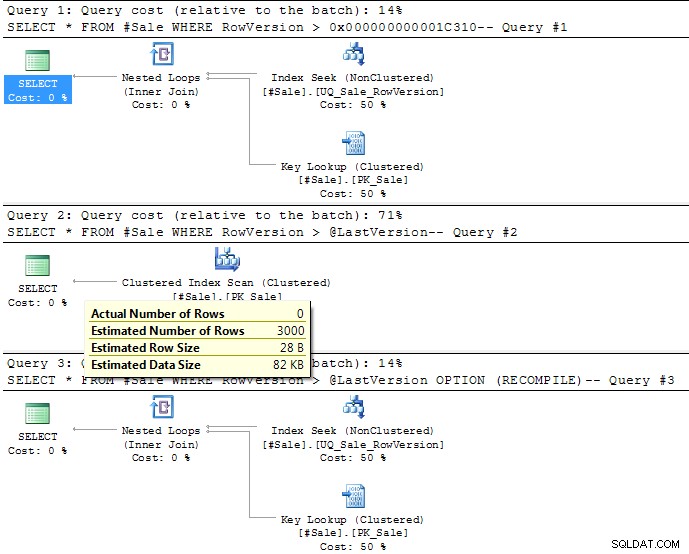
La query 2 utilizza una variabile.
Nel momento in cui il batch viene compilato, SQL Server non conosce il valore della variabile, quindi torna semplicemente a un'euristica molto simile a OPTIMIZE FOR (UNKNOWN)
Per > presupporrà che il 30% delle righe finirà per corrispondere (o 3000 righe nei dati di esempio). Questo può essere visto nell'immagine del piano di esecuzione come di seguito. Questo è significativamente al di sopra delle 12 righe (0,12%) che è il punto di svolta
per questa query se utilizza una scansione dell'indice cluster o una ricerca dell'indice non cluster e ricerche di chiavi.
Dovresti usare OPTION (RECOMPILE) per far sì che tenga conto del valore effettivo della variabile come indicato nel terzo piano sottostante.
Sceneggiatura
CREATE TABLE #Sale
(
SaleId INT IDENTITY(1, 1)
CONSTRAINT PK_Sale PRIMARY KEY,
Test1 VARCHAR(10) NULL,
RowVersion rowversion NOT NULL
CONSTRAINT UQ_Sale_RowVersion UNIQUE
)
/*A better way of populating the table!*/
INSERT INTO #Sale (Test1)
SELECT TOP 10000 NULL
FROM master..spt_values v1, master..spt_values v2
GO
SELECT *
FROM #Sale
WHERE RowVersion > 0x000000000001C310-- Query #1
DECLARE @LastVersion rowversion = 0x000000000001C310
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion-- Query #2
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion
OPTION (RECOMPILE)-- Query #3
DROP TABLE #Sale