Ordinando tramite id probabilmente utilizza una scansione dell'indice cluster durante l'ordine per datetime utilizza l'ordinamento o la ricerca nell'indice.
Entrambi questi metodi sono più lenti di una scansione dell'indice in cluster.
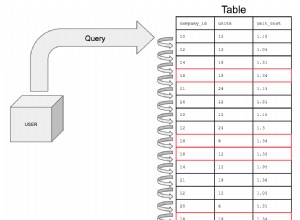
Se la tua tabella è raggruppata per id , in pratica significa che è già ordinato. I record sono contenuti in un B+Tree che ha un elenco collegato che collega le pagine in id ordine. Il motore dovrebbe semplicemente attraversare l'elenco collegato per ottenere i record ordinati per id .
Se l'id s sono stati inseriti in ordine sequenziale, ciò significa che l'ordine fisico delle righe corrisponderà all'ordine logico e la scansione dell'indice cluster sarà ancora più veloce.
Se desideri che i tuoi record vengano ordinati entro datetime , ci sono due opzioni:
- Prendi tutti i record dalla tabella e ordinali. La lentezza è evidente.
- Utilizza l'indice su
datetime. L'indice è archiviato in uno spazio separato del disco, ciò significa che il motore deve spostarsi tra le pagine dell'indice e le pagine della tabella in un ciclo annidato. È anche più lento.
Per migliorare l'ordine, puoi creare un indice di copertura separato su datetime :
CREATE INDEX ix_mytable_datetime ON mytable (datetime) INCLUDE (field1, field2, …)
e includi tutte le colonne che utilizzi nella query in quell'indice.
Questo indice è come una copia shadow della tabella ma con i dati ordinati in un ordine diverso.
Ciò consentirà di eliminare le ricerche delle chiavi (poiché l'indice contiene tutti i dati) che renderanno l'ordine per datetime veloce come quello su id .
Aggiornamento:
Un nuovo post sul blog su questo problema: