JOIN è una delle caratteristiche distintive chiave tra i database SQL e NoSQL. Nei database SQL, possiamo eseguire un JOIN tra due tabelle all'interno dello stesso database o di database diversi. Tuttavia, questo non è il caso di MongoDB in quanto consente operazioni di JOIN tra due raccolte nello stesso database.
Il modo in cui i dati sono presentati in MongoDB rende quasi impossibile collegarli da una raccolta all'altra tranne quando si utilizzano le funzioni di query di script di base. MongoDB o denormalizza i dati memorizzando gli elementi correlati in un documento separato o mette in relazione i dati in un altro documento separato.
È possibile correlare questi dati utilizzando riferimenti manuali come il campo _id di un documento salvato in un altro documento come riferimento. Tuttavia, è necessario eseguire più query per recuperare alcuni dati richiesti, rendendo il processo un po' noioso.
Decidiamo quindi di utilizzare il concetto JOIN che facilita la relazione dei dati. L'operazione JOIN in MongoDB si ottiene tramite l'uso dell'operatore $lookup, introdotto nella versione 3.2.
$operatore di ricerca
L'idea principale alla base del concetto JOIN è ottenere la correlazione tra i dati di una raccolta e un'altra. La sintassi di base dell'operatore $lookup è:
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}Per quanto riguarda la conoscenza SQL, sappiamo sempre che il risultato di un'operazione JOIN è una riga separata che collega tutti i campi della tabella locale ed esterna. Per MongoDB, questo è un caso diverso in quanto i documenti dei risultati vengono aggiunti come un array di documenti di raccolta locali. Ad esempio, abbiamo due raccolte; 'studenti' e 'unità'
studenti
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 3,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Unità
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Possiamo recuperare le unità degli studenti con i rispettivi voti utilizzando l'operatore $lookup con l'approccio JOIN .i.e
db.getCollection('students').aggregate([{
$lookup:
{
from: "units",
localField: "_id",
foreignField : "_id",
as: "studentUnits"
}
}])Che ci darà i risultati di seguito:
{"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5,
"studentUnits" : [{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}]}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14,"grade" : "B","score" : 7.5,
"studentUnits" : [{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}]}
{"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5,
"studentUnits" : [{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}]}Come accennato in precedenza, se eseguiamo un JOIN utilizzando il concetto SQL, verremo restituiti con documenti separati nella piattaforma Studio3T .i.e
SELECT *
FROM students
INNER JOIN units
ON students._id = units._idÈ l'equivalente di
db.getCollection("students").aggregate(
[
{
"$project" : {
"_id" : NumberInt(0),
"students" : "$$ROOT"
}
},
{
"$lookup" : {
"localField" : "students._id",
"from" : "units",
"foreignField" : "_id",
"as" : "units"
}
},
{
"$unwind" : {
"path" : "$units",
"preserveNullAndEmptyArrays" : false
}
}
]
);La query SQL precedente restituirà i risultati seguenti:
{ "students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"Maths" : "A","English" : "A","Science" : "A","History" : "B"}}
{ "students" : {"_id" : NumberInt(2), "name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5 },
"units" : {"_id" : NumberInt(2),"Maths" : "B","English" : "B","Science" : "A","History" : "B"}}
{ "students" : {"_id" : NumberInt(3),"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5},
"units" : {"_id" : NumberInt(3),"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}La durata della performance dipenderà ovviamente dalla struttura della tua query. Ad esempio, se hai molti documenti in una raccolta rispetto all'altra, dovresti eseguire l'aggregazione dalla raccolta con documenti minori e quindi cercare in quella con più documenti. In questo modo, una ricerca per il campo scelto dalla raccolta di documenti minori è abbastanza ottimale e richiede meno tempo rispetto a ricerche multiple per un campo scelto nella raccolta con più documenti. Si consiglia quindi di mettere al primo posto la collezione più piccola.
Per un database relazionale, l'ordine dei database non ha importanza poiché la maggior parte degli interpreti SQL dispone di ottimizzatori, che hanno accesso a informazioni aggiuntive per decidere quale dovrebbe essere il primo.
Nel caso di MongoDB, dovremo utilizzare un indice per facilitare l'operazione JOIN. Sappiamo tutti che tutti i documenti MongoDB hanno una chiave _id che per un DBM relazionale può essere considerata la chiave primaria. Un indice offre maggiori possibilità di ridurre la quantità di dati a cui è necessario accedere oltre a supportare l'operazione quando viene utilizzato nella chiave esterna $lookup.
Nella pipeline di aggregazione, per utilizzare un indice, dobbiamo assicurarci che la corrispondenza $ venga eseguita nella prima fase per filtrare i documenti che non corrispondono ai criteri. Ad esempio se vogliamo recuperare il risultato per lo studente con valore del campo _id uguale a 1:
select *
from students
INNER JOIN units
ON students._id = units._id
WHERE students._id = 1;Il codice MongoDB equivalente che otterrai in questo caso è:
db.getCollection("students").aggregate(
[{"$project" : { "_id" : NumberInt(0), "students" : "$$ROOT" }},
{ "$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"} },
{ "$unwind" : { "path" : "$units","preserveNullAndEmptyArrays" : false } },
{ "$match" : {"students._id" : NumberLong(1) }}
]);Il risultato restituito per la query precedente sarà:
{"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5,
"studentUnits" : [{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}]}Quando non utilizziamo la fase $match o meglio non nella prima fase, se controlliamo con la funzione di spiegazione, otterremo anche la fase COLLSCAN inclusa. L'esecuzione di un COLLSCAN per un ampio set di documenti richiede generalmente molto tempo. Decidiamo quindi di utilizzare un campo indice che nella funzione di spiegazione coinvolge solo la fase IXSCAN. Quest'ultimo ha un vantaggio poiché stiamo controllando un indice nei documenti e non scansioniamo tutti i documenti; non ci vorrà molto per restituire i risultati. Potresti avere una struttura dati diversa come:
{ "_id" : NumberInt(1),
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"
}
}Potremmo voler restituire i voti come entità diverse in un array piuttosto che come un intero campo voti incorporato.
Dopo aver scritto la query SQL sopra, è necessario modificare il codice MongoDB risultante. Per farlo, clicca sull'icona di copia a destra come di seguito per copiare il codice di aggregazione:
Quindi vai alla scheda di aggregazione e nel riquadro presentato, c'è un'icona di incolla, fai clic su di essa per incollare il codice.
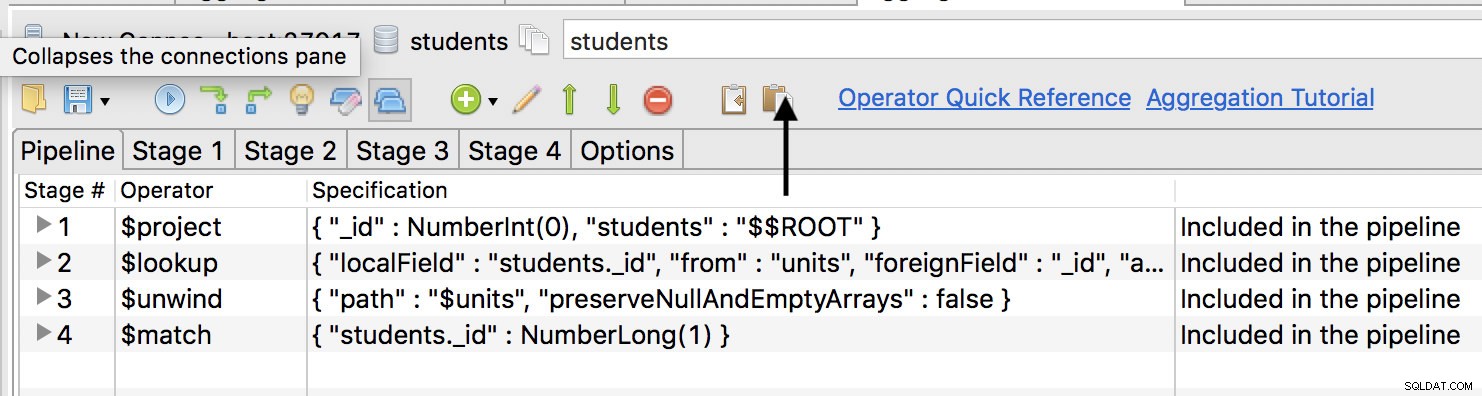
Fai clic sulla riga $match e poi sulla freccia verde in alto per spostare la fase in alto come prima fase. Tuttavia, dovrai prima creare un indice nella tua raccolta come:
db.students.createIndex(
{ _id: 1 },
{ name: studentId }
)Otterrai il codice di esempio di seguito:
db.getCollection("students").aggregate(
[{ "$match" : {"_id" : 1.0}},
{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id","as" : "units"}},
{ "$unwind" : {"path" : "$units", "preserveNullAndEmptyArrays" : false}}
]Con questo codice otterremo il risultato di seguito:
{ "students" : {"_id" : NumberInt(1), "name" : "James Washington","age" : 15.0,"grade" : "A", "score" : 10.5},
"units" : {"_id" : NumberInt(1), "grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"}}}Ma tutto ciò di cui abbiamo bisogno è avere i voti come entità di documento separata nel documento restituito e non come nell'esempio sopra. Aggiungeremo quindi la fase $addfields da cui il codice come di seguito.
db.getCollection("students").aggregate(
[{ "$match" : {"_id" : 1.0}},
{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id","as" : "units"}},
{ "$unwind" : {"path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$addFields" : {"units" : "$units.grades"} }]I documenti risultanti saranno quindi:
{
"students" : {"_id" : NumberInt(1), "name" : "James Washington", "grade" : "A","score" : 10.5},
"units" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"}
}I dati restituiti sono abbastanza accurati, poiché abbiamo eliminato i documenti incorporati dalla raccolta delle unità come campo separato.
Nel nostro prossimo tutorial, esamineremo le query con diversi join.



