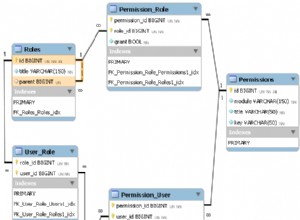
I costi delle sottostrutture dovrebbero essere presi con le dovute precauzioni (soprattutto quando si hanno enormi errori di cardinalità). SET STATISTICS IO ON; SET STATISTICS TIME ON; l'output è un indicatore migliore delle prestazioni effettive.
L'ordinamento riga zero non richiede l'87% delle risorse. Questo problema nel tuo piano è di stima statistica. I costi indicati nel piano effettivo sono ancora costi stimati. Non li adatta per tenere conto di ciò che è realmente accaduto.
C'è un punto nel piano in cui un filtro riduce 1.911.721 righe a 0 ma le righe stimate per il futuro sono 1.860.310. Successivamente tutti i costi sono fasulli e culminano nel costo dell'87% stimato in 3.348.560 righe di ordinamento.
L'errore di stima della cardinalità può essere riprodotto al di fuori di Merge dichiarazione guardando il piano stimato per il Full Outer Join con predicati equivalenti (fornisce la stessa stima di 1.860.310 righe).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Detto questo, tuttavia, il piano fino al filtro stesso sembra abbastanza non ottimale. Sta eseguendo una scansione completa dell'indice cluster quando forse si desidera un piano con 2 ricerche di intervalli di indici cluster. Uno per recuperare la singola riga abbinata alla chiave primaria dal join sull'origine e l'altro per recuperare il T.Key1 = @id range (anche se forse questo serve per evitare la necessità di ordinare in un secondo momento l'ordine delle chiavi in cluster?)
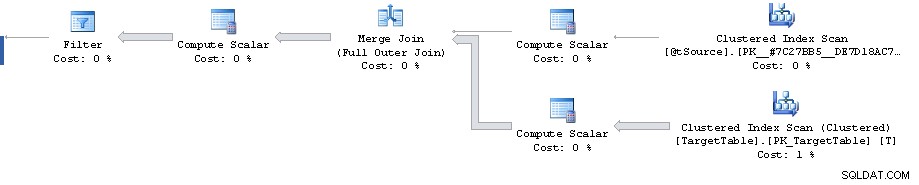
Forse potresti provare questa riscrittura e vedere se funziona meglio o peggio
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;