Nel mio ultimo post, ho iniziato una serie per coprire i controlli di integrità proattivi che sono vitali per il tuo SQL Server. Abbiamo iniziato con lo spazio su disco e in questo post parleremo delle attività di manutenzione. Una delle responsabilità fondamentali di un DBA è garantire che le seguenti attività di manutenzione vengano eseguite regolarmente:
- Backup
- Controlli di integrità
- Manutenzione dell'indice
- Aggiornamenti delle statistiche
La mia scommessa è che hai già dei lavori in atto per gestire queste attività. E scommetto anche che hai le notifiche configurate per inviare un'e-mail a te e al tuo team se un lavoro fallisce. Se entrambi sono veri, allora sei già proattivo riguardo alla manutenzione. E se non stai facendo entrambe le cose, è qualcosa da risolvere in questo momento:smetti di leggere questo, scarica gli script di Ola Hallengren, pianificali e assicurati di impostare le notifiche. (Un'altra alternativa specifica per la manutenzione degli indici, che consigliamo anche ai clienti, è SQL Sentry Fragmentation Manager.)
Se non sai se i tuoi lavori sono impostati per inviarti un'e-mail in caso di errore, utilizza questa query:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Tuttavia, essere proattivi riguardo alla manutenzione fa un ulteriore passo avanti. Oltre ad assicurarti che i tuoi lavori vengano eseguiti, devi sapere quanto tempo impiegano. Puoi utilizzare le tabelle di sistema in msdb per monitorare questo:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Oppure, se stai utilizzando gli script e le informazioni di registrazione di Ola, puoi interrogare la sua tabella CommandLog:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Lo script precedente elenca la durata del backup per ogni backup completo per il database AdventureWorks2014. È possibile prevedere che la durata delle attività di manutenzione aumenterà lentamente nel tempo, man mano che i database crescono più grandi. Pertanto, stai cercando grandi aumenti o diminuzioni impreviste della durata. Ad esempio, avevo un cliente con una durata media del backup inferiore a 30 minuti. All'improvviso, i backup iniziano a richiedere più di un'ora. Il database non era cambiato in modo significativo in termini di dimensioni, nessuna impostazione era cambiata per l'istanza o il database, nulla era cambiato con la configurazione dell'hardware o del disco. Poche settimane dopo, la durata del backup è scesa a meno di mezz'ora. Un mese dopo, risalirono di nuovo. Alla fine abbiamo correlato la modifica della durata del backup ai failover tra i nodi del cluster. Su un nodo, i backup hanno richiesto meno di mezz'ora. Dall'altro, hanno impiegato più di un'ora. Una piccola indagine sulla configurazione delle NIC e del tessuto SAN e siamo stati in grado di individuare il problema.
È importante anche comprendere il tempo medio di esecuzione per le operazioni CHECKDB. Questo è qualcosa di cui Paul parla nel nostro Evento Immersion High Availability e Disaster recovery:devi sapere quanto tempo normalmente impiega CHECKDB per essere eseguito, in modo che se trovi un danneggiamento ed esegui un controllo sull'intero database, sai quanto tempo dovrebbe prendere per CHECKDB per completare. Quando il tuo capo chiede:"Quanto ancora prima di conoscere l'entità del problema?" sarai in grado di fornire una risposta quantitativa del tempo minimo che dovrai aspettare. Se CHECKDB impiega più tempo del solito, allora sai che ha trovato qualcosa (che potrebbe non essere necessariamente un danneggiamento; devi sempre lasciare che il controllo finisca).
Ora, se gestisci centinaia di database, non vuoi eseguire la query precedente per ogni database o ogni lavoro. Invece, potresti semplicemente voler trovare lavori che non rientrano nella durata media di una certa percentuale, che puoi ottenere utilizzando questa query:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Questa query elenca i lavori che hanno richiesto il 25% in più rispetto alla media. La query richiederà alcune modifiche per fornire le informazioni specifiche che desideri:alcuni lavori con una durata ridotta (ad esempio meno di 5 minuti) verranno visualizzati se richiedono solo pochi minuti in più, questo potrebbe non essere un problema. Tuttavia, questa query è un buon inizio e renditi conto che ci sono molti modi per trovare le deviazioni:puoi anche confrontare ogni esecuzione con quella precedente e cercare lavori che hanno richiesto una certa percentuale in più rispetto al precedente.
Ovviamente, la durata del lavoro è l'identificatore più logico da utilizzare per potenziali problemi, che si tratti di un lavoro di backup, di un controllo di integrità o del lavoro che rimuove la frammentazione e aggiorna le statistiche. Ho scoperto che la più grande variazione di durata è in genere nelle attività per rimuovere la frammentazione e aggiornare le statistiche. A seconda delle tue soglie di riorganizzazione rispetto alla ricostruzione e della volatilità dei tuoi dati, potresti passare giorni con principalmente riorganizzazioni, quindi improvvisamente avere un paio di ricostruzioni di indici per tabelle di grandi dimensioni, in cui quelle ricostruzioni alterano completamente la durata media. Potresti voler modificare le soglie per alcuni indici o regolare il fattore di riempimento, in modo che le ricostruzioni avvengano più spesso o meno, a seconda dell'indice e del livello di frammentazione. Per apportare queste modifiche, devi guardare con quale frequenza ogni indice viene ricostruito o riorganizzato, cosa che puoi fare solo se stai usando gli script di Ola e stai registrando nella tabella CommandLog, o se hai lanciato la tua soluzione e stai registrando ogni riorganizzazione o ricostruzione. Per vedere questo utilizzando la tabella CommandLog, puoi iniziare controllando per vedere quali indici vengono modificati più spesso:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Da questo output, puoi iniziare a vedere quali tabelle (e quindi indici) hanno la maggiore volatilità e quindi determinare se la soglia per la riorganizzazione rispetto alla ricostruzione deve essere modificata o il fattore di riempimento modificato.
Semplificare la vita
Ora esiste una soluzione più semplice rispetto alla scrittura delle proprie query, purché si utilizzi SQL Sentry Event Manager (EM). Lo strumento monitora tutti i lavori dell'agente impostati su un'istanza e, utilizzando la visualizzazione del calendario, puoi vedere rapidamente quali lavori non sono riusciti, sono stati annullati o sono stati eseguiti più a lungo del solito:
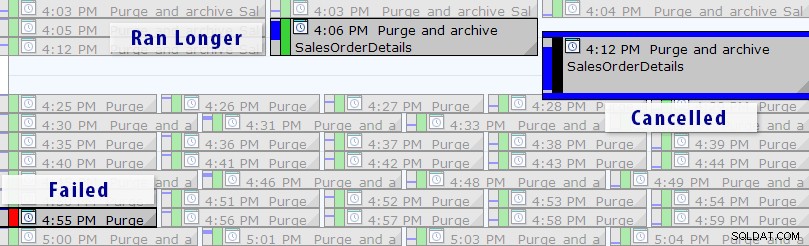 Vista calendario di SQL Sentry Event Manager (con etichette aggiunte in Photoshop)
Vista calendario di SQL Sentry Event Manager (con etichette aggiunte in Photoshop)
Puoi anche approfondire le singole esecuzioni per vedere quanto tempo ci è voluto per l'esecuzione di un lavoro e ci sono anche utili grafici di runtime che ti consentono di visualizzare rapidamente eventuali modelli di anomalie di durata o condizioni di errore. In questo caso, posso vedere che circa ogni 15 minuti, la durata del runtime per questo lavoro specifico è aumentata di quasi il 400%:
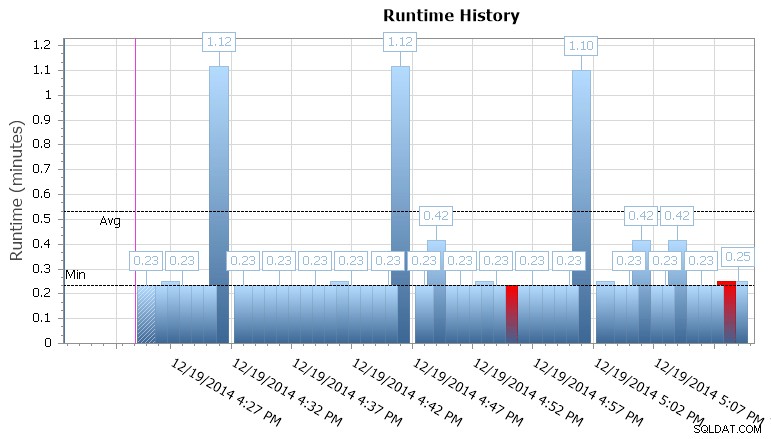 Grafico di runtime di SQL Sentry Event Manager
Grafico di runtime di SQL Sentry Event Manager
Questo mi dà un indizio che dovrei esaminare altri lavori programmati che potrebbero causare alcuni problemi di concorrenza qui. Potrei rimpicciolire nuovamente il calendario per vedere quali altri lavori sono in esecuzione nello stesso momento, oppure potrei anche non dover cercare di riconoscere che si tratta di un lavoro di reporting o backup che viene eseguito su questo database.
Riepilogo
Scommetto che la maggior parte di voi ha già in atto i lavori di manutenzione necessari e che avete anche impostato le notifiche per gli errori di lavoro. Se non hai familiarità con le durate medie dei tuoi lavori, allora questo è il tuo prossimo passo per essere proattivo. Nota:potresti anche dover controllare per quanto tempo conservi la cronologia dei lavori. Quando cerco deviazioni nella durata del lavoro, preferisco guardare a pochi mesi di dati, piuttosto che a poche settimane. Non è necessario che questi tempi di esecuzione vengano memorizzati, ma una volta verificato che stai conservando dati sufficienti per avere la cronologia da utilizzare per la ricerca, quindi inizia a cercare le variazioni su base regolare. In uno scenario ideale, l'aumento del tempo di esecuzione può avvisarti di un potenziale problema, consentendoti di risolverlo prima che si verifichi un problema nel tuo ambiente di produzione.