La conservazione dei backup del database è una delle attività più importanti in qualsiasi ambiente di produzione. È il processo di copia dei tuoi dati in un altro posto per tenerli al sicuro. Questo può essere utile nel ripristino da situazioni di emergenza come il danneggiamento del database o un arresto anomalo irreparabile del database.
Oltre al ripristino, un backup può essere utilizzato anche per simulare un database di produzione per testare un'applicazione in un ambiente diverso o anche per eseguire il debug di qualcosa che non può essere eseguito sul database di produzione.
Esistono vari metodi di backup del database che puoi implementare, dal backup logico utilizzando strumenti incorporati nel database (es. mysqldump, mongodump, pg_dump) al backup fisico utilizzando strumenti di terze parti (es. xtrabackup, barman, pgbackrest, mongodb consistent backup).
Il metodo da utilizzare è spesso determinato da come si desidera ripristinare. Ad esempio, supponi di aver perso una tabella o una raccolta per errore. Per quanto improbabile possa sembrare, succede. Quindi il modo più veloce per eseguire il ripristino sarebbe ripristinare solo quella tabella o raccolta, invece di dover ripristinare un intero database.
Backup e ripristino in Mongodb
Mongodump e mongorestore sono lo strumento per il backup logico utilizzato in MongoDB, è una specie di mysqldump in MySQL o pg_dump in PostgreSQL. L'utilità mongodump e mongorestore verrà inclusa quando si installa MongoDB e scarica i dati in formato BSON. Mongodump viene utilizzato per eseguire il backup logico del database in file di dump, mentre mongorestore viene utilizzato per l'operazione di ripristino.
I comandi mongodump e mongorestore sono facili da usare, sebbene ci siano molte opzioni.
Come possiamo vedere di seguito, puoi eseguire il backup di database o raccolte specifici. Puoi persino scattare un'istantanea di un punto nel tempo includendo l'oplog.
example@sqldat.com:~# mongodump --help
Usage:
mongodump <options>
Export the content of a running server into .bson files.
Specify a database with -d and a collection with -c to only dump that database or collection.
See https://docs.mongodb.org/manual/reference/program/mongodump/ for more information.
general options:
--help print usage
--version print the tool version and exit
verbosity options:
-v, --verbose=<level> more detailed log output (include multiple times for more verbosity, e.g. -vvvvv, or specify a numeric value, e.g. --verbose=N)
--quiet hide all log output
connection options:
-h, --host=<hostname> mongodb host to connect to (setname/host1,host2 for replica sets)
--port=<port> server port (can also use --host hostname:port)
kerberos options:
--gssapiServiceName=<service-name> service name to use when authenticating using GSSAPI/Kerberos ('mongodb' by default)
--gssapiHostName=<host-name> hostname to use when authenticating using GSSAPI/Kerberos (remote server's address by default)
ssl options:
--ssl connect to a mongod or mongos that has ssl enabled
--sslCAFile=<filename> the .pem file containing the root certificate chain from the certificate authority
--sslPEMKeyFile=<filename> the .pem file containing the certificate and key
--sslPEMKeyPassword=<password> the password to decrypt the sslPEMKeyFile, if necessary
--sslCRLFile=<filename> the .pem file containing the certificate revocation list
--sslAllowInvalidCertificates bypass the validation for server certificates
--sslAllowInvalidHostnames bypass the validation for server name
--sslFIPSMode use FIPS mode of the installed openssl library
authentication options:
-u, --username=<username> username for authentication
-p, --password=<password> password for authentication
--authenticationDatabase=<database-name> database that holds the user's credentials
--authenticationMechanism=<mechanism> authentication mechanism to use
namespace options:
-d, --db=<database-name> database to use
-c, --collection=<collection-name> collection to use
uri options:
--uri=mongodb-uri mongodb uri connection string
query options:
-q, --query= query filter, as a JSON string, e.g., '{x:{$gt:1}}'
--queryFile= path to a file containing a query filter (JSON)
--readPreference=<string>|<json> specify either a preference name or a preference json object
--forceTableScan force a table scan
output options:
-o, --out=<directory-path> output directory, or '-' for stdout (defaults to 'dump')
--gzip compress archive our collection output with Gzip
--repair try to recover documents from damaged data files (not supported by all storage engines)
--oplog use oplog for taking a point-in-time snapshot
--archive=<file-path> dump as an archive to the specified path. If flag is specified without a value, archive is written to stdout
--dumpDbUsersAndRoles dump user and role definitions for the specified database
--excludeCollection=<collection-name> collection to exclude from the dump (may be specified multiple times to exclude additional collections)
--excludeCollectionsWithPrefix=<collection-prefix> exclude all collections from the dump that have the given prefix (may be specified multiple times to exclude additional prefixes)
-j, --numParallelCollections= number of collections to dump in parallel (4 by default) (default: 4)
--viewsAsCollections dump views as normal collections with their produced data, omitting standard collectionsCi sono molte opzioni nel comando mongorestore, l'opzione obbligatoria è correlata alle opzioni di connessione come host, porta e autenticazione. Esistono altri parametri, come -j utilizzato per ripristinare le raccolte in parallelo, -c o --collection viene utilizzato per una raccolta specifica e -d o --db viene utilizzato per definire un database specifico. L'elenco delle opzioni del parametro mongorestore può essere visualizzato utilizzando la guida:
example@sqldat.com:~# mongorestore --help
Usage:
mongorestore <options> <directory or file to restore>
Restore backups generated with mongodump to a running server.
Specify a database with -d to restore a single database from the target directory,
or use -d and -c to restore a single collection from a single .bson file.
See https://docs.mongodb.org/manual/reference/program/mongorestore/ for more information.
general options:
--help print usage
--version print the tool version and exit
verbosity options:
-v, --verbose=<level> more detailed log output (include multiple times for more verbosity, e.g. -vvvvv, or specify a numeric value, e.g. --verbose=N)
--quiet hide all log output
connection options:
-h, --host=<hostname> mongodb host to connect to (setname/host1,host2 for replica sets)
--port=<port> server port (can also use --host hostname:port)
kerberos options:
--gssapiServiceName=<service-name> service name to use when authenticating using GSSAPI/Kerberos ('mongodb' by default)
--gssapiHostName=<host-name> hostname to use when authenticating using GSSAPI/Kerberos (remote server's address by default)
ssl options:
--ssl connect to a mongod or mongos that has ssl enabled
--sslCAFile=<filename> the .pem file containing the root certificate chain from the certificate authority
--sslPEMKeyFile=<filename> the .pem file containing the certificate and key
--sslPEMKeyPassword=<password> the password to decrypt the sslPEMKeyFile, if necessary
--sslCRLFile=<filename> the .pem file containing the certificate revocation list
--sslAllowInvalidCertificates bypass the validation for server certificates
--sslAllowInvalidHostnames bypass the validation for server name
--sslFIPSMode use FIPS mode of the installed openssl library
authentication options:
-u, --username=<username> username for authentication
-p, --password=<password> password for authentication
--authenticationDatabase=<database-name> database that holds the user's credentials
--authenticationMechanism=<mechanism> authentication mechanism to use
uri options:
--uri=mongodb-uri mongodb uri connection string
namespace options:
-d, --db=<database-name> database to use when restoring from a BSON file
-c, --collection=<collection-name> collection to use when restoring from a BSON file
--excludeCollection=<collection-name> DEPRECATED; collection to skip over during restore (may be specified multiple times to exclude additional collections)
--excludeCollectionsWithPrefix=<collection-prefix> DEPRECATED; collections to skip over during restore that have the given prefix (may be specified multiple times to exclude additional prefixes)
--nsExclude=<namespace-pattern> exclude matching namespaces
--nsInclude=<namespace-pattern> include matching namespaces
--nsFrom=<namespace-pattern> rename matching namespaces, must have matching nsTo
--nsTo=<namespace-pattern> rename matched namespaces, must have matching nsFrom
input options:
--objcheck validate all objects before inserting
--oplogReplay replay oplog for point-in-time restore
--oplogLimit=<seconds>[:ordinal] only include oplog entries before the provided Timestamp
--oplogFile=<filename> oplog file to use for replay of oplog
--archive=<filename> restore dump from the specified archive file. If flag is specified without a value, archive is read from stdin
--restoreDbUsersAndRoles restore user and role definitions for the given database
--dir=<directory-name> input directory, use '-' for stdin
--gzip decompress gzipped input
restore options:
--drop drop each collection before import
--dryRun view summary without importing anything. recommended with verbosity
--writeConcern=<write-concern> write concern options e.g. --writeConcern majority, --writeConcern '{w: 3, wtimeout: 500, fsync: true, j: true}'
--noIndexRestore don't restore indexes
--noOptionsRestore don't restore collection options
--keepIndexVersion don't update index version
--maintainInsertionOrder preserve order of documents during restoration
-j, --numParallelCollections= number of collections to restore in parallel (4 by default) (default: 4)
--numInsertionWorkersPerCollection= number of insert operations to run concurrently per collection (1 by default) (default: 1)
--stopOnError stop restoring if an error is encountered on insert (off by default)
--bypassDocumentValidation bypass document validation
--preserveUUID preserve original collection UUIDs (off by default, requires drop)Il ripristino di raccolte specifiche in MongoDB può essere eseguito utilizzando la raccolta di parametri in mongorestore. Supponiamo che tu abbia un database degli ordini, all'interno del database degli ordini ci sono alcune raccolte come mostrato di seguito:
my_mongodb_0:PRIMARY> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
orders 0.000GB
my_mongodb_0:PRIMARY> use orders;
my_mongodb_0:PRIMARY> show collections;
order_details
orders
stockAbbiamo già programmato un backup per il database degli ordini e vogliamo ripristinare la raccolta stock in un nuovo database order_new nello stesso server. Se desideri utilizzare l'opzione --collection, devi passare il nome della raccolta come parametro di mongorestore oppure puoi utilizzare l'opzione --nsInclude={db}.{collection} se non hai specificato il percorso del file della raccolta .
example@sqldat.com:~/dump/orders# mongorestore -umongoadmin --authenticationDatabase admin --db order_new --collection stock /root/dump/orders/stock.bson
Enter password:
2020-03-09T04:06:29.100+0000 checking for collection data in /root/dump/orders/stock.bson
2020-03-09T04:06:29.110+0000 reading metadata for order_new.stock from /root/dump/orders/stock.metadata.json
2020-03-09T04:06:29.134+0000 restoring order_new.stock from /root/dump/orders/stock.bson
2020-03-09T04:06:29.202+0000 no indexes to restore
2020-03-09T04:06:29.203+0000 finished restoring order_new.stock (1 document)
2020-03-09T04:06:29.203+0000 donePuoi controllare la collezione nel database order_new come mostrato di seguito:
my_mongodb_0:PRIMARY> use order_new;
switched to db order_new
my_mongodb_0:PRIMARY> show collections;
stockCome possiamo ripristinare utilizzando mongodump in ClusterControl
Il ripristino di un dump di backup tramite ClusterControl è semplice, sono sufficienti 2 passaggi per ripristinare il backup. Ci saranno molti file di backup nell'elenco se hai abilitato la pianificazione del backup, ci sono alcune informazioni sui backup che possono essere molto utili. Ad esempio, lo stato del backup che indica se il backup è stato completato/non riuscito, il metodo di backup eseguito, l'elenco dei database e la dimensione del dump. I passaggi per ripristinare i dati MongoDB tramite ClusterControl sono i seguenti:
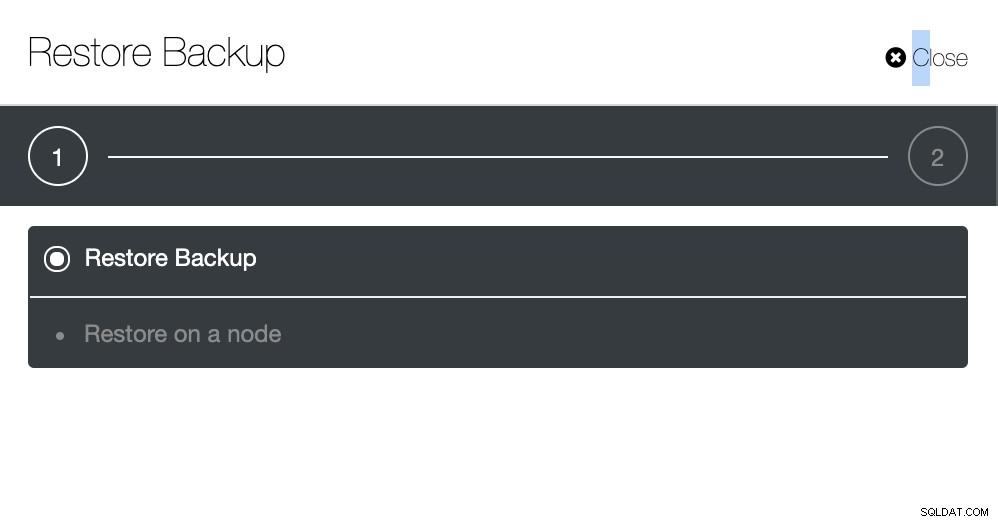
Fase uno
Segui le istruzioni per ripristinare il backup su un nodo come mostrato di seguito...
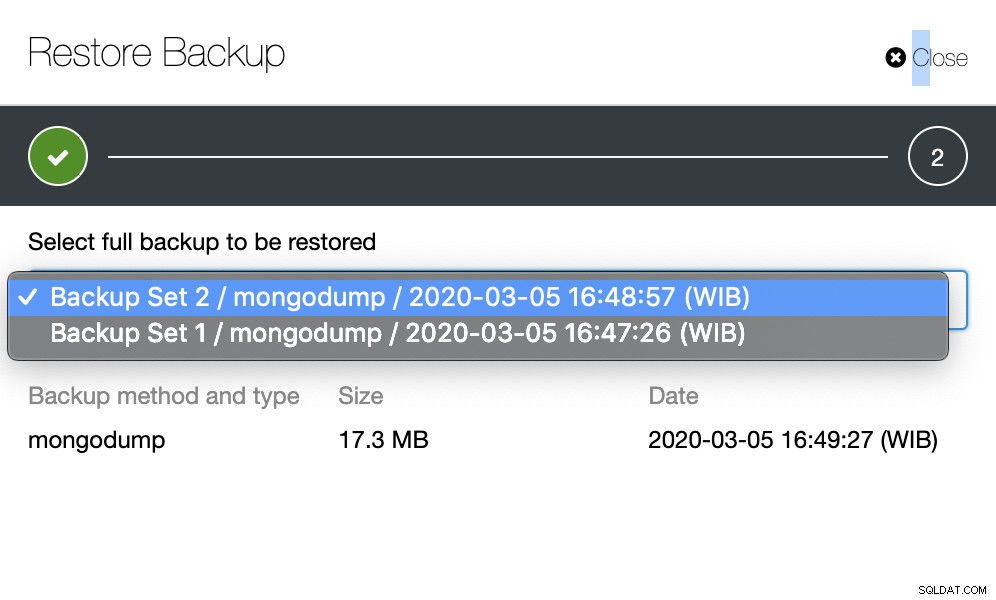
Fase due
Devi scegliere quale backup deve essere ripristinato.
Fase tre
Rivedi il riepilogo...