Backup:una delle cose più importanti di cui occuparsi durante la gestione dei database. Si dice che ci siano due tipi di persone:quelle che eseguono il backup dei propri dati e quelle che eseguiranno il backup dei propri dati. In questo post del blog, discuteremo delle buone pratiche relative ai backup e ti mostreremo come creare un sistema di backup affidabile utilizzando ClusterControl.
Vedremo come ClusterControl ti offre una gestione centralizzata dei backup per MySQL, MariaDB, MongoDB e PostgreSQL. Fornisce backup a caldo di set di dati di grandi dimensioni, ripristino point-in-time, crittografia dei dati inattivi e in transito, integrità dei dati tramite la verifica del ripristino automatico, backup su cloud (AWS, Google e Azure) per il ripristino di emergenza, criteri di conservazione per garantire la conformità e avvisi e rapporti automatizzati.
Tipi di backup
Esistono due tipi principali di backup che possiamo eseguire in ClusterControl:
- Backup logico:il backup dei dati è archiviato in un formato leggibile come SQL
- Backup fisico:il backup contiene dati binari
Entrambi si completano a vicenda:il backup logico consente di recuperare (più o meno facilmente) fino a una singola riga di dati. I backup fisici richiederebbero più tempo per farlo, ma, d'altra parte, ti consentono di ripristinare un intero host molto rapidamente (cosa che potrebbe richiedere ore o addirittura giorni quando si utilizza il backup logico).
ClusterControl supporta il backup per MySQL/MariaDB/Percona Server, PostgreSQL e MongoDB.
Programma backup
L'avvio di un backup in ClusterControl è semplice ed efficiente utilizzando una procedura guidata. La pianificazione di un backup offre facilità d'uso e accessibilità ad altre funzionalità come la crittografia, il test/verifica automatica del backup o l'archiviazione su cloud.
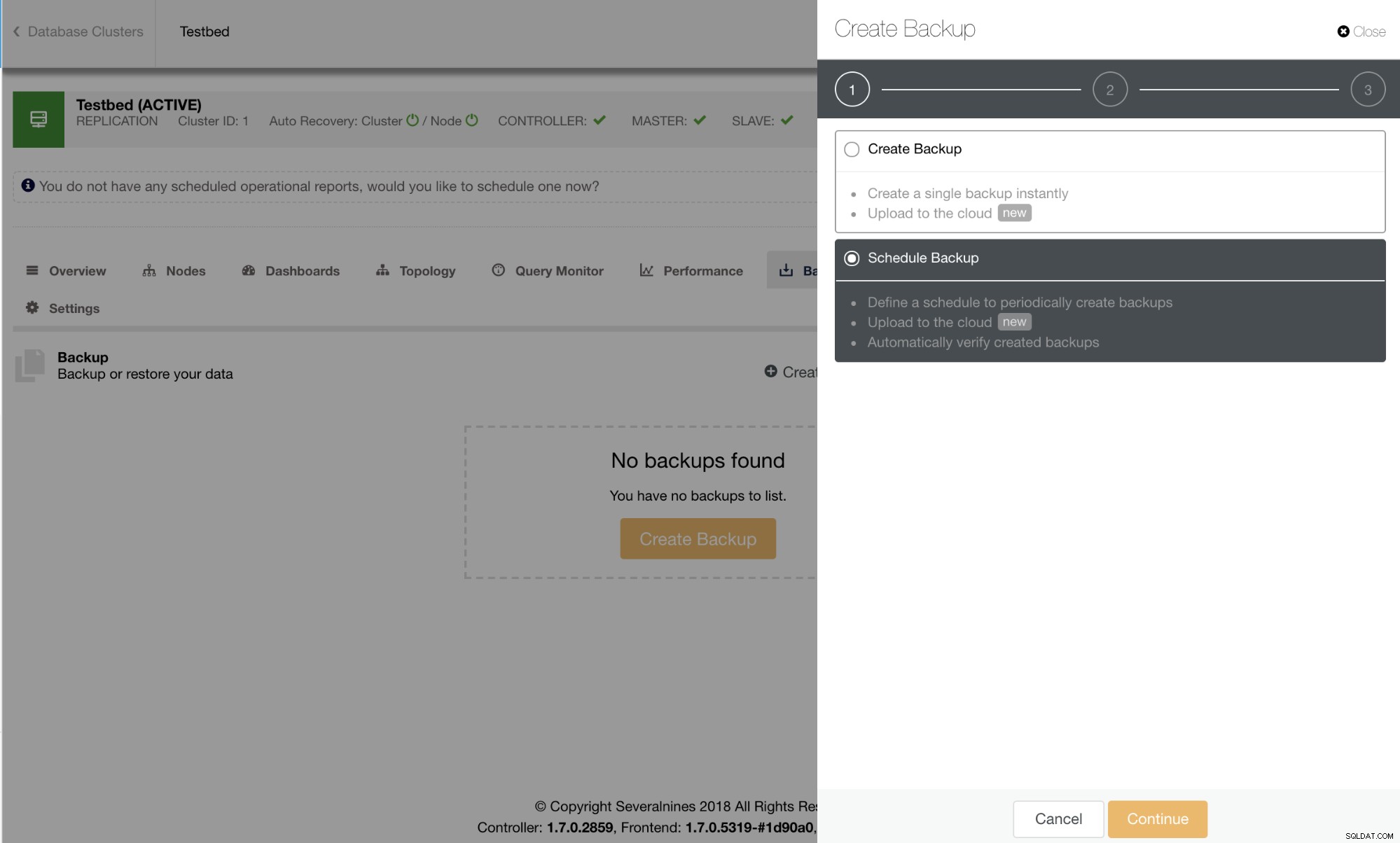
I backup pianificati disponibili verranno elencati nella scheda Backup pianificati come mostrato nell'immagine seguente:
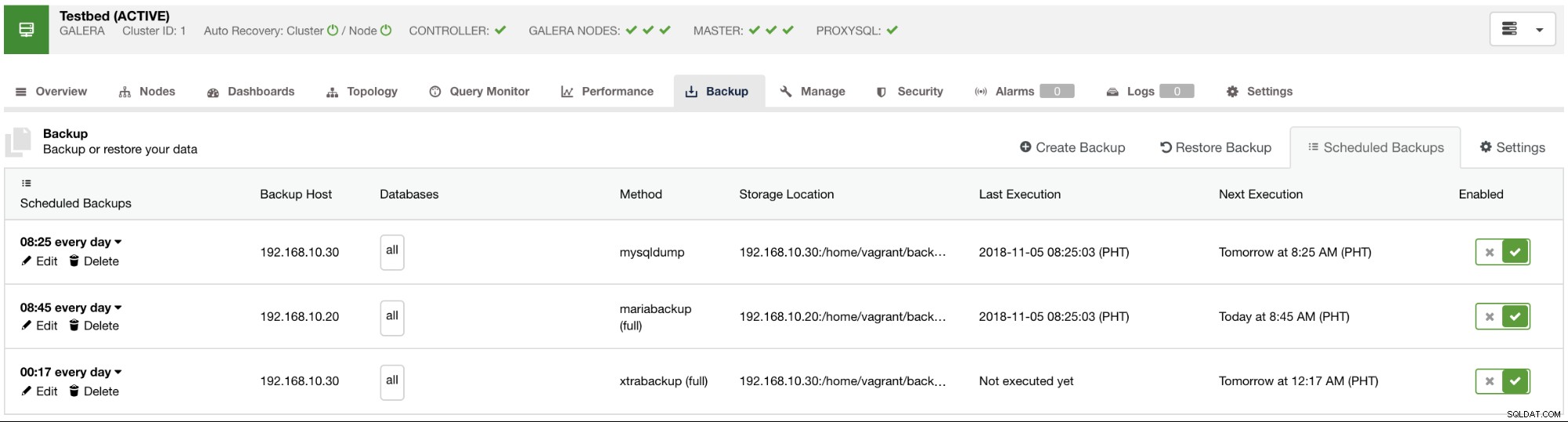
Come buona pratica per la pianificazione di un backup, è necessario disporre già della conservazione del backup definita e si consiglia un backup giornaliero. Tuttavia, dipende anche dai dati di cui hai bisogno, dal traffico che potresti aspettarti e dalla disponibilità dei dati ogni volta che ne hai bisogno, specialmente durante il ripristino dei dati in cui i dati sono stati eliminati accidentalmente o un danneggiamento del disco, il che è inevitabile. Ci sono anche situazioni in cui la perdita di dati è riproducibile o può essere duplicata manualmente, come ad esempio la generazione di report, miniature o dati memorizzati nella cache. Anche se la domanda si basa su quanto immediatamente ne hai bisogno ogni volta che si verifica un disastro; quando possibile, ti consigliamo di eseguire backup sia mysqldump che xtrabackup su base giornaliera per MySQL sfruttando la disponibilità del backup logico e fisico. Per coprire ancora più basi, potresti voler pianificare diverse esecuzioni incrementali di xtrabackup al giorno. Ciò potrebbe far risparmiare spazio su disco, I/O del disco o persino I/O della CPU rispetto a eseguire un backup completo.
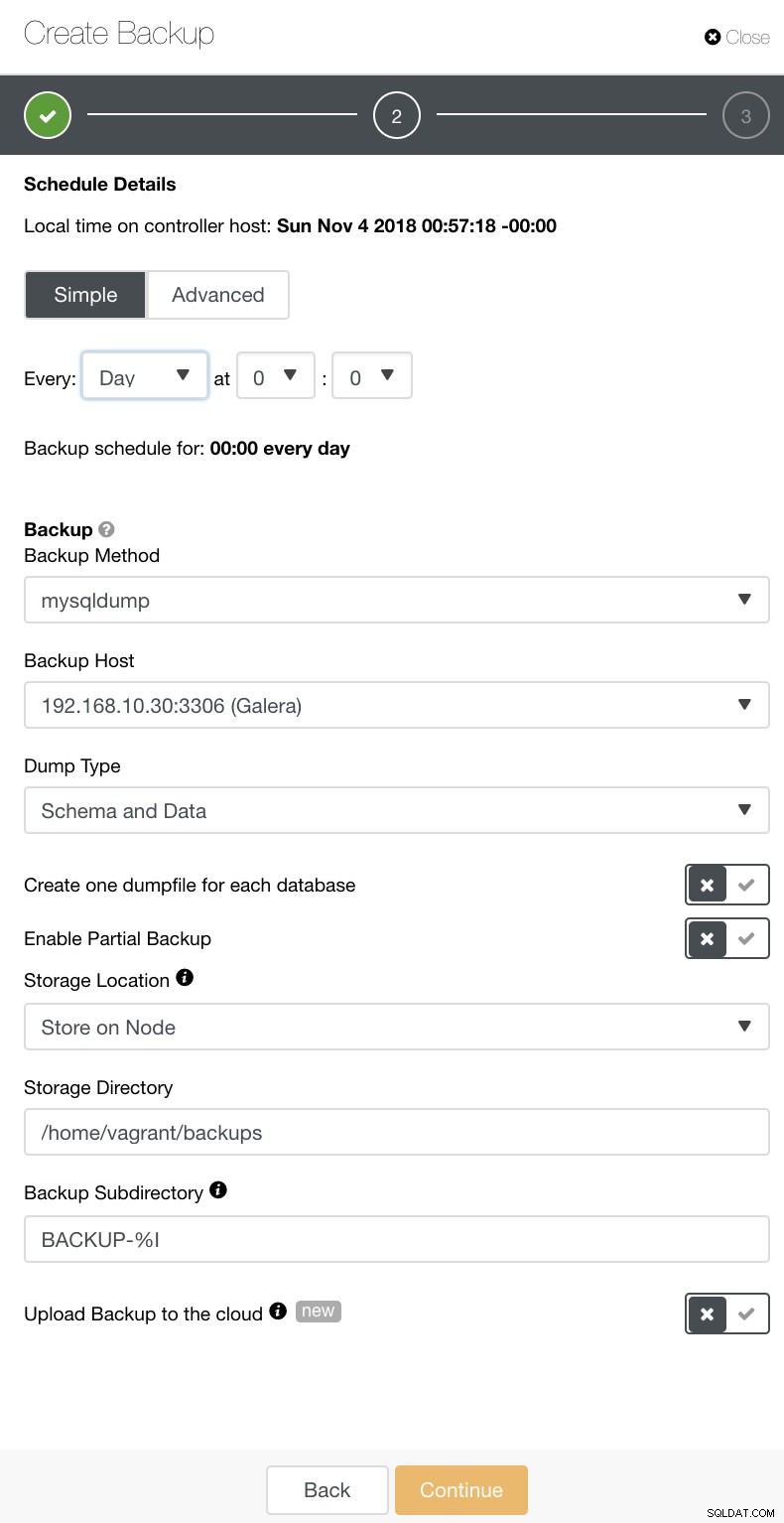
In ClusterControl è possibile pianificare facilmente questi diversi tipi di backup. Ci sono un paio di impostazioni su cui decidere. È possibile archiviare un backup sul controller o localmente, sul nodo del database in cui viene eseguito il backup. Devi decidere la posizione in cui archiviare il backup e di quali database desideri eseguire il backup:tutti i set di dati o schemi separati? Vedi l'immagine qui sotto:
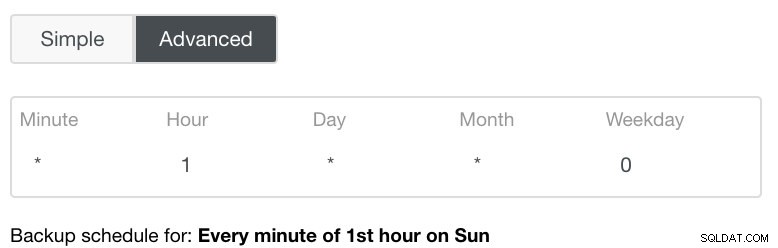
L'impostazione Avanzata sfrutterebbe una configurazione simile a cron per una maggiore granularità. Vedi immagine sotto:
Ogni volta che si verifica un errore, ClusterControl gestisce questi problemi in modo efficiente e produce registri per un'ulteriore diagnosi dell'errore di backup.
A seconda del tipo di backup che hai scelto, ci sono impostazioni separate da configurare. Per Xtrabackup e Galera Cluster, potresti avere la possibilità di scegliere le impostazioni che il tuo backup fisico applicherebbe durante l'esecuzione. Vedi sotto:
- Utilizza la compressione
- Livello di compressione
- Desync nodo durante il backup
- Blocchi backup
- Blocca DDL per tabella
- Thread di copia parallela di Xtrabackup
- Velocità di limitazione dello streaming di rete (MB/s)
- Usa PIGZ per gzip parallelo
- Abilita crittografia
- Conservazione
Puoi vedere, nell'immagine qui sotto, come puoi contrassegnare le opzioni di conseguenza e ci sono icone di descrizione comando che forniscono maggiori informazioni sulle opzioni che vorresti sfruttare per la tua politica di backup.
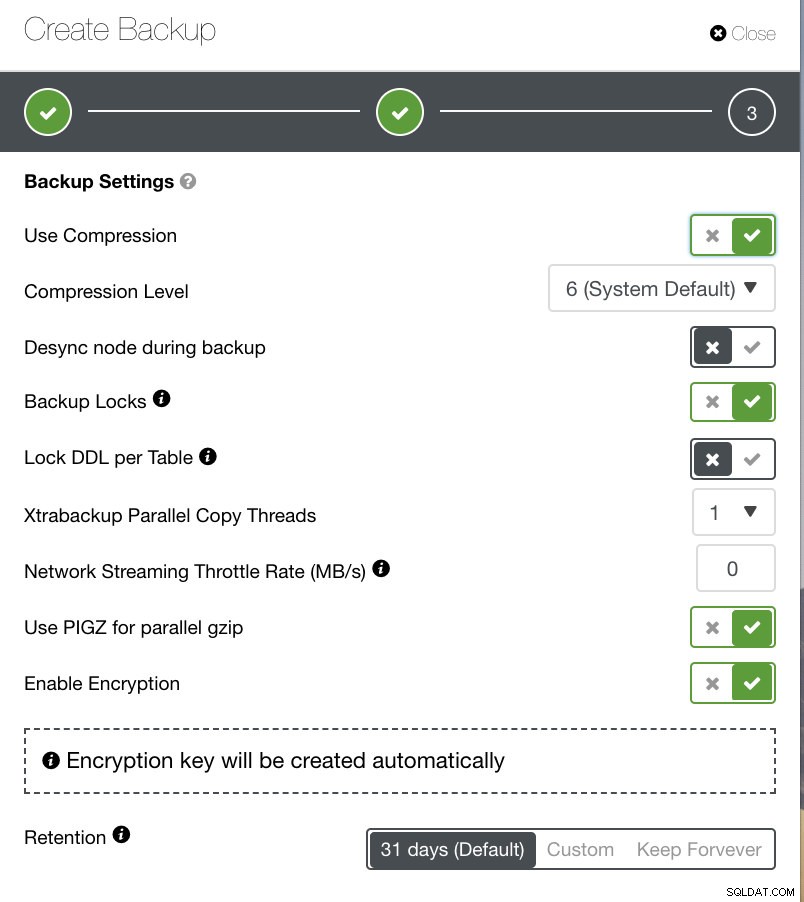
A seconda della politica di backup, ClusterControl può essere personalizzato in base alle migliori pratiche per l'aggiornamento dei backup disponibili. Dopo aver definito la policy di backup, è necessario disporre della configurazione richiesta dall'hardware al software, al cloud, alla durabilità, all'elevata disponibilità o alla scalabilità.
Quando si eseguono backup su un cluster Galera, è buona norma impostare il nodo Galera wsrep_desync=ON mentre il backup è in esecuzione. Ciò eliminerà il nodo dalla partecipazione al controllo di flusso e proteggerà l'intero cluster dal ritardo di replica, soprattutto se i dati di cui eseguire il backup sono di grandi dimensioni. In ClusterControl, tieni presente che questo potrebbe anche rimuovere il tuo nodo di backup di destinazione dal set di bilanciamento del carico. Ciò è particolarmente vero se si utilizzano proxy HAProxy, ProxySQL o MaxScale. Se hai configurato il gestore degli avvisi nel caso in cui il nodo non sia sincronizzato, puoi disattivarlo durante il periodo in cui il backup è stato attivato.
Un altro modo popolare per ridurre al minimo l'impatto di un backup su un cluster Galera o su un master di replica è distribuire uno slave di replica e quindi utilizzarlo come origine di backup:in questo modo il cluster Galera non sarà influenzato in nessun momento poiché il backup sul lo slave è disaccoppiato dal cluster.
È possibile distribuire un tale slave in pochi clic utilizzando ClusterControl. Vedi immagine sotto:
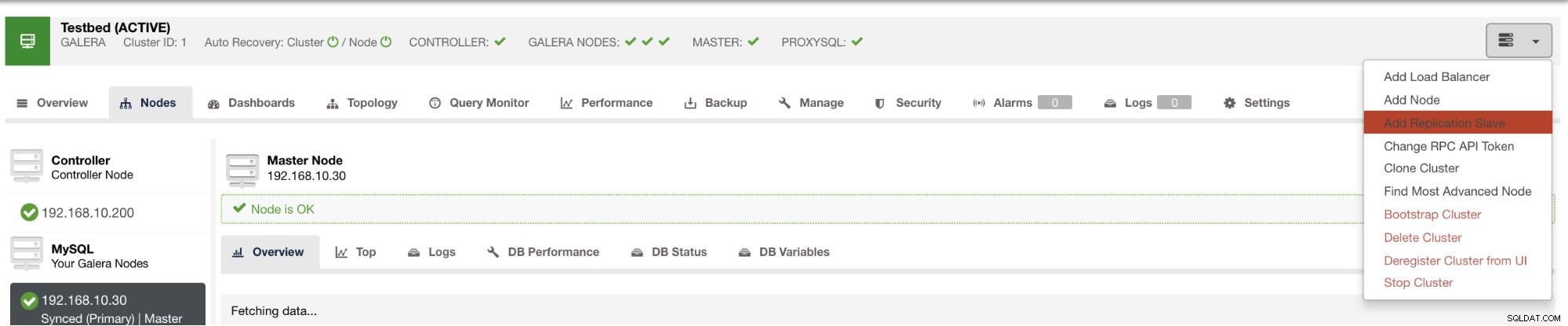
e una volta fatto clic su quel pulsante, puoi selezionare su quali nodi configurare uno slave. Assicurati che la registrazione binaria dei nodi sia abilitata. L'abilitazione del log binario può essere eseguita anche tramite ClusterControl che aggiunge più fattibilità per l'amministrazione del master desiderato. Vedi immagine sotto:
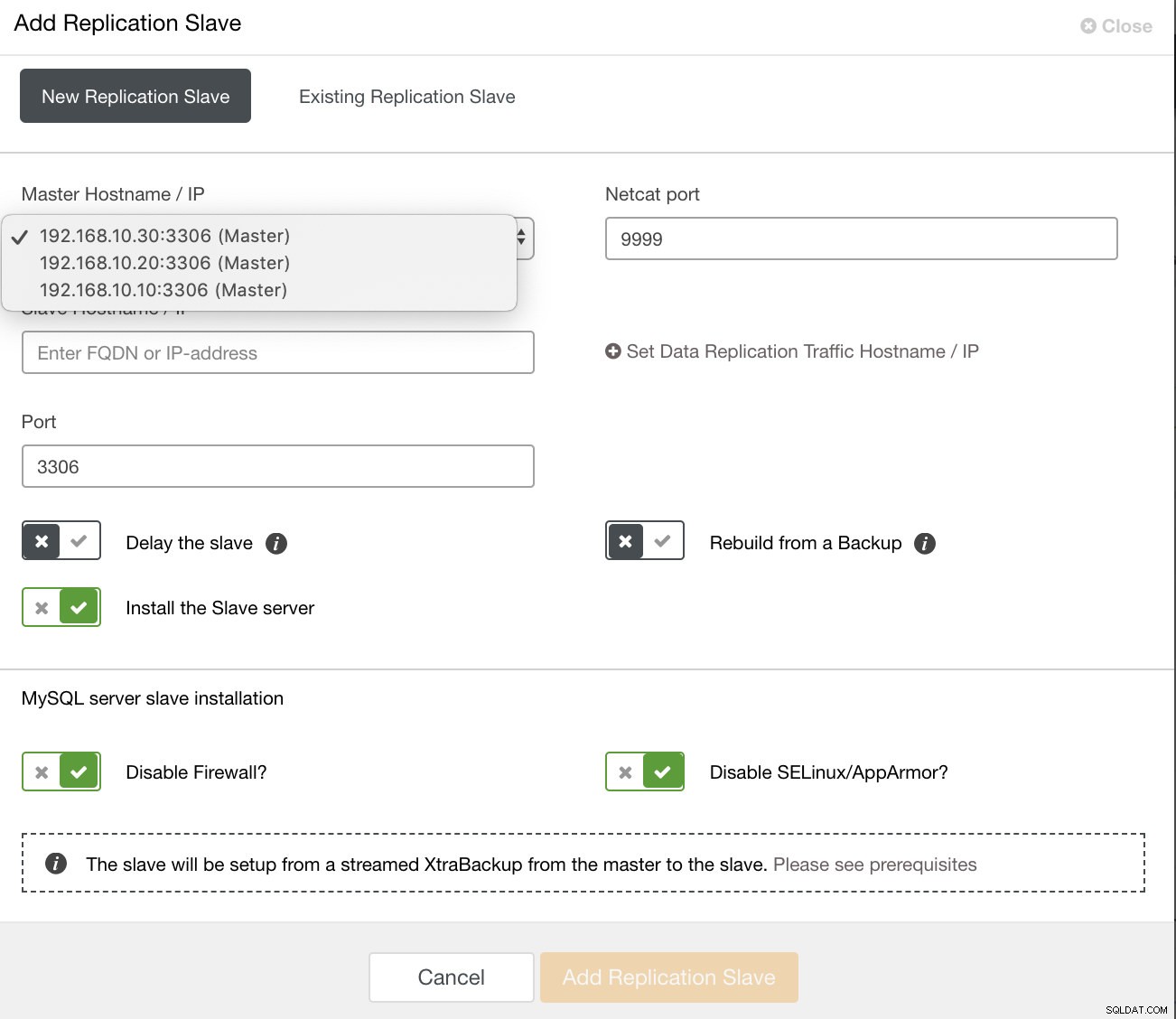
e puoi anche configurare lo slave di replica esistente,
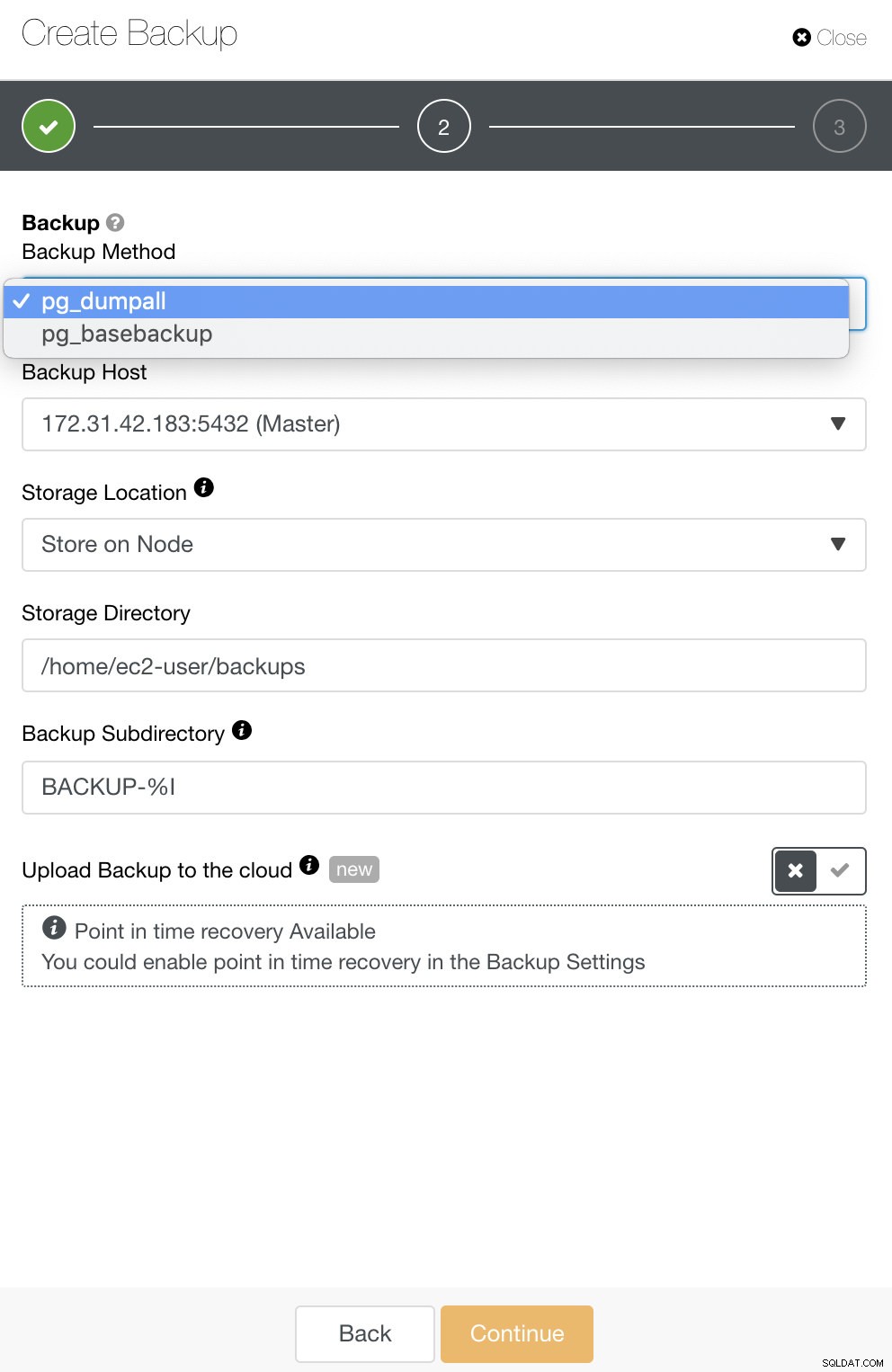
Per PostgreSQL, hai opzioni per eseguire il backup di backup logici o fisici. In ClusterControl, puoi sfruttare i tuoi backup PostgreSQL selezionando pg_dump o pg_basebackup. pg_basebackup non funzionerà per le versioni precedenti alla 9.3.
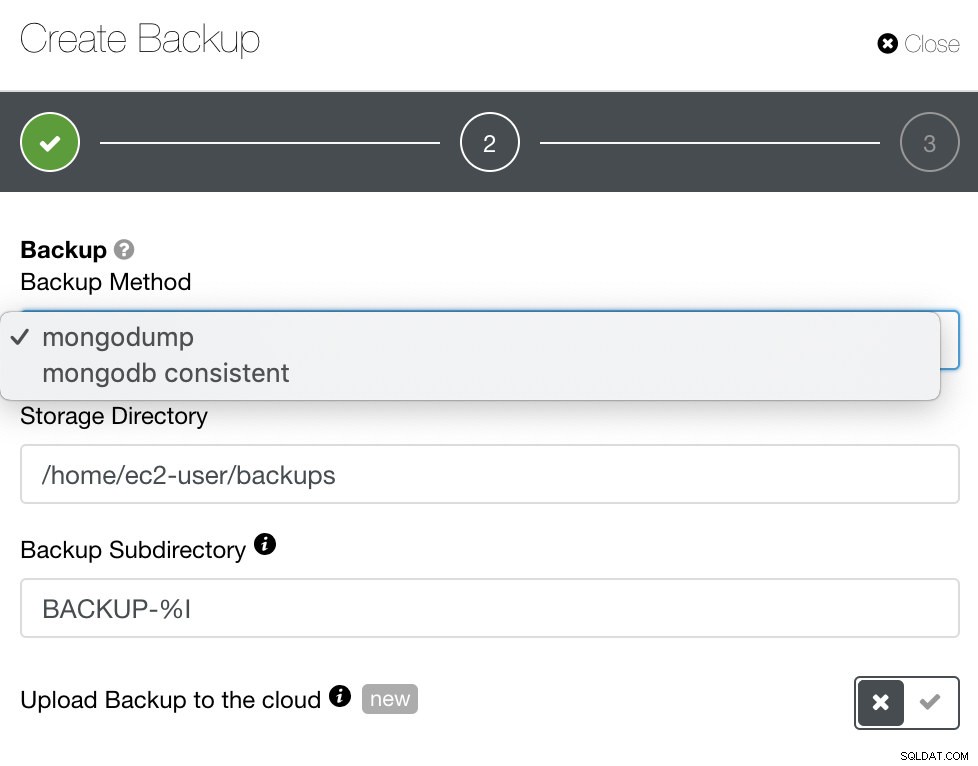
Per MongoDB, ClusterControl offre mongodump o mongodb coerenti. Potrebbe essere necessario prendere nota del fatto che mongodb consistent non supporta RHEL 7 ma potresti essere in grado di installarlo manualmente.
Per impostazione predefinita, ClusterControl elencherà un report per tutti i backup eseguiti, riusciti o non riusciti. Vedi sotto:
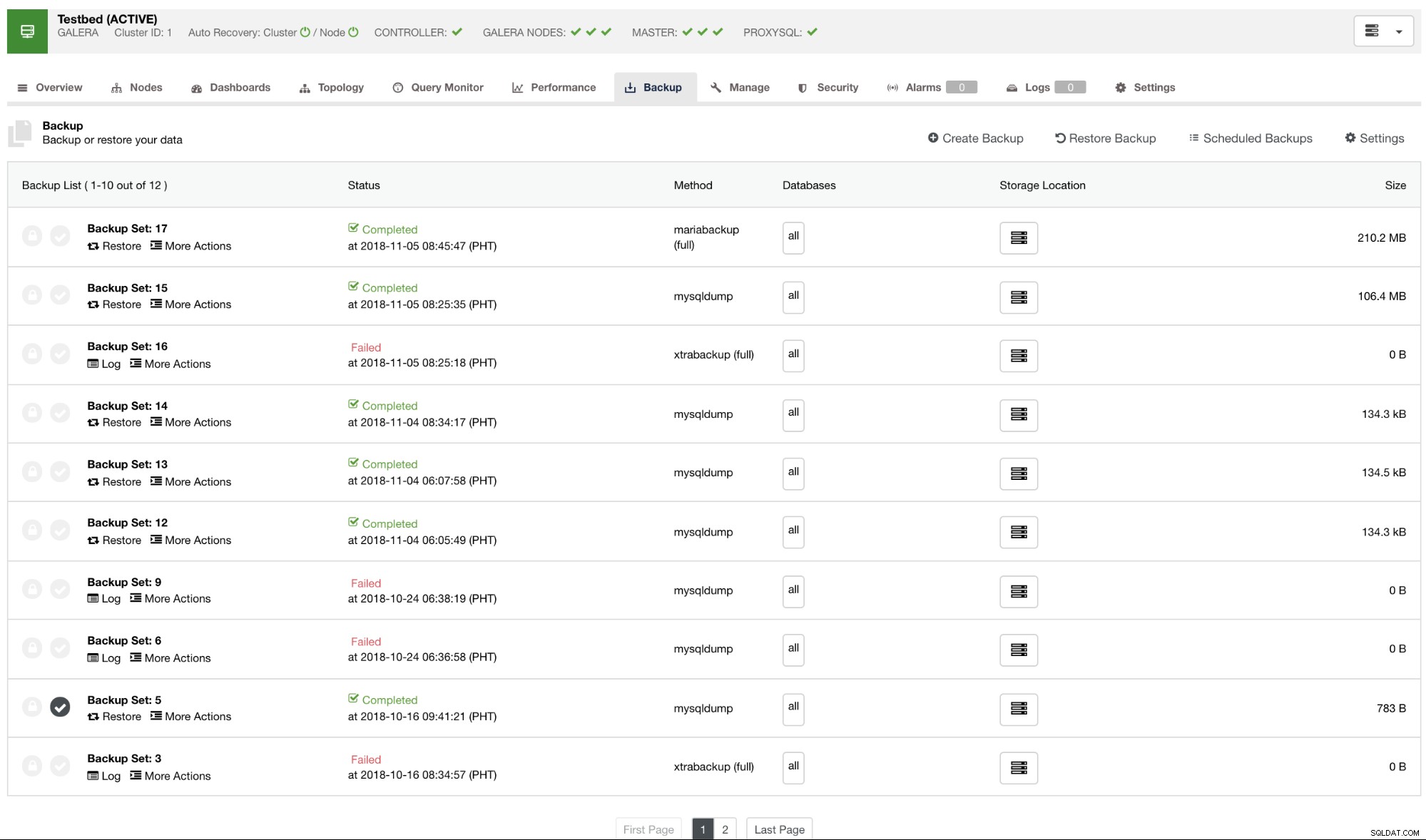
È possibile controllare l'elenco dei report di backup che sono stati creati o pianificati utilizzando ClusterControl. All'interno dell'elenco, è possibile visualizzare i registri per ulteriori indagini e diagnosi. Ad esempio, se il backup è stato completato correttamente in base alla politica di backup desiderata, se la compressione e la crittografia sono impostate correttamente o se la dimensione dei dati di backup desiderata è corretta. Questo è un buon modo per eseguire un rapido controllo di integrità:se il tuo set di dati ha una dimensione di circa 1 GB, non è possibile che un backup completo possa essere piccolo quanto 100 KB:qualcosa deve essere andato storto a un certo punto.
Ripristino di emergenza
L'archiviazione dei backup all'interno del cluster (direttamente su un nodo del database o sull'host ClusterControl) è utile quando si desidera ripristinare rapidamente i dati:tutti i file di backup sono presenti e possono essere decompressi e ripristinati tempestivamente. Quando si tratta di Disaster Recovery (DR), questa potrebbe non essere l'opzione migliore. Possono verificarsi diversi problemi:i server potrebbero bloccarsi, la rete potrebbe non funzionare in modo affidabile, persino interi data center potrebbero non essere accessibili a causa di un qualche tipo di interruzione. Può succedere se lavori con un fornitore di servizi più piccolo con un singolo data center o un fornitore globale come Amazon Web Services. Non è quindi sicuro conservare tutte le tue uova in un unico paniere:dovresti assicurarti di avere una copia del tuo backup archiviata in una posizione esterna. ClusterControl supporta Amazon S3, Google Storage e Azure Cloud Storage.
Per coloro che desiderano implementare le proprie politiche di ripristino di emergenza, i backup di ClusterControl sono archiviati in una directory ben strutturata. Hai anche la possibilità di caricare il backup sul cloud. Vedi immagine sotto:
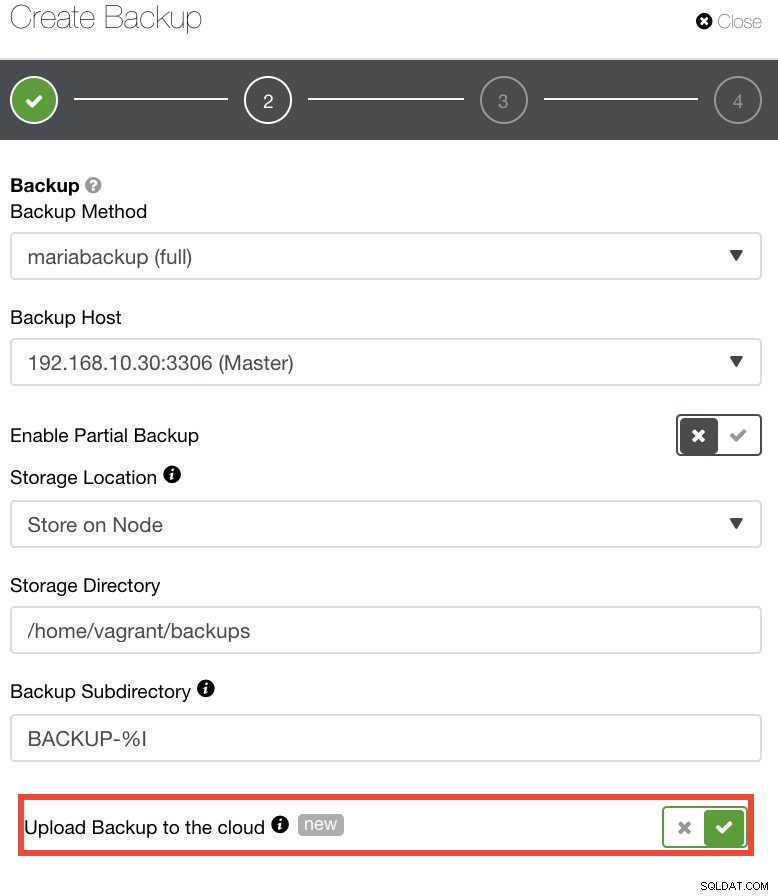
Puoi selezionare e caricare su Amazon Web Services, Google Cloud e Microsoft Azure. Vedi immagine sotto:
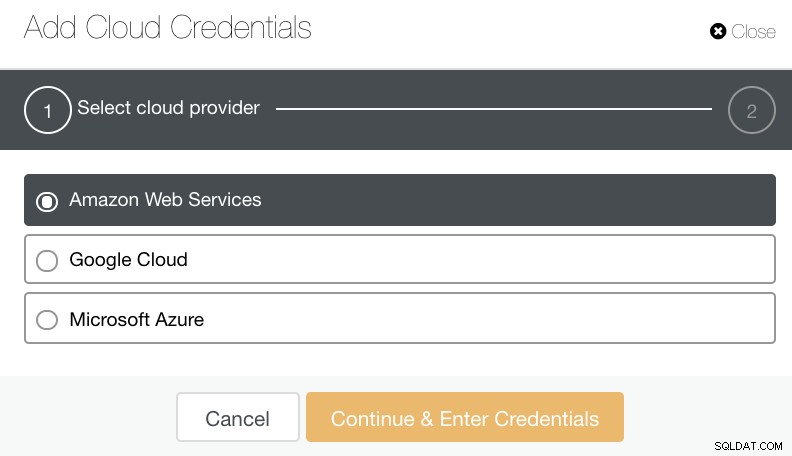
Come buona pratica quando si archiviano i backup del database, assicurarsi che la destinazione cloud di destinazione sia basata sulla stessa regione dei server di database, o almeno sul più vicino. Assicurati che offra disponibilità elevata, durabilità e scalabilità; poiché devi considerare quanto spesso e nell'immediato hai bisogno dei tuoi dati.
Oltre a creare un backup logico o fisico per il tuo DR, la creazione di uno snapshot completo dei tuoi dati (ad es. utilizzando LVM Snapshot, Amazon EBS Snapshot o Volume Snapshot se si utilizza il file system Veritas) sul nodo specifico può aumentare il ripristino del backup. Puoi anche usare WAL (per Postgres) per il tuo Point In Time Recovery (PITR) o i tuoi log binari MySQL per il tuo PITR. Pertanto, devi considerare che potrebbe essere necessario creare la tua archiviazione per il tuo PITR. Quindi è perfetto creare e distribuire il tuo set di script e gestire il DR in base alle tue esatte esigenze.
Un altro ottimo modo per implementare una politica di ripristino di emergenza consiste nell'utilizzare uno slave di replica asincrono, qualcosa che abbiamo menzionato in precedenza in questo post del blog. È possibile distribuire tale slave asincrono in una posizione remota, forse un altro data center, e quindi utilizzarlo per eseguire backup e archiviarli localmente su quello slave. Ovviamente, vorrai eseguire un backup locale del tuo cluster per averlo localmente se dovessi ripristinare il cluster. Lo spostamento dei dati tra i data center potrebbe richiedere molto tempo, quindi avere un backup dei file disponibile in locale può farti risparmiare tempo. Nel caso in cui perdi l'accesso al tuo cluster di produzione principale, potresti comunque avere un accesso allo slave. Questa configurazione è molto flessibile:in primo luogo, hai un host MySQL in esecuzione con i tuoi dati di produzione, quindi non dovrebbe essere troppo difficile distribuire la tua applicazione completa nel sito DR. Avrai anche backup dei tuoi dati di produzione che potresti utilizzare per scalare il tuo ambiente di ripristino di emergenza.
Infine e soprattutto, un backup che non è stato testato rimane un backup non verificato, noto anche come Schroedinger Backup. Per assicurarti di avere un backup funzionante, devi eseguire un test di ripristino. ClusterControl offre un modo per verificare e testare automaticamente il backup.
Ci auguriamo che questo ti fornisca informazioni sufficienti per creare una procedura di backup sicura e affidabile per i tuoi database open source.



