L'IT moderno deve disporre di uno schema dinamico non relazionale (ovvero nessun requisito per le query di istruzioni sui join) per fornire supporto per applicazioni Big Data/in tempo reale. I database NoSQL sono stati creati con l'idea di migliorare le prestazioni di elaborazione dei dati e di affrontare la capacità di scalabilità orizzontale per superare il carico di database distribuito utilizzando il concetto di più host, hanno vinto la domanda di nuova generazione per l'elaborazione dei dati.
Oltre a fornire il supporto essenziale per vari modelli di dati e linguaggi di scripting, MongoDB consente anche agli sviluppatori di avviare facilmente il processo.
Il database NoSQL apre le porte a...
- Protocolli basati su testo che utilizzano un linguaggio di scripting (REST e, JSON, BSON)
- Costo minimo per generare, archiviare e trasportare i dati
- Supporta enormi quantità di elaborazione dati.
- Prestazioni di scrittura aumentate
- Non è necessario eseguire la mappatura relazionale degli oggetti e il processo di normalizzazione
- Nessun controllo rigido con regole di integrità referenziale
- Ridurre i costi di manutenzione con gli amministratori di database
- Ridurre i costi di espansione
- Accesso rapido ai valori-chiave
- Avanzare il supporto per l'apprendimento automatico e l'intelligenza
Accettazione sul mercato MongoDB
Le moderne esigenze di Big Data Analytics e applicazioni moderne giocano un ruolo cruciale nella necessità di migliorare il ciclo di vita dell'elaborazione dei dati, senza aspettative di espansione hardware e aumento dei costi.
Se stai pianificando una nuova applicazione e vuoi scegliere un database, arrivare alla decisione giusta con molte opzioni di database sul mercato può essere un processo complicato.
La classifica di popolarità del motore DB mostra che MongoDB è al n.1 rispetto a Oracle NoSQL (che si è piazzato al n.74). La tendenza, tuttavia, indica che qualcosa sta cambiando. La necessità di molte espansioni convenienti va di pari passo con una modellazione dei dati molto più semplice e l'amministrazione sta trasformando il modo in cui gli sviluppatori vorrebbero considerare il meglio per i loro sistemi.
Secondo le informazioni sulla quota di mercato di Datanyze ad oggi, ci sono circa 289 siti Web in esecuzione su Oracle Nosql con una quota di mercato dell'11%, mentre MongoDB ha un sito Web completo di 12.185 con una quota di mercato di 4,66 %. Questi numeri impressionanti indicano che c'è un brillante futuro per MongoDB.
Modellazione dati NoSQL
La modellazione dei dati richiede la comprensione di...
- I tipi di dati attuali.
- Quali sono i tipi di dati che ti aspetti in futuro?
- In che modo la tua applicazione ottiene l'accesso ai dati richiesti dal sistema?
- In che modo la tua applicazione recupererà i dati richiesti per l'elaborazione?
La cosa eccitante per coloro che hanno sempre seguito il modo Oracle di creare schemi, quindi archiviare i dati, MongoDB consente di creare la raccolta insieme al documento. Ciò significa che la creazione di raccolte non è un must per esistere prima che avvenga la creazione del documento, rendendo MongoDB molto apprezzato per la sua flessibilità.
In Oracle NoSQL, tuttavia, devi prima creare la definizione della tabella, dopodiché puoi continuare a creare le righe.
La prossima cosa interessante è che MongoDB non implica regole rigide sull'implementazione di schemi e relazioni, il che ti dà la libertà per il miglioramento continuo del sistema senza temere molto sulla necessità di garantire una progettazione schematica rigorosa.
Esaminiamo alcuni dei confronti tra MongoDB e Oracle NoSQL.
Confronto dei concetti NoSQL in MongoDB e Oracle
Terminologia NoSQL
| MongoDB | Oracle NoSQL | Fatti |
| Collezione | Tabella/Vista | La raccolta/tabella funge da contenitore di archiviazione; sono simili ma non identici. |
| Documento | Riga | Per MongoDB, dati archiviati in una raccolta, sotto forma di documenti e campi. Per Oracle NoSQL, una tabella è una raccolta di righe, in cui ogni riga contiene un record di dati. Ogni riga della tabella è composta da campi chiave e dati, che vengono definiti al momento della creazione di una tabella. |
| Campo | Colonna | |
| Indice | Indice | Entrambi i database utilizzano un indice per migliorare la velocità di ricerca effettuata nel database. |
Document Store e Key Value Store
Oracle NoSQL fornisce un sistema di archiviazione che memorizza i valori indicizzati da una chiave; questo concetto è visto come il modello meno complesso poiché i set di dati sono costituiti da un valore-chiave indicizzato. I record organizzati utilizzando chiavi maggiori e chiavi minori.
La chiave maggiore può essere vista come il puntatore dell'oggetto e la chiave minore come i campi del record. La ricerca efficiente dei dati è resa possibile con l'uso della chiave come meccanismo per accedere ai dati proprio come una chiave primaria.
MongoDB estende le coppie chiave-valore. Ogni documento ha una chiave univoca, che serve allo scopo di recuperare il documento. I documenti sono noti come schemi dinamici, poiché le raccolte in un documento non devono avere lo stesso insieme di campi. Una raccolta può avere un campo comune con diversi tipi di dati. Questi attributi portano il modello di dati del documento a mappare direttamente per supportare i moderni linguaggi orientati agli oggetti.
| MongoDB | Oracle NoSQL |
| Archivio documenti Esempio:  | Store valori-chiave Esempio: 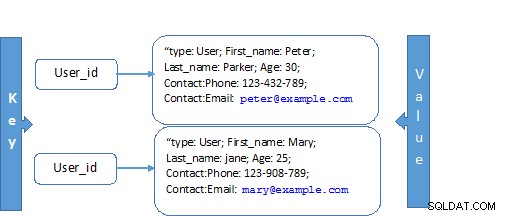 |
BSON e JSON
Oracle NoSQL utilizza JSON come formato di dati standard per la trasmissione (coppie dati + attributo-valore). D'altra parte MongoDB usa BSON.
| MongoDB | Oracle NoSQL |
| BSON | JSON |
| JSON binario - formato di dati binari - induce un'elaborazione più rapida | Notazione oggetto JavaScript - formato standard. Elaborazione molto più lenta rispetto a BSON. |
| Caratteristiche :
| Caratteristiche:
|
BSON non è in un testo leggibile, a differenza di JSON. BSON sta per serializzazione con codifica binaria di dati simili a JSON, utilizzati principalmente per l'archiviazione dei dati e un formato di trasferimento con MongoDB. Il formato dati BSON consiste in un elenco di elementi ordinati contenenti un nome di campo (stringa), un tipo e un valore. Per quanto riguarda i tipi di dati supportati da BSON, tutti i tipi di dati si trovano comunemente in JSON e include due tipi di dati aggiuntivi (Binary Data e Date). I dati binari o noti come BinData inferiori a 16 MB possono essere archiviati direttamente nei documenti MongoDB. Si dice che BSON stia consumando più spazio dei documenti di dati JSON.
Ci sono due ragioni per cui MongoDB consuma più spazio rispetto a Oracle NoSQL:
- MongoDB ha raggiunto l'obiettivo di essere in grado di attraversare velocemente, abilitare l'opzione per attraversare velocemente richiede che il documento BSON contenga metadati aggiuntivi (lunghezza della stringa e sottooggetti).
- Il design BSON può codificare e decodificare velocemente. Ad esempio, gli interi vengono memorizzati come interi a 32 (o 64) bit, per eliminare l'analisi da e verso il testo. Questo processo utilizza più spazio di JSON per numeri interi piccoli ma è molto più veloce da analizzare.
Definizione del modello di dati
Rendiconto di raccolta MongoDB
Crea una raccolta
db.createCollection("users")Creazione di una raccolta con un _id automatico
db.users.insert
( {
User_id: "U1",
First_name: "Mary"
Last_name : "Winslet",
Age : 15
Contact : {
Phone: "123-456-789"
Email: "example@sqldat.com"
}
access : {
Level:5,
Group:"dev"
}
})MongoDB consente di incorporare le informazioni correlate nello stesso record di database. Progettazione del modello di dati
Istruzione tabella Oracle NoSQL
Utilizzo della CLI SQL per configurare lo spazio dei nomi:
Create namespace newns1; Utilizzo dello spazio dei nomi per associare tabelle e tabelle figlio
news1:users
News1:users.accessCrea tabella con un'IDENTITÀ utilizzando:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_id String,
First_name String,
Last_name String,
Contact Record (Phone string,
Email string),
Primary key (idValue));Crea tabella utilizzando SQL JSON:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_profile JSON,
Primary Key (shard(idValue),User_id));
Righe per tabella Utente:digita JSON
{
"id":U1,
"User_profile" : {
"First_name":"Mary",
"Lastname":"Winslet",
"Age":15,
"Contact":{"Phone":"123-456-789",
"Email":"example@sqldat.com"
}
}Sulla base delle definizioni dei dati sopra, MongoDB consente diversi metodi per la creazione dello schema. La raccolta può essere definita in modo esplicito o durante il primo inserimento dei dati nel documento. Quando crei una raccolta, puoi definire un objectid. Objectid è la chiave primaria per i documenti MongoDB. Objectid è un tipo BSON binario a 12 byte che contiene 12 byte generati dai driver MongoDB e dal server utilizzando un algoritmo predefinito. MongoDB objectid è utile e serve allo scopo di ordinare il documento creato in una raccolta specifica.
Oracle NoSQL ha diversi modi per iniziare a definire le tabelle. Se si utilizza Oracle SQL CLI per impostazione predefinita, la creazione di una nuova tabella verrà inserita in sysdefault fino a quando non si deciderà di creare un nuovo spazio dei nomi per associarvi un insieme di nuove tabelle. L'esempio precedente mostra il nuovo spazio dei nomi "ns1" creato e la tabella utente è associata al nuovo spazio dei nomi.
Oltre a identificare la chiave primaria, Oracle NoSQL utilizza anche la colonna IDENTITY per incrementare automaticamente un valore ogni volta che aggiungi una riga. Il valore IDENTITY viene generato automaticamente e deve essere un tipo di dati Intero, lungo o numerico. In Oracle NoSQL, IDENTITY si associa a Sequence Generator in modo simile al concetto di objectid con MongoDB. Poiché Oracle NoSQL consente di utilizzare la chiave IDENTITY come chiave primaria. Se si considera la chiave IDENTITY come chiave primaria, è qui che è necessaria un'attenta considerazione in quanto potrebbe avere un impatto sull'inserimento dei dati e sul processo di aggiornamento.
La definizione del livello di raccolta/tabella di MongoDB e Oracle NoSQL mostra come le informazioni di "contatto" sono incorporate nella stessa struttura singola senza richiedere una definizione dello schema aggiuntiva. Il vantaggio dell'incorporamento di un set di dati è che non sarebbero necessarie ulteriori query per recuperare il set di dati incorporato.
Se stai cercando di mantenere il tuo sistema in una forma semplice, MongoDB offre l'opzione migliore per conservare i documenti di dati con meno complicazioni. Allo stesso tempo, MongoDB fornisce le capacità per fornire il modello di dati complesso esistente dallo schema relazionale utilizzando lo strumento di convalida dello schema.
Oracle NoSQL fornisce le capacità per utilizzare SQL, come il linguaggio di query con DDL e DML, che richiede molto meno sforzo per gli utenti che hanno una certa esperienza con l'uso dei sistemi di database delle relazioni.
La shell MongoDB utilizza Javascript e, se non ti senti a tuo agio con il linguaggio o con l'uso di mongo shell, la soluzione migliore per il processo è scegliere di utilizzare uno strumento IDE. I 5 migliori strumenti IDE di MongoDB nel 2020, come studio 3T, Robo 3T, NoSQLBooster, MongoDB Compass e Nucleon Database Master, saranno utili per aiutarti a creare e gestire query complesse con l'uso di funzionalità di aggregazione.
Prestazioni e disponibilità
Poiché il modello di struttura dati MongoDB utilizza documenti e raccolte, l'utilizzo del formato dati BSON per l'elaborazione di un'enorme quantità di dati diventa molto più veloce rispetto a Oracle NoSQL. Mentre alcuni considerano l'interrogazione dei dati con SQL un percorso più comodo per molti utenti, la capacità diventa un problema. Quando abbiamo un'enorme quantità di dati da supportare, la necessità di una maggiore velocità effettiva e seguita dall'uso di SQL per progettare query complesse, questi processi ci chiedono di rivedere la capacità del server e l'aumento dei costi nel tempo.
Sia MongoDB che Oracle NoSQL forniscono funzionalità di sharding e replica. Il partizionamento orizzontale è un processo che consente di distribuire il set di dati e il carico di elaborazione complessivo su più partizioni fisiche per aumentare la velocità di elaborazione (lettura/scrittura). L'implementazione di shard con Oracle richiede informazioni preliminari su come funzionano le chiavi di sharding. Il motivo alla base del processo di pianificazione preliminare è dovuto alla necessità di dover implementare la chiave shard a livello di avvio dello schema.
L'implementazione di shard con MongoDB ti offre lo spazio per lavorare prima sul tuo set di dati per identificare la potenziale chiave shard corretta in base ai modelli di query prima dell'implementazione. Poiché il processo di sharding include la replica dei dati, MongoDB ha anche una reputazione per la replica veloce dei dati. La replica si occupa della tolleranza agli errori di dover avere tutti i dati in un unico server.
Conclusione
Ciò che rende MongoDB preferito rispetto a Oracle NoSQL è che è in formato binario e le sue caratteristiche innate di leggero, attraversabile ed efficiente. Ciò consente di supportare le applicazioni moderne in evoluzione nell'area dell'apprendimento automatico e dell'intelligenza artificiale.
Le caratteristiche di MongoDB consentono agli sviluppatori di lavorare in modo molto più sicuro per creare applicazioni moderne più velocemente. Il modello di dati MongoDB consente l'elaborazione di enormi quantità di dati non strutturati con una velocità migliorata e ben congegnata rispetto a Oracle NoSQL. Oracle NoSQL vince quando si tratta di strumenti che ha da offrire e possibili opzioni per creare modelli di dati. Tuttavia, è essenziale assicurarsi che sviluppatori e designer possano imparare e adattarsi rapidamente alla tecnologia, cosa che non è il caso di Oracle NoSQL.



