Più JOINS in una singola query
Più JOIN sono normalmente associati a più raccolte, ma devi avere una conoscenza di base di come funziona INNER JOIN (vedi i miei post precedenti su questo argomento). Oltre alle nostre due collezioni che avevamo prima; unità e studenti, aggiungiamo una terza collezione ed etichettiamola come sport. Completa la raccolta sportiva con i dati seguenti:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Vorremmo, ad esempio, restituire tutti i dati per uno studente con il valore del campo _id uguale a 1. Normalmente, scriviamo una query per recuperare il valore del campo _id dalla raccolta degli studenti, quindi utilizziamo il valore restituito per interrogare dati nelle altre due raccolte. Di conseguenza, questa non sarà l'opzione migliore soprattutto se è coinvolta una grande serie di documenti. Un approccio migliore sarebbe utilizzare la funzione SQL del programma Studio3T. Possiamo interrogare il nostro MongoDB con il normale concetto SQL e quindi provare a ottimizzare il codice della shell Mongo risultante per soddisfare le nostre specifiche. Ad esempio, prendiamo tutti i dati con _id uguale a 1 da tutte le raccolte:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Il documento risultante sarà:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Dalla scheda Codice query, il codice MongoDB corrispondente sarà:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);Esaminando il documento restituito, personalmente non sono molto soddisfatto della struttura dei dati, in particolare dei documenti incorporati. Come puoi vedere, ci sono _id campi restituiti e per le unità potrebbe non essere necessario che il campo dei voti sia incorporato all'interno delle unità.
Vorremmo avere un campo unità con unità incorporate e non altri campi. Questo ci porta alla parte della melodia grossolana. Come nei post precedenti, copia il codice utilizzando l'icona di copia fornita e vai al pannello di aggregazione, incolla il contenuto utilizzando l'icona di incolla.
Per prima cosa, l'operatore $match dovrebbe essere il primo stadio, quindi spostalo nella prima posizione e fai qualcosa del genere:
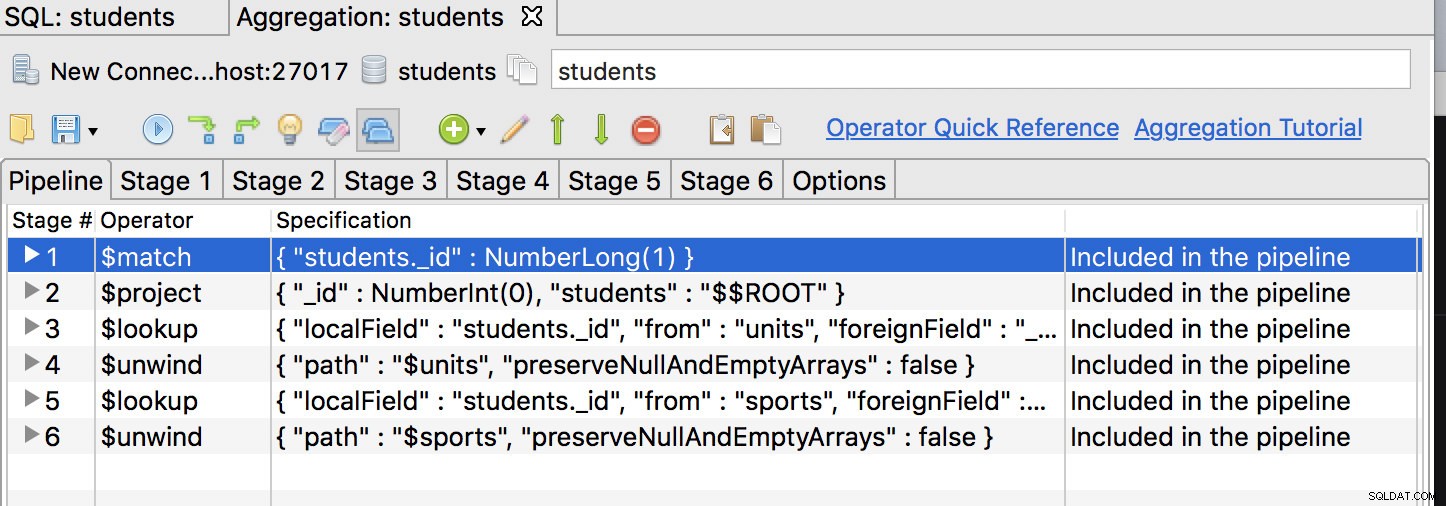
Fai clic sulla scheda della prima fase e modifica la query in:
{
"_id" : NumberLong(1)
}Abbiamo quindi bisogno di modificare ulteriormente la query per rimuovere molte fasi di incorporamento dei nostri dati. Per fare ciò, aggiungiamo nuovi campi per acquisire i dati per i campi che vogliamo eliminare, ad esempio:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Come puoi vedere, nel processo di fine tuning abbiamo introdotto nuove unità di campo che sovrascriveranno il contenuto della precedente pipeline di aggregazione con i voti come campo incorporato. Inoltre, abbiamo creato un campo _id per indicare che i dati erano in relazione a qualsiasi documento nelle raccolte con lo stesso valore. L'ultima fase del $progetto consiste nel rimuovere il campo _id nel documento sportivo in modo da poter disporre di dati ben presentati come di seguito.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Possiamo anche limitare i campi da restituire dal punto di vista SQL. Ad esempio possiamo restituire il nome dello studente, le unità che questo studente sta facendo e il numero di tornei giocati utilizzando più JOINS con il codice seguente:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Questo non ci dà il risultato più appropriato. Quindi, come al solito, copialo e incollalo nel riquadro di aggregazione. Perfezioniamo il codice qui sotto per ottenere il risultato appropriato.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Questo risultato di aggregazione del concetto SQL JOIN ci fornisce una struttura di dati ordinata e presentabile mostrata di seguito.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Abbastanza semplice, vero? I dati sono abbastanza presentabili come se fossero archiviati in un'unica raccolta come un unico documento.
UNIONE ESTERNA SINISTRA
Il LEFT OUTER JOIN viene normalmente utilizzato per mostrare documenti non conformi alla relazione più ritratta. Il set risultante di un join LEFT OUTER contiene tutte le righe di entrambe le raccolte che soddisfano i criteri della clausola WHERE, come un set di risultati INNER JOIN. Inoltre, tutti i documenti della raccolta di sinistra che non hanno documenti corrispondenti nella raccolta di destra verranno inclusi nel set di risultati. I campi selezionati dalla tabella a destra restituiranno valori NULL. Tuttavia, tutti i documenti nella raccolta di destra, che non hanno criteri di corrispondenza dalla raccolta di sinistra, non vengono restituiti.
Dai un'occhiata a queste due collezioni:
studenti
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Unità
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Nella raccolta degli studenti non abbiamo il valore del campo _id impostato su 3 ma nella raccolta delle unità abbiamo. Allo stesso modo, nella raccolta di unità non è presente alcun valore di campo _id 4. Se utilizziamo la raccolta studenti come opzione a sinistra nell'approccio UNISCITI con la query seguente:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idCon questo codice otterremo il seguente risultato:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Il secondo documento non ha il campo delle unità perché non c'era alcun documento corrispondente nella raccolta delle unità. Per questa query SQL, il codice Mongo corrispondente sarà
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Ovviamente abbiamo appreso la messa a punto, quindi puoi andare avanti e ristrutturare la pipeline di aggregazione per adattarla al risultato finale che desideri. SQL è uno strumento molto potente per quanto riguarda la gestione del database. È un argomento ampio di per sé, puoi anche provare a utilizzare le clausole IN e GROUP BY per ottenere il codice corrispondente per MongoDB e vedere come funziona.
Conclusione
Abituarsi a una nuova tecnologia (database) oltre a quella con cui si è abituati a lavorare può richiedere molto tempo. I database relazionali sono ancora più comuni di quelli non relazionali. Tuttavia, con l'introduzione di MongoDB, le cose sono cambiate e le persone vorrebbero impararlo il più velocemente possibile grazie alle potenti prestazioni associate.
Imparare MongoDB da zero può essere un po' noioso, ma possiamo usare la conoscenza di SQL per manipolare i dati in MongoDB, ottenere il relativo codice MongoDB e perfezionarlo per ottenere i risultati più appropriati. Uno degli strumenti disponibili per migliorare questo è Studio 3T. Offre due importanti funzionalità che facilitano il funzionamento di dati complessi, ovvero:la funzionalità di query SQL e l'editor di aggregazione. Le query di fine tuning non solo ti garantiranno il miglior risultato, ma miglioreranno anche le prestazioni in termini di risparmio di tempo.



