SQL Server 2008 ha introdotto colonne sparse come metodo per ridurre lo spazio di archiviazione per i valori Null e fornire schemi più estensibili. Il compromesso è che c'è un sovraccarico aggiuntivo quando si archiviano e si recuperano valori non NULL. Mi interessava capire il costo per l'archiviazione di valori non NULL, dopo aver parlato con un cliente che utilizzava questo tipo di dati in un ambiente di gestione temporanea. Stanno cercando di ottimizzare le prestazioni di scrittura e mi chiedevo se l'uso di colonne sparse avesse qualche effetto, poiché il loro metodo richiedeva l'inserimento di una riga nella tabella, quindi l'aggiornamento. Ho creato un esempio inventato per questa demo, spiegato di seguito, per determinare se questa fosse una buona metodologia da utilizzare.
Revisione interna
Come rapida rassegna, ricorda che quando crei una colonna per una tabella che consente valori NULL, se si tratta di una colonna a lunghezza fissa (ad esempio un INT), consumerà sempre l'intera larghezza della colonna sulla pagina anche quando la colonna è NULLO. Se si tratta di una colonna di lunghezza variabile (ad es. VARCHAR), consumerà almeno due byte nell'array di offset della colonna quando NULL, a meno che le colonne non siano dopo l'ultima colonna popolata (vedi il post del blog di Kimberly L'ordine delle colonne non ha importanza... in genere , ma – DIPENDE). Una colonna sparsa non richiede spazio nella pagina per i valori NULL, indipendentemente dal fatto che si tratti di una colonna a lunghezza fissa o variabile e indipendentemente dalle altre colonne popolate nella tabella. Il compromesso è che quando una colonna sparsa viene popolata, sono necessari quattro (4) byte di memoria in più rispetto a una colonna non sparsa. Ad esempio:
| Tipo di colonna | Requisito di archiviazione |
|---|---|
| Colonna BIGINT, non sparsa, con no valore | 8 byte |
| Colonna BIGINT, non sparsa, con un valore | 8 byte |
| Colonna BIGINT, sparsa, con no valore | 0 byte |
| Colonna BIGINT, sparsa, con un valore | 12 byte |
Pertanto, è essenziale confermare che il vantaggio di archiviazione supera il potenziale impatto sulle prestazioni del recupero, che potrebbe essere trascurabile in base all'equilibrio di letture e scritture rispetto ai dati. Il risparmio di spazio stimato per i diversi tipi di dati è documentato nel collegamento alla documentazione in linea fornito sopra.
Scenari di prova
Ho impostato quattro diversi scenari per il test, descritti di seguito, e ogni tabella aveva una colonna ID (INT), una colonna Nome (VARCHAR(100)) e una colonna Tipo (INT), quindi 997 colonne NULLABLE.
| ID test | Descrizione tabella | Operazioni DML |
|---|---|---|
| 1 | 997 colonne di tipo di dati INT, NULLABLE, non sparse | Inserisci una riga alla volta, compilando ID, Nome, Tipo e dieci (10) colonne NULLABLE casuali |
| 2 | 997 colonne di tipo dati INT, NULLABLE, sparse | Inserisci una riga alla volta, compilando ID, Nome, Tipo e dieci (10) colonne NULLABLE casuali |
| 3 | 997 colonne di tipo di dati INT, NULLABLE, non sparse | Inserisci una riga alla volta, compilando ID, Nome, Solo tipo, quindi aggiorna la riga, aggiungendo valori per dieci (10) colonne NULLABLE casuali |
| 4 | 997 colonne di tipo dati INT, NULLABLE, sparse | Inserisci una riga alla volta, compilando ID, Nome, Solo tipo, quindi aggiorna la riga, aggiungendo valori per dieci (10) colonne NULLABLE casuali |
| 5 | 997 colonne di tipo di dati VARCHAR, NULLABLE, non sparse | Inserisci una riga alla volta, compilando ID, Nome, Tipo e dieci (10) colonne NULLABLE casuali |
| 6 | 997 colonne di tipo di dati VARCHAR, NULLABLE, sparse | Inserisci una riga alla volta, compilando ID, Nome, Tipo e dieci (10) colonne NULLABLE casuali |
| 7 | 997 colonne di tipo di dati VARCHAR, NULLABLE, non sparse | Inserisci una riga alla volta, compilando ID, Nome, Solo tipo, quindi aggiorna la riga, aggiungendo valori per dieci (10) colonne NULLABLE casuali |
| 8 | 997 colonne di tipo di dati VARCHAR, NULLABLE, sparse | Inserisci una riga alla volta, compilando ID, Nome, Solo tipo, quindi aggiorna la riga, aggiungendo valori per dieci (10) colonne NULLABLE casuali |
Ciascun test è stato eseguito due volte con un set di dati di 10 milioni di righe. Gli script allegati possono essere utilizzati per replicare i test e i passaggi sono stati i seguenti per ciascun test:
- Crea un nuovo database con dati predimensionati e file di registro
- Crea la tabella appropriata
- Statistiche di attesa snapshot e statistiche di file
- Annota l'ora di inizio
- Esegui il DML (un inserto o un inserto e un aggiornamento) per 10 milioni di righe
- Nota il tempo di sosta
- Statistiche di attesa istantanea e statistiche sui file e scrivi in una tabella di registrazione in un database separato su una memoria separata
- Istantanea dm_db_index_physical_stats
- Elimina il database
Il test è stato eseguito su un Dell PowerEdge R720 con 64 GB di memoria e 12 GB allocati all'istanza CU4 di SQL Server 2014 SP1. Gli SSD Fusion-IO sono stati utilizzati per l'archiviazione dei dati per i file di database.
Risultati
I risultati dei test sono presentati di seguito per ogni scenario di test.
Durata
In tutti i casi, è stato necessario meno tempo (in media 11,6 minuti) per popolare la tabella quando sono state utilizzate colonne sparse, anche quando la riga è stata prima inserita e quindi aggiornata. Quando la riga è stata inserita per la prima volta, quindi aggiornata, l'esecuzione del test ha richiesto quasi il doppio del tempo rispetto a quando è stata inserita la riga, poiché è stato eseguito il doppio delle modifiche ai dati.
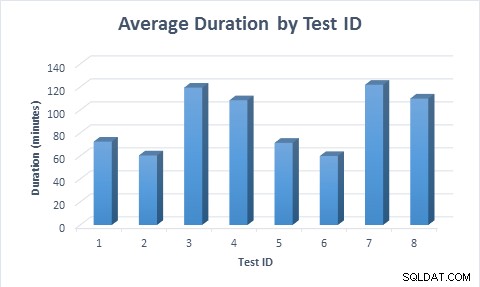 Durata media per ogni scenario di test
Durata media per ogni scenario di test
Statistiche di attesa
| ID test | Percentuale media | Attesa media (secondi) |
|---|---|---|
| 1 | 16.47 | 0,0001 |
| 2 | 14:00 | 0,0001 |
| 3 | 16.65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12.80 | 0,0001 |
| 6 | 13.99 | 0,0001 |
| 7 | 14.85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Le statistiche di attesa erano coerenti per tutti i test e non è possibile trarre conclusioni sulla base di questi dati. L'hardware ha soddisfatto a sufficienza le richieste di risorse in tutti i casi di test.
Statistiche del file
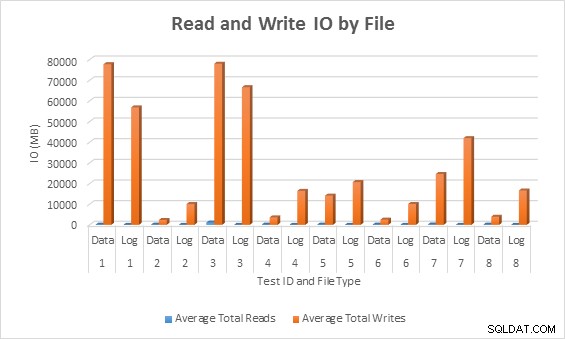 IO medio (lettura e scrittura) per file di database
IO medio (lettura e scrittura) per file di database
In tutti i casi, i test con colonne sparse hanno generato meno I/O (in particolare scritture) rispetto alle colonne non sparse.
Indice statistiche fisiche
| Cassa di prova | Conteggio righe | Numero totale di pagine (indice cluster) | Spazio totale (GB) | Spazio medio utilizzato per le pagine foglia in CI (%) | Dimensione media del record (byte) |
|---|---|---|---|---|---|
| 1 | 10.000.000 | 10.037.312 | 76 | 51.70 | 4.184,49 |
| 2 | 10.000.000 | 301.429 | 2 | 98.51 | 237,50 |
| 3 | 10.000.000 | 10.037.312 | 76 | 51.70 | 4.184,50 |
| 4 | 10.000.000 | 460.960 | 3 | 64.41 | 237,50 |
| 5 | 10.000.000 | 1.823.083 | 13 | 90.31 | 1.326,08 |
| 6 | 10.000.000 | 324.162 | 2 | 98.40 | 255,28 |
| 7 | 10.000.000 | 3.161.224 | 24 | 52.09 | 1.326,39 |
| 8 | 10.000.000 | 503.592 | 3 | 63.33 | 255,28 |
Esistono differenze significative nell'uso dello spazio tra le tabelle non sparse e sparse. Ciò è particolarmente evidente quando si esaminano i casi di test 1 e 3, in cui è stato utilizzato un tipo di dati a lunghezza fissa (INT), rispetto ai casi di test 5 e 7, in cui è stato utilizzato un tipo di dati a lunghezza variabile (VARCHAR(255)). Le colonne intere consumano spazio su disco anche quando NULL. Le colonne a lunghezza variabile consumano meno spazio su disco, poiché nell'array offset vengono utilizzati solo due byte per le colonne NULL e nessun byte per quelle colonne NULL che si trovano dopo l'ultima colonna popolata della riga.
Inoltre, il processo di inserimento di una riga e successivo aggiornamento provoca la frammentazione per il test della colonna a lunghezza variabile (caso 7), rispetto al semplice inserimento della riga (caso 5). La dimensione della tabella quasi raddoppia quando l'inserto è seguito dall'aggiornamento, a causa delle divisioni di pagina che si verificano durante l'aggiornamento delle righe, il che lascia le pagine piene a metà (rispetto al 90% di piene).
Riepilogo
In conclusione, osserviamo una significativa riduzione dello spazio su disco e dell'IO quando vengono utilizzate colonne sparse e hanno prestazioni leggermente migliori rispetto alle colonne non sparse nei nostri semplici test di modifica dei dati (si noti che dovrebbero essere considerate anche le prestazioni di recupero; forse l'oggetto di un altro posta).
Le colonne sparse hanno uno scenario di utilizzo molto specifico ed è importante esaminare la quantità di spazio su disco risparmiato, in base al tipo di dati per la colonna e al numero di colonne che verranno in genere popolate nella tabella. Nel nostro esempio, avevamo 997 colonne sparse e ne abbiamo popolate solo 10. Al massimo, nel caso in cui il tipo di dati utilizzato fosse intero, una riga a livello foglia dell'indice cluster consumerebbe 188 byte (4 byte per l'ID, 100 byte al massimo per il nome, 4 byte per il tipo e quindi 80 byte per 10 colonne). Quando 997 colonne non erano sparse, venivano allocati 4 byte per ogni colonna, anche quando NULL, quindi ogni riga era almeno 4.000 byte a livello di foglia. Nel nostro scenario, le colonne sparse sono assolutamente accettabili. Ma se abbiamo popolato 500 o più colonne sparse con valori per una colonna INT, il risparmio di spazio viene perso e le prestazioni delle modifiche potrebbero non essere più migliori.
A seconda del tipo di dati per le colonne e del numero previsto di colonne da compilare rispetto al totale, potresti voler eseguire test simili per garantire che, quando si utilizzano colonne sparse, le prestazioni di inserimento e l'archiviazione siano comparabili o migliori rispetto a quando si utilizzano colonne non sparse -colonne sparse. Per i casi in cui non tutte le colonne sono popolate, vale sicuramente la pena considerare le colonne sparse.