Questi test (database AdventureWorks2008R2) mostrano cosa succede:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Risultati:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
I risultati di SET STATISTICS IO mostra che LIO sono gli uguali .Ma i piani di esecuzione sono abbastanza diversi: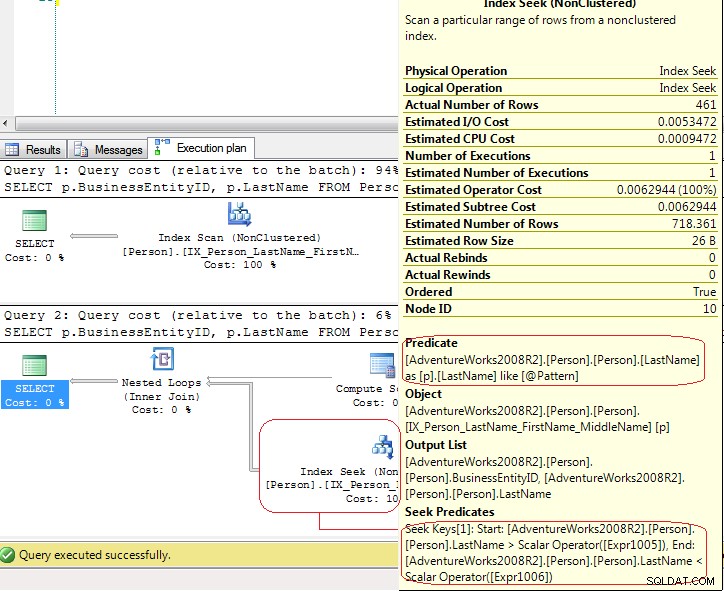
Nel primo test, SQL Server utilizza una Index Scan esplicito ma nel secondo test SQL Server utilizza un Index Seek che è una Index Seek - range scan . Nell'ultimo caso SQL Server utilizza un Compute Scalar operatore per generare questi valori
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
e, la Index Seek l'operatore utilizza un Seek Predicate (ottimizzato) per una range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) più un altro Predicate non ottimizzato (LastName LIKE @pattern ).
La mia risposta:non è un Index Seek "reale". . È una Index Seek - range scan che, in questo caso, ha le stesse prestazioni di Index Scan .
Si prega di vedere, inoltre, la differenza tra Index Seek e Index Scan (dibattito simile):Quindi... è una ricerca o una scansione?
.
Modifica 1: Il piano di esecuzione per OPTION(RECOMPILE) (vedi la raccomandazione di Aaron per favore) mostra anche una Index Scan (anziché Index Seek ):