SCUMM (Severalnines ClusterControl Unified Monitoring &Management) è una soluzione basata su agenti con agenti installati sui nodi del database. Fornisce una serie di dashboard di monitoraggio, che hanno Prometheus come archivio dati con il suo linguaggio di query elastico e il modello di dati multidimensionale. Prometheus estrae i dati delle metriche dagli esportatori in esecuzione sugli host del database.
L'architettura ClusterControl SCUMM è stata introdotta con la versione 1.7.0 che estende le funzionalità di monitoraggio per MySQL, Galera Cluster, PostgreSQL e ProxySQL.
Il nuovo ClusterControl 1.7.1 aggiunge il monitoraggio ad alta risoluzione per i sistemi MongoDB.
 Elenco dashboard di ClusterControl MongoDB
Elenco dashboard di ClusterControl MongoDB In questo articolo descriveremo le due dashboard principali per gli ambienti MongoDB. Server MongoDB e Repliche MongoDB.
Dashboard e elenco delle metriche
L'elenco delle dashboard e le relative metriche:
| Server MongoDB | |
|---|---|
| Nome ReplSet Nome Tempo di attività del server Contatori operativi Connessioni WT - Biglietti simultanei (lettura) WT - Biglietti simultanei (scrittura) /> WT - Cache Blocco globale Affermazioni |
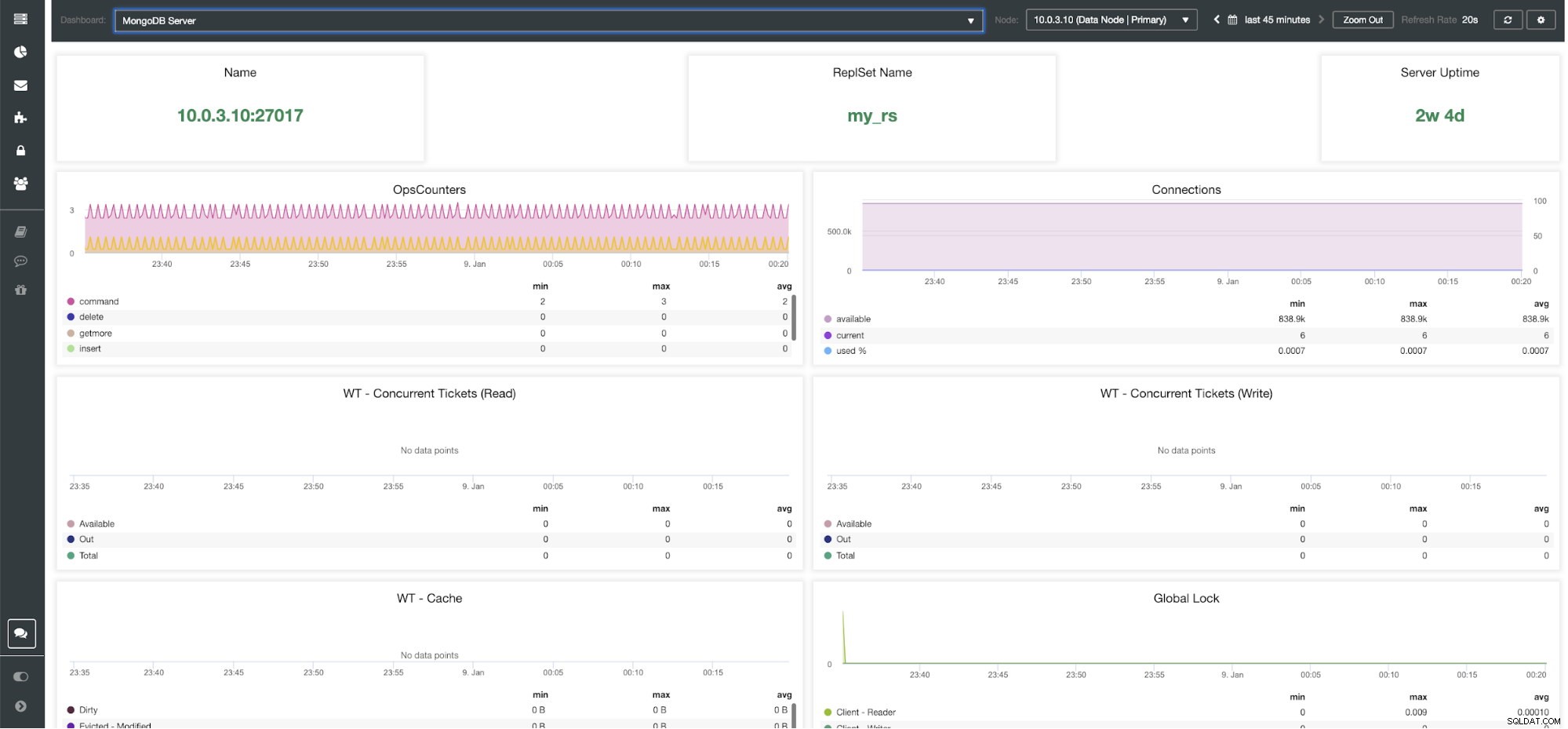 Dashboard del server MongoDB ClusterControl
Dashboard del server MongoDB ClusterControl| MongoDB ReplicaSet | |
|---|---|
| Dimensione ReplSet Nome ReplSet PRIMARY Versione server Set di repliche e membri Finestra Oplog per ReplSet Headroom replica Totale di PRIMARIO/SECONDARIO online per ReplSet Cursori aperti per ReplSet ReplSet - Cursori scaduti per set Ritardo massimo di replica per ReplSet Dimensione oplog Contatori operazioni Tempo di ping per replicare i membri del set da PRIMARY |
 ClusterControl MongoDB ReplicaSet Dashboard
ClusterControl MongoDB ReplicaSet Dashboard I sistemi di database dipendono fortemente dalle risorse del sistema operativo, quindi puoi anche trovare due dashboard aggiuntivi per Panoramica del sistema e Panoramica del cluster del tuo ambiente MongoDB.
| Panoramica del sistema | |
|---|---|
| Tempo di attività del server Core CPU RAM totale Carico medio Utilizzo della CPU Utilizzo della RAM Utilizzo dello spazio su disco Utilizzo della rete /> Disk IOPS Disk IO Util % Disk Throughput |
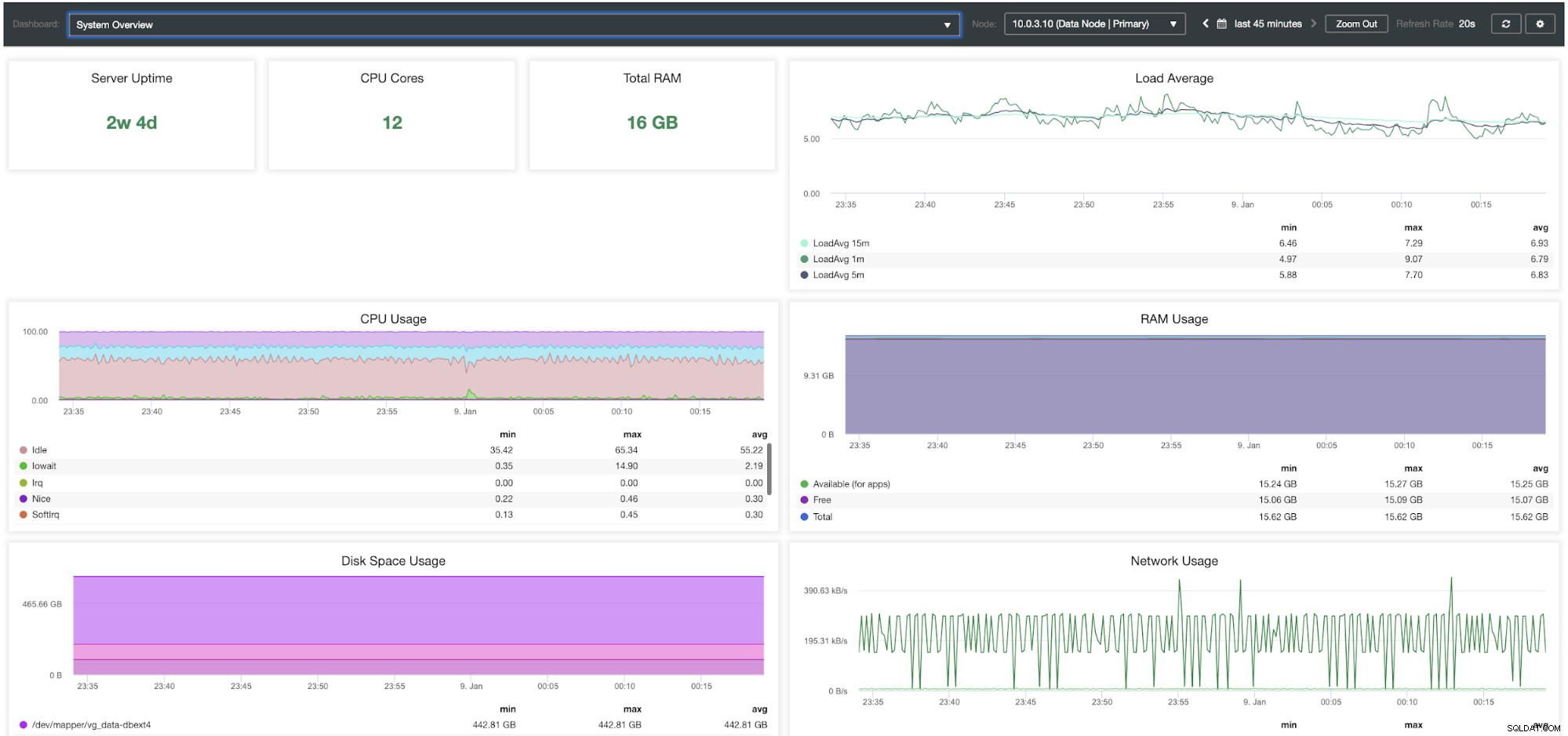 Dashboard Panoramica del sistema ClusterControl
Dashboard Panoramica del sistema ClusterControl| Panoramica del cluster | |
|---|---|
| Carico medio 1 m Carico medio 5 m Carico medio 15 m Memoria disponibile per applicazioni Rete TX Rete RX Lettura disco IOPS IOPS di scrittura su disco IOPS di scrittura su disco + lettura |
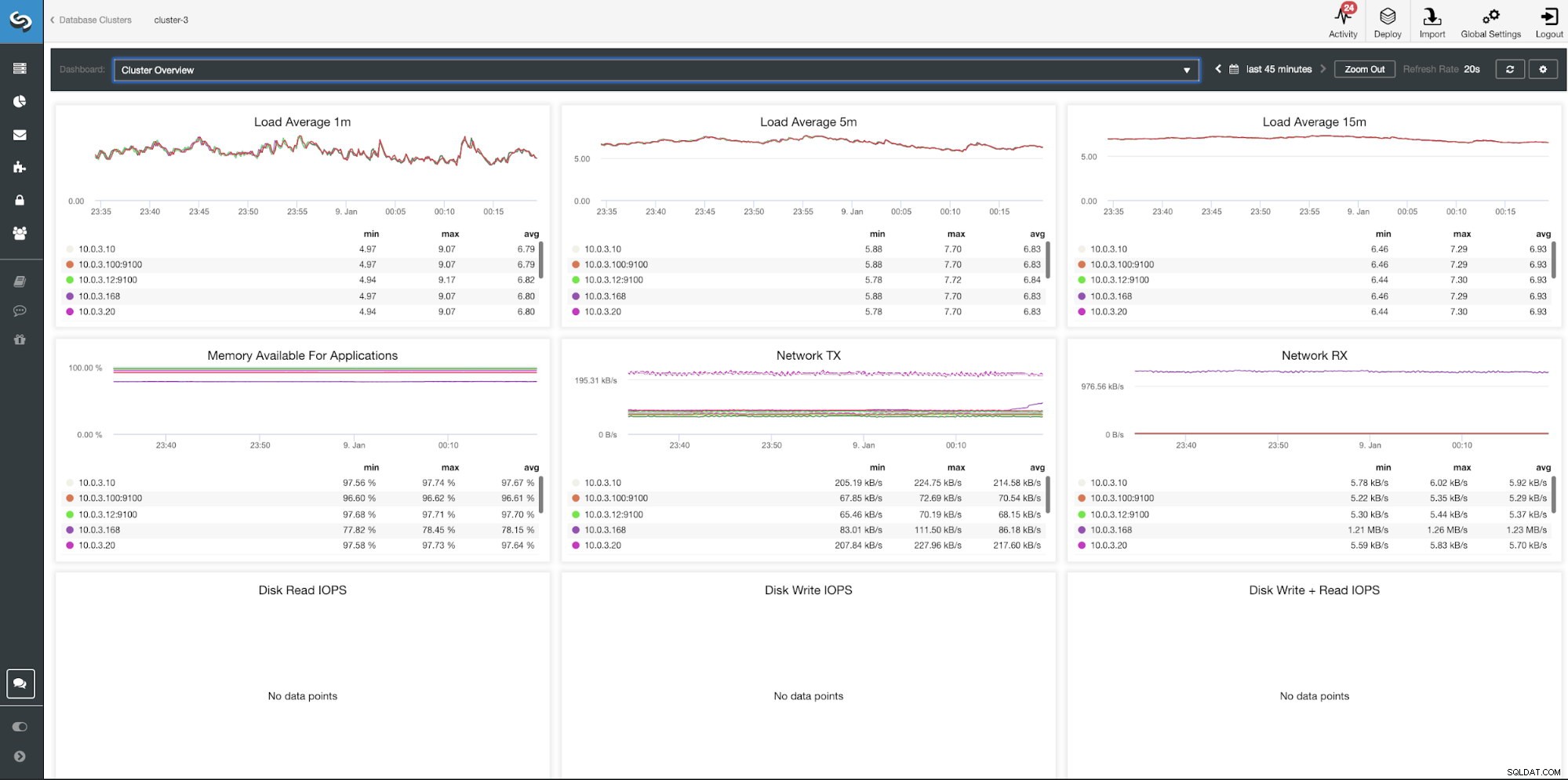 Dashboard Panoramica ClusterControl Cluster
Dashboard Panoramica ClusterControl Cluster Dashboard del server MongoDB
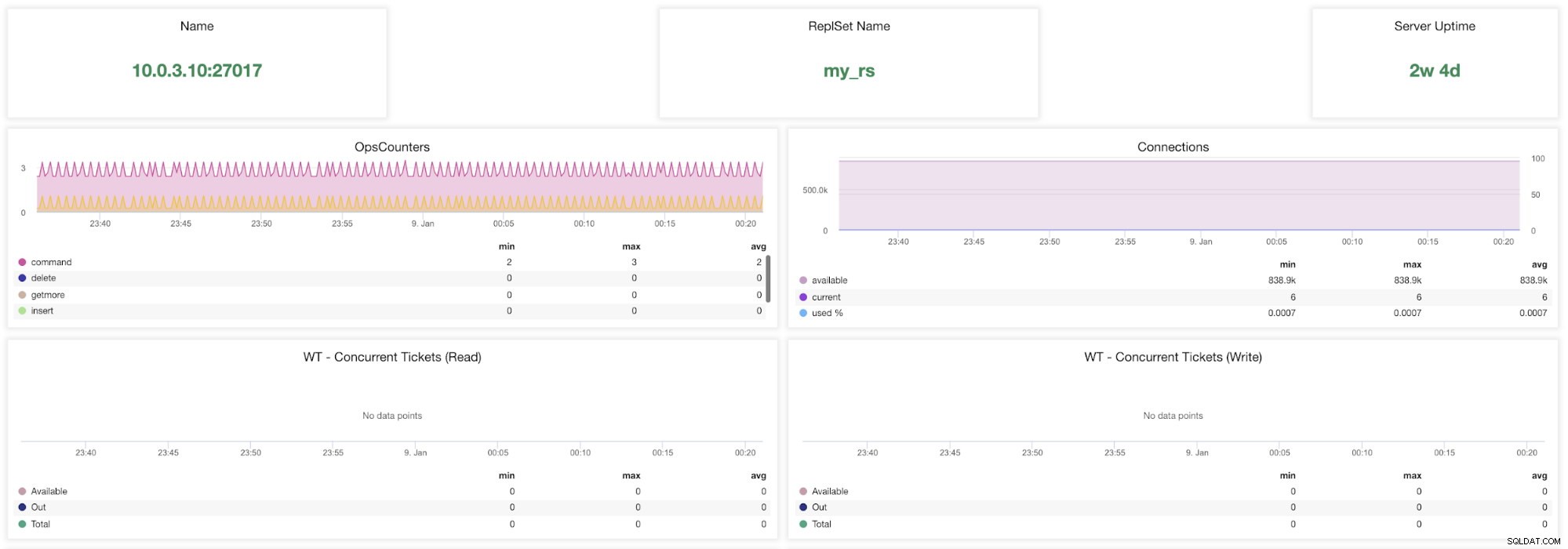 Metriche di ClusterControl MongoDB
Metriche di ClusterControl MongoDB Nome - Indirizzo del server e la porta.
Nome ReplsSet - Presenta il nome del set di repliche a cui appartiene il server.
Tempo di attività del server - Tempo trascorso dall'ultimo riavvio del server.
Segnali operativi - Numero di richieste pervenute nel periodo di tempo selezionato suddiviso per tipologia di operazione. Questi conteggi includono tutte le operazioni ricevute, comprese quelle non riuscite.
Connessioni - Questo grafico mostra una delle metriche più importanti da tenere d'occhio:il numero di connessioni ricevute durante il periodo di tempo selezionato, comprese le richieste non riuscite. Carichi di traffico anomali possono causare problemi di prestazioni. Se MongoDB ha poche connessioni, potrebbe non essere in grado di gestire le richieste in arrivo in modo tempestivo.
WT - Biglietti simultanei (lettura) / WT - Biglietti simultanei (Scrittura) Questi due grafici mostrano i ticket di lettura e scrittura che controllano la concorrenza in WiredTiger (WT). I ticket WT controllano quante operazioni di lettura e scrittura possono essere eseguite contemporaneamente sul motore di archiviazione. Quando i ticket di lettura e scrittura disponibili scendono a zero, il numero di operazioni in esecuzione simultanee è uguale ai valori di lettura/scrittura configurati. Ciò significa che qualsiasi altra operazione deve attendere fino a quando uno dei thread in esecuzione termina il proprio lavoro sul motore di archiviazione prima dell'esecuzione.
 Metriche di ClusterControl MongoDB
Metriche di ClusterControl MongoDB WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - La dimensione della cache è la singola manopola più importante per WiredTiger. Per impostazione predefinita, MongoDB 3.x riserva il 50% (60% in 3.2) della memoria disponibile per la sua cache di dati.
Blocco globale (Client-Read, Client - Write, Current Queue - Reader, Current Queue - Writer) - Modelli di progettazione dello schema scadenti o richieste di lettura e scrittura pesanti da molti client possono causare un blocco esteso. Quando ciò si verifica, è necessario mantenere la coerenza ed evitare conflitti di scrittura.
Per ottenere questo MongoDB utilizza il blocco multi-granularità che consente l'esecuzione delle operazioni di blocco a diversi livelli, ad esempio a livello globale, di database o di raccolta .
Affermazioni (msg, regular, rollover, user) - Questo grafico mostra il numero di asserzioni che vengono generate ogni secondo. È necessario rivedere i valori elevati e le deviazioni dalle tendenze.
Dashboard MongoDB ReplicaSet
Le metriche mostrate in questa dashboard sono importanti solo se utilizzi un set di repliche.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Dimensioni set di repliche - Il numero di membri nel set di repliche. La distribuzione del set di repliche standard per il sistema di produzione è un set di repliche a tre membri. In generale, si raccomanda che un set di repliche abbia un numero dispari di membri votanti. La tolleranza agli errori per un set di repliche è il numero di membri che possono diventare non disponibili e lasciare comunque un numero sufficiente di membri nel set per eleggere un primario. La tolleranza agli errori per tre membri è uno, per cinque è due ecc.
Nome ReplSet - È il nome assegnato nel file di configurazione di MongoDB. Il nome si riferisce al valore /etc/mongod.conf replSet.
PRIMARIO - Il nodo primario riceve tutte le operazioni di scrittura e registra tutte le altre modifiche al suo set di dati nel suo registro delle operazioni. Il valore serve per identificare l'IP e la porta del tuo nodo primario nel cluster del set di repliche MongoDB.
Versione server - Identificare la versione del server. ClusterControl versione 1.7.1 supporta MongoDB versioni 3.2/3.4/3.6/4.0.
Set di repliche e membri (min, max, avg) - Questo grafico può aiutarti a identificare i membri attivi nel periodo di tempo. Puoi tenere traccia del numero minimo, massimo e medio di nodi primari e secondari e di come questi numeri sono cambiati nel tempo. Qualsiasi deviazione può influire sulla tolleranza agli errori e sulla disponibilità del cluster.
Finestra Oplog per ReplSet - La finestra di replica è una metrica essenziale da tenere d'occhio. L'oplog MongoDB è una singola raccolta che è stata limitata in una dimensione (preimpostata). Può essere descritto come la differenza tra il primo e l'ultimo timestamp in oplog.rs. È la quantità di tempo che un secondario può essere offline prima che sia necessaria la sincronizzazione iniziale per sincronizzare l'istanza. Queste metriche ti informano di quanto tempo ti resta prima che la nostra prossima transazione venga eliminata dall'oplog.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Autonomia di replica - Questo grafico presenta la differenza tra la finestra oplog del primario e il ritardo di replica dei nodi secondari. L'oplog MongoDB ha dimensioni limitate e se il nodo è in ritardo troppo, non sarà in grado di recuperare il ritardo. In tal caso, verrà emessa la sincronizzazione completa e questa è un'operazione costosa che deve essere evitata in ogni momento.
Totale di PRIMARIO/SECONDARIO online per ReplSet - Numero totale di nodi del cluster nel periodo di tempo.
Cursori aperti per ReplSet (bloccati, Timeout, Totale) - Una richiesta di lettura viene fornita con un cursore che è un puntatore al set di dati del risultato. Rimarrà aperto sul server e quindi consumerà memoria a meno che non venga terminato dall'impostazione MongoDB predefinita. Dovresti identificare i cursori non attivi e tagliarli per risparmiare in memoria.
ReplSet - Cursori di timeout per SetsMax Replication Lag per ReplSet - Il ritardo di replica è molto importante da tenere d'occhio se si stanno aumentando le letture aggiungendo più secondari. MongoDB utilizzerà questi secondari solo se non sono troppo indietro. Se il secondario presenta un ritardo di replica, rischi di distribuire dati obsoleti che sono già stati sovrascritti sul primario.
OplogSize - Alcuni carichi di lavoro potrebbero richiedere dimensioni oplog maggiori. Aggiornamenti a più documenti contemporaneamente, eliminazioni equivalgono alla stessa quantità di dati di un inserto o al numero significativo di aggiornamenti sul posto.
OpsConter - Questo grafico mostra il numero di esecuzioni di query.
Ping Time to Replica Set Member from Primary - Ciò ti consente di scoprire i membri del set di repliche che sono inattivi o irraggiungibili dal nodo principale.
Osservazioni di chiusura
La nuova funzionalità dashboard ClusterControl 1.7.1 MongoDB è disponibile gratuitamente nella Community Edition. I team operativi del database possono trarne vantaggio utilizzando i grafici ad alta risoluzione, soprattutto quando eseguono le loro routine quotidiane come analisi delle cause principali e pianificazione della capacità.
È solo questione di un clic per distribuire nuovi agenti di monitoraggio. ClusterControl installa gli agenti Prometheus, configura le metriche e mantiene l'accesso alla configurazione degli esportatori di Prometheus tramite la sua GUI, in modo da poter gestire meglio la configurazione dei parametri come i flag di raccolta per gli esportatori (Prometheus).
Monitorando adeguatamente il numero di letture e richieste di scrittura puoi prevenire il sovraccarico delle risorse, trovare rapidamente l'origine di potenziali sovraccarichi e sapere quando aumentare la scalabilità.



