MongoDB è un database NoSQL che supporta un'ampia varietà di origini di set di dati di input. È in grado di archiviare i dati in documenti flessibili simili a JSON, il che significa che i campi o i metadati possono variare da documento a documento e la struttura dei dati può essere modificata nel tempo. Il modello del documento semplifica l'utilizzo dei dati mappando gli oggetti nel codice dell'applicazione. MongoDB è anche noto come database distribuito al centro, quindi disponibilità elevata, ridimensionamento orizzontale e distribuzione geografica sono integrati e facili da usare. Viene fornito con la possibilità di modificare senza problemi i parametri per l'addestramento del modello. I data scientist possono facilmente unire la strutturazione dei dati con questa generazione di modelli.
Cos'è l'apprendimento automatico?
Il machine learning è la scienza che consente ai computer di imparare e agire come fanno gli umani e di migliorare il loro apprendimento nel tempo in modo autonomo. Il processo di apprendimento inizia con osservazioni o dati, come esempi, esperienza diretta o istruzioni, al fine di cercare modelli nei dati e prendere decisioni migliori in futuro sulla base degli esempi che forniamo. L'obiettivo principale è consentire ai computer di apprendere automaticamente senza intervento o assistenza umana e regolare le azioni di conseguenza.
Un ricco modello di programmazione e query
MongoDB offre sia driver nativi che connettori certificati per sviluppatori e data scientist che creano modelli di machine learning con i dati di MongoDB. PyMongo è un'ottima libreria per incorporare la sintassi MongoDB nel codice Python. Possiamo importare tutte le funzioni e i metodi di MongoDB per usarli nel nostro codice di machine learning. È un'ottima tecnica per ottenere funzionalità multilingua in un unico codice. L'ulteriore vantaggio è che puoi utilizzare le funzionalità essenziali di quei linguaggi di programmazione per creare un'applicazione efficiente.
Il linguaggio di query MongoDB con indici secondari avanzati consente agli sviluppatori di creare applicazioni in grado di eseguire query e analizzare i dati in più dimensioni. È possibile accedere ai dati tramite chiavi singole, intervalli, ricerche di testo, grafici e query geospaziali tramite aggregazioni complesse e lavori MapReduce, restituendo risposte in millisecondi.
Per parallelizzare l'elaborazione dei dati in un cluster di database distribuito, MongoDB fornisce la pipeline di aggregazione e MapReduce. La pipeline di aggregazione MongoDB è modellata sul concetto di pipeline di elaborazione dati. I documenti entrano in una pipeline multifase che trasforma i documenti in un risultato aggregato utilizzando operazioni native eseguite all'interno di MongoDB. Le fasi più basilari della pipeline forniscono filtri che funzionano come query e trasformazioni di documenti che modificano la forma del documento di output. Altre operazioni della pipeline forniscono strumenti per raggruppare e ordinare i documenti in base a campi specifici, nonché strumenti per aggregare il contenuto degli array, inclusi gli array di documenti. Inoltre, le fasi pipseline possono utilizzare gli operatori per attività quali il calcolo delle deviazioni medie o standard tra raccolte di documenti e la manipolazione di stringhe. MongoDB fornisce anche operazioni MapReduce native all'interno del database, utilizzando funzioni JavaScript personalizzate per eseguire la mappa e ridurre le fasi.
Oltre al suo framework di query nativo, MongoDB offre anche un connettore ad alte prestazioni per Apache Spark. Il connettore espone tutte le librerie di Spark, inclusi Python, R, Scala e Java. I dati MongoDB vengono materializzati come DataFrame e Dataset per l'analisi con API di machine learning, grafici, streaming e SQL.
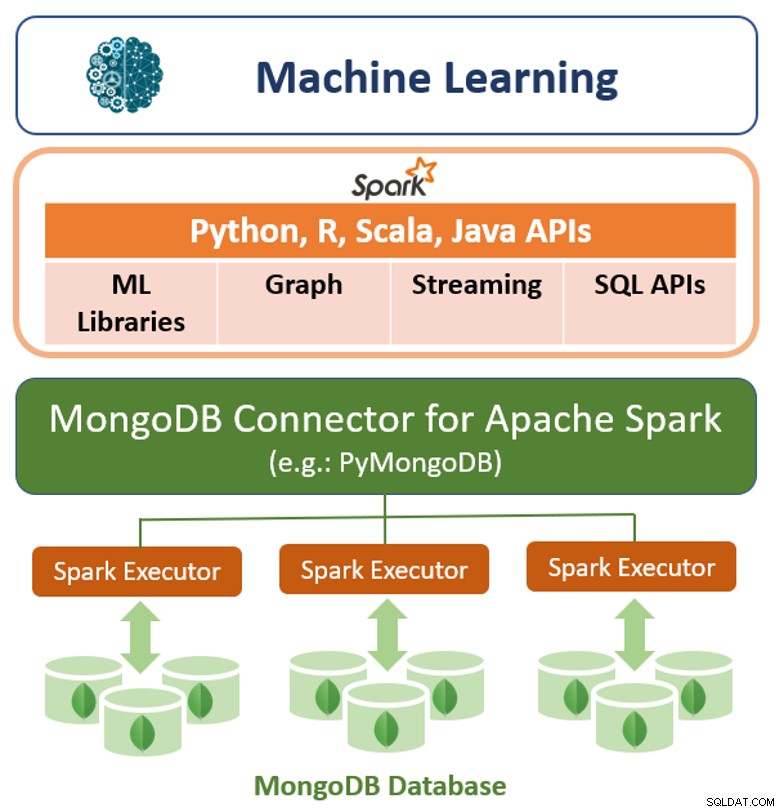
Il connettore MongoDB per Apache Spark può sfruttare la pipeline di aggregazione di MongoDB e il secondario indici per estrarre, filtrare ed elaborare solo l'intervallo di dati di cui ha bisogno, ad esempio, analizzando tutti i clienti situati in un'area geografica specifica. Questo è molto diverso dai semplici datastore NoSQL che non supportano né indici secondari né aggregazioni nel database. In questi casi, Spark dovrebbe estrarre tutti i dati in base a una semplice chiave primaria, anche se per il processo Spark è richiesto solo un sottoinsieme di tali dati. Ciò significa più sovraccarico di elaborazione, più hardware e più tempo per ottenere informazioni dettagliate per data scientist e ingegneri. Per massimizzare le prestazioni su set di dati distribuiti di grandi dimensioni, il connettore MongoDB per Apache Spark può co-localizzare set di dati distribuiti resilienti (RDD) con il nodo MongoDB di origine, riducendo così al minimo lo spostamento dei dati nel cluster e la latenza.
Prestazioni, scalabilità e ridondanza
Il tempo di addestramento del modello può essere ridotto costruendo la piattaforma di machine learning su un livello di database scalabile e performante. MongoDB offre una serie di innovazioni per massimizzare il throughput e ridurre al minimo la latenza dei carichi di lavoro di machine learning:
- WiredTiger è noto come il motore di archiviazione predefinito per MongoDB, sviluppato dagli architetti di Berkeley DB, il software di gestione dei dati embedded più diffuso al mondo. WiredTiger scala su moderne architetture multi-core. Utilizzando una varietà di tecniche di programmazione come indicatori di pericolo, algoritmi senza blocco, aggancio rapido e passaggio di messaggi, WiredTiger massimizza il lavoro di calcolo per core della CPU e ciclo di clock. Per ridurre al minimo il sovraccarico su disco e l'I/O, WiredTiger utilizza formati di file compatti e compressione dello storage.
- Per le applicazioni di machine learning più sensibili alla latenza, MongoDB può essere configurato con il motore di archiviazione In-Memory. Basato su WiredTiger, questo motore di archiviazione offre agli utenti i vantaggi dell'elaborazione in-memory, senza rinunciare alla ricca flessibilità delle query, all'analisi in tempo reale e alla capacità scalabile offerte dai database tradizionali basati su disco.
- Per parallelizzare l'addestramento del modello e scalare i set di dati di input oltre un singolo nodo, MongoDB utilizza una tecnica chiamata sharding, che distribuisce elaborazione e dati tra cluster di hardware di base. Lo sharding di MongoDB è completamente elastico e ribilancia automaticamente i dati nel cluster man mano che il set di dati di input cresce o quando i nodi vengono aggiunti e rimossi.
- All'interno di un cluster MongoDB, i dati di ogni shard vengono distribuiti automaticamente a più repliche ospitate su nodi separati. I set di repliche MongoDB forniscono ridondanza per recuperare i dati di addestramento in caso di errore, riducendo il sovraccarico del checkpoint.
Coerenza sintonizzabile di MongoDB
MongoDB è fortemente coerente per impostazione predefinita, consentendo alle applicazioni di apprendimento automatico di leggere immediatamente ciò che è stato scritto nel database, evitando così la complessità dello sviluppatore imposta da sistemi eventualmente coerenti. Una forte coerenza fornirà i risultati più accurati per gli algoritmi di apprendimento automatico; tuttavia, in alcuni scenari è accettabile scambiare la coerenza con obiettivi di prestazioni specifici distribuendo le query su un cluster di membri del set di repliche secondarie MongoDB.
Modello di dati flessibile in MongoDB
Il modello di dati dei documenti di MongoDB consente a sviluppatori e data scientist di archiviare e aggregare facilmente i dati di qualsiasi forma di struttura all'interno del database, senza rinunciare a sofisticate regole di convalida per governare la qualità dei dati. Lo schema può essere modificato dinamicamente senza tempi di inattività dell'applicazione o del database derivanti da costose modifiche allo schema o riprogettazioni sostenute dai sistemi di database relazionali.
Salvare i modelli in un database e caricarli, usando python, è anche un metodo facile e molto richiesto. Anche la scelta di MongoDB è un vantaggio in quanto è un database di documenti open source e anche un database NoSQL leader. MongoDB funge anche da connettore per il framework distribuito Apache Spark.
La natura dinamica di MongoDB
La natura dinamica di MongoDB ne consente l'utilizzo nelle attività di manipolazione del database nello sviluppo di applicazioni di Machine Learning. È un modo molto efficiente e semplice per eseguire un'analisi di set di dati e database. L'output dell'analisi può essere utilizzato nei modelli di apprendimento automatico. È stato raccomandato che gli analisti di dati e i programmatori di Machine Learning acquisiscano padronanza in MongoDB e lo applichino in molte applicazioni diverse. Il framework di aggregazione di MongoDB viene utilizzato per il flusso di lavoro della scienza dei dati per eseguire l'analisi dei dati per numerose applicazioni.
Conclusione
MongoDB offre diverse funzionalità come:modello di dati flessibile, programmazione avanzata, modello di dati, modello di query e la sua coerenza sintonizzabile che rendono l'addestramento e l'utilizzo di algoritmi di apprendimento automatico molto più semplici rispetto ai tradizionali database relazionali. L'esecuzione di MongoDB come database di back-end consentirà l'archiviazione e l'arricchimento dei dati di apprendimento automatico consentendo persistenza e maggiore efficienza.



