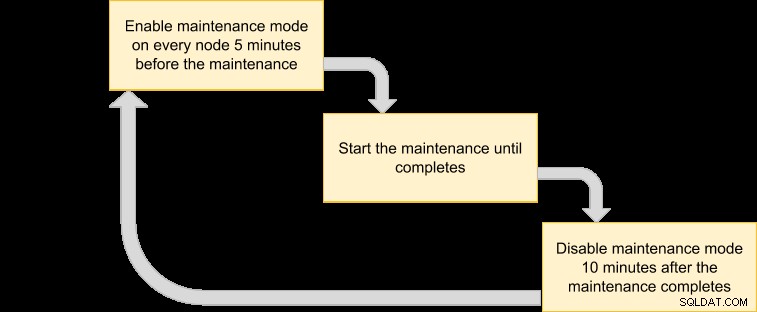
Poiché desideriamo che tutti i nodi del cluster vengano sottoposti a backup dal gestore VM, elenca semplicemente i nodi per l'ID cluster corrispondente:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53L'output di cui sopra può essere utilizzato per pianificare la manutenzione nell'intero cluster. Ad esempio, se esegui il comando seguente, ClusterControl attiverà la modalità di manutenzione per tutti i nodi con ID cluster 1 da ora fino ai prossimi 50 minuti:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneUsando il comando sopra, possiamo convertirlo in un file di esecuzione inserendolo in uno script. Crea un file:
$ vim /usr/local/bin/enable_maintenance_modeE aggiungi le seguenti righe:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneSalvalo e assicurati che il permesso del file sia eseguibile:
$ chmod 755 /usr/local/bin/enable_maintenance_modeQuindi usa cron per pianificare l'esecuzione dello script da 5 minuti all'01:00 ogni giorno, subito prima che l'operazione di backup della macchina virtuale inizi all'01:00:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeRicarica il demone cron per assicurarti che il nostro script sia in coda:
$ systemctl reload crond # or service crond reloadQuesto è tutto. Ora possiamo eseguire le nostre operazioni di manutenzione quotidiana senza essere disturbati da falsi allarmi e notifiche e-mail fino al completamento della manutenzione.
Funzione di manutenzione bonus - Salto del recupero del nodo
Con il ripristino automatico abilitato, ClusterControl è abbastanza intelligente da rilevare un errore del nodo e tenterà di ripristinare un nodo guasto dopo un periodo di grazia di 30 secondi, indipendentemente dallo stato della modalità di manutenzione. Sapevi che ClusterControl può essere configurato per ignorare deliberatamente il ripristino del nodo per un particolare nodo? Questo potrebbe essere molto utile quando devi eseguire una manutenzione urgente senza conoscere i tempi e l'esito della manutenzione.
Ad esempio, immagina che si sia verificata una corruzione del file system e che siano necessari il controllo e la riparazione del file system dopo un riavvio forzato. È difficile determinare in anticipo quanto tempo sarebbe necessario per completare questa operazione. Pertanto, possiamo semplicemente utilizzare un file flag per segnalare a ClusterControl di saltare il ripristino per il nodo.
Innanzitutto, aggiungi la seguente riga all'interno di /etc/cmon.d/cmon_X.cnf (dove X è l'ID del cluster) sul nodo ClusterControl:
node_recovery_lock_file=/root/do_not_recoverQuindi, riavvia il servizio cmon per caricare la modifica:
$ systemctl restart cmon # service cmon restartInfine, assicurati che il file specificato sia presente sul nodo che vogliamo ignorare per il ripristino di ClusterControl:
$ touch /root/do_not_recoverIndipendentemente dal ripristino automatico e dallo stato della modalità di manutenzione, ClusterControl ripristinerà il nodo solo quando questo file flag non esiste. L'amministratore è quindi responsabile della creazione e della rimozione del file nel nodo del database.
Questo è tutto, gente. Buona manutenzione!



