Probabilmente hai già trovato una risposta alla tua domanda. Questa risposta serve ad aiutare gli altri che potrebbero imbattersi in questa domanda. Ecco una possibile opzione che può essere utilizzata per risolvere il trasferimento di dati tramite SSIS. Ho presupposto che tu possa ancora creare stringhe di connessione che puntano a entrambi i tuoi server A e B dal pacchetto SSIS. Se questa ipotesi è sbagliata, per favore fatemelo sapere così posso eliminare questa risposta. In questo esempio sto usando SQL Server 2008 R2 come back-end. Dal momento che non ho due server, ho creato due tabelle identiche in diversi Schemas ServerA e ServerB .
Procedura dettagliata:
-
In
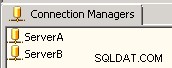
Connection managersezione della SSIS, creare due connessioni OLE DB, ovvero ServerA e ServerB . Questo esempio punta allo stesso server, ma nel tuo scenario le connessioni dovranno puntare ai tuoi due server diversi. Fare riferimento allo screenshot n. 1 . -
Crea due schemi
ServerAeServerB. Crea la tabelladbo.ItemInfoin entrambi gli schemi. Gli script di creazione per queste tabelle sono riportati in Script sezione. Anche in questo caso, questi oggetti sono solo per questo esempio. -
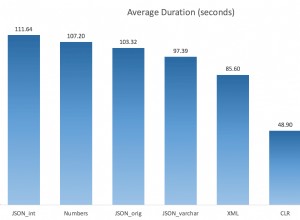
Ho popolato entrambe le tabelle con alcuni dati di esempio. Tabella
ServerA.ItemInfocontiene2,222 rowse la tabellaServerB.ItemInfocontiene10,000 rows. Secondo la domanda, i 7.778 mancanti le righe devono essere trasferite daServerBaServerA. Fare riferimento allo screenshot n. 2 . -
Nella scheda del flusso di controllo del pacchetto SSIS, posiziona un'attività del flusso di dati come mostrato nello screenshot n. 3 .
-
Fare doppio clic sull'attività del flusso di dati per passare alla scheda del flusso di dati e configurare l'attività del flusso di dati come descritto di seguito. Server B è un
OLE DB Source; Trova record nel server A è unLookup transformation taske Server A è unaOLE DB Destination. -
Configura
OLE DB SourceServer B come mostrato negli screenshot #4 e #5 . -
Configura
Lookup transformation taskTrova record nel server A come mostrato negli screenshot #6 - #8 . In questo esempio, ItemId è la chiave univoca. Quindi, questa è la colonna utilizzata per cercare i record mancanti tra le due tabelle. Poiché abbiamo bisogno solo delle righe che non esistono nel Server A , dobbiamo selezionare l'opzioneRedirect rows to no match output. -
Inserisci una
OLE DB Destinationsull'attività di flusso di dati. Quando colleghi l'attività di trasformazione Ricerca con Destinazione OLE DB, ti verrà chiesto conInput Output Selectiondialogo. SelezionaLookup No Match Outputdalla finestra di dialogo come mostrato nella schermata #9 . Configura laOLE DB DestinationServer A come mostrato negli screenshot #10 e #11 . -
Una volta configurata l'attività del flusso di dati, dovrebbe apparire come mostrato nella schermata n. 12 .
-
L'esecuzione di esempio del pacchetto è mostrata nello screenshot #13 . Come puoi notare, mancano
7,778 rowssono stati trasferiti daServer BalServer A. Fare riferimento allo screenshot n. 14 per visualizzare il conteggio dei record della tabella dopo l'esecuzione del pacchetto. -
Poiché il requisito consisteva nell'inserire solo i record mancanti, è stato utilizzato questo approccio. Se desideri aggiornare i record esistenti ed eliminare i record che non sono più validi, fai riferimento all'esempio che ho fornito in questo link. SQL Integration Services per caricare un file delimitato da tabulazioni? L'esempio nel collegamento mostra come trasferire un file flat in SQL ma aggiorna i record esistenti ed elimina i record non validi. Inoltre, l'esempio è stato ottimizzato per gestire un numero elevato di righe.
Spero di esserti stato d'aiuto.
Script
.
CREATE SCHEMA [ServerA] AUTHORIZATION [dbo]
GO
CREATE SCHEMA [ServerB] AUTHORIZATION [dbo]
GO
CREATE TABLE [ServerA].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
CREATE TABLE [ServerB].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
Schermata n. 1:
Schermata n. 2:

Schermata n. 3:

Schermata n. 4:

Schermata n. 5:

Schermata n. 6:

Schermata n. 7:

Schermata n. 8:

Schermata n. 9:

Schermata n. 10:

Schermata n. 11:

Schermata n. 12:
Schermata n. 13:

Schermata n. 14: