Introduzione
In questo articolo verrà illustrato come diversi tipi di indici nelle tabelle ottimizzate per la memoria di SQL Server influiscono sulle prestazioni. Esamineremo esempi di come diversi tipi di indice possono influenzare le prestazioni delle tabelle con ottimizzazione per la memoria.
Per facilitare la discussione dell'argomento, faremo uso di un esempio piuttosto ampio. Per motivi di semplicità, questo esempio presenterà diverse repliche di una singola tabella, su cui eseguiremo query diverse. Queste repliche utilizzeranno indici diversi o nessun indice (tranne, ovviamente, le chiavi primarie, le PK).
Si noti che lo scopo effettivo di questo articolo non è confrontare le prestazioni tra tabelle basate su disco e ottimizzate per la memoria in SQL Server di per sé. Il suo scopo è esaminare come gli indici influiscono sulle prestazioni nelle tabelle con ottimizzazione per la memoria. Tuttavia, per avere un quadro completo degli esperimenti, vengono forniti anche i tempi per le corrispondenti query delle tabelle basate su disco e gli speedup vengono calcolati utilizzando la configurazione più ottimale delle tabelle basate su disco come linee di base.
Scenario
I dati di esempio per il nostro scenario si basano su un'unica tabella definita come segue:
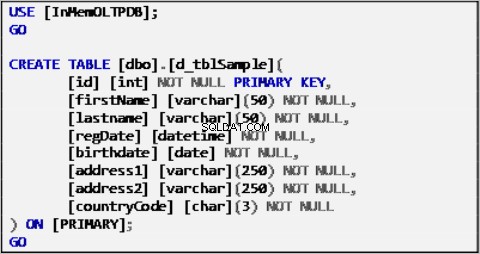
Listato 1:tabella di origine dati di esempio.
La tabella sopra è stata popolata con dati di esempio e fungerà da origine dati per il resto delle tabelle.
Quindi, sulla base della tabella sopra, creiamo le seguenti 9 variazioni di tabella e le popolamo con gli stessi dati di esempio:
- 3 tabelle basate su disco:
- d_tblSample1
- Indice cluster nella colonna "id" - chiave primaria (PK)
- d_tblSample2
- Indice raggruppato nella colonna "id" (PK)
- Indice non cluster nella colonna "countryCode"
- d_tblSample3
- Indice raggruppato nella colonna "id" (PK)
- Indici non cluster nella colonna "regDate"
- Indici non cluster nella colonna "countryCode"
- d_tblSample1
- 3 tabelle ottimizzate per la memoria (set 1:indici hash):
- m1_tblSample1
- Indice hash non cluster nella colonna "id" - chiave primaria (PK)
- m1_tblSample2
- Indice hash non cluster nella colonna "id" (PK)
- Indice hash nella colonna "countryCode"
- m1_tblSample3
- Indice hash non cluster nella colonna "id" (PK)
- Indice hash nella colonna "regDate"
- Indice hash nella colonna "countryCode"
- 3 tabelle ottimizzate per la memoria (set 2:indici non cluster):
- m2_tblSample1
- Indice non cluster nella colonna "id" - chiave primaria (PK)
- m2_tblSample2
- Indice non cluster nella colonna "id" (PK)
- Indice non cluster nella colonna "countryCode"
- m2_tblSample3
- Indice non cluster nella colonna "id" (PK)
- Indice non cluster nella colonna "regDate"
- Indice non cluster nella colonna "countryCode"
- m2_tblSample1
- m1_tblSample1
Negli elenchi seguenti, puoi trovare le definizioni per le tabelle precedenti.
La logica dello scenario prevede che eseguiamo diverse operazioni di database rispetto alle variazioni della stessa tabella (ma con indici diversi) e osserviamo come le prestazioni sono influenzate in ciascun caso.
Definizioni
Tabelle basate su disco
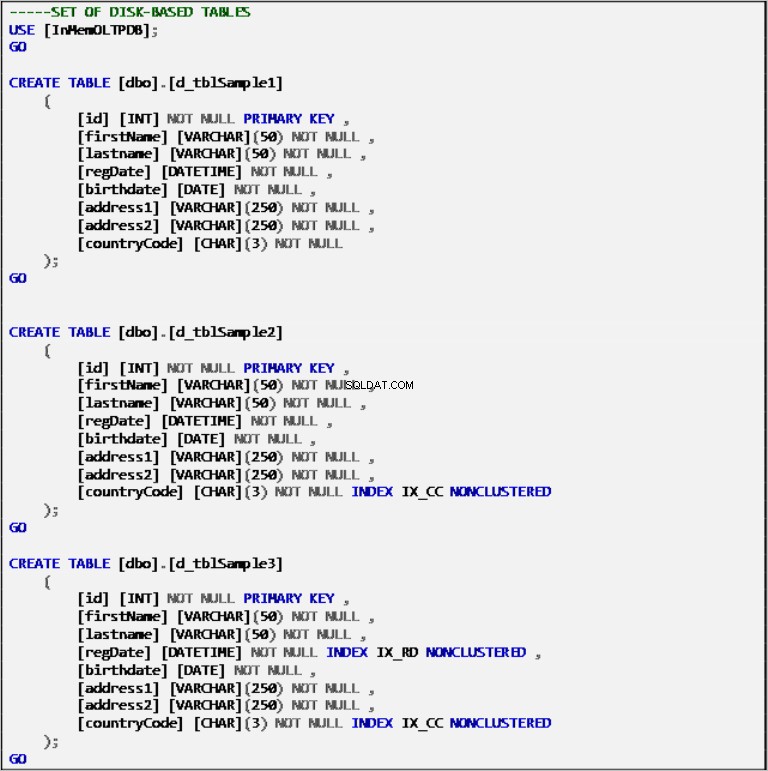
Listato 2:definizione di tabelle basate su disco.
Tabelle ottimizzate per la memoria (set 1:indici hash)

Listato 3:Tabelle con ottimizzazione per la memoria – Set 1 (indici hash).
Tabelle ottimizzate per la memoria (set 2:indici non cluster)

Listato 4:Tabelle con ottimizzazione per la memoria – Set 2 (indici non cluster).
Quindi, popolamo tutte le tabelle precedenti con gli stessi dati di esempio, per un totale di 5 milioni di record in ciascuna tabella.
Ecco l'output del comando count per ogni set di tabelle:
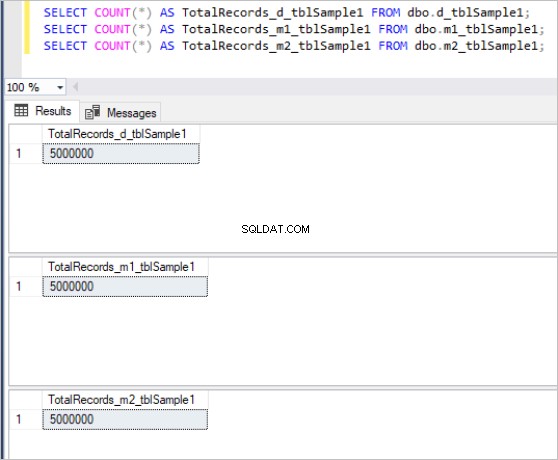
Figura 1:numero totale di record per la prima serie di tabelle.
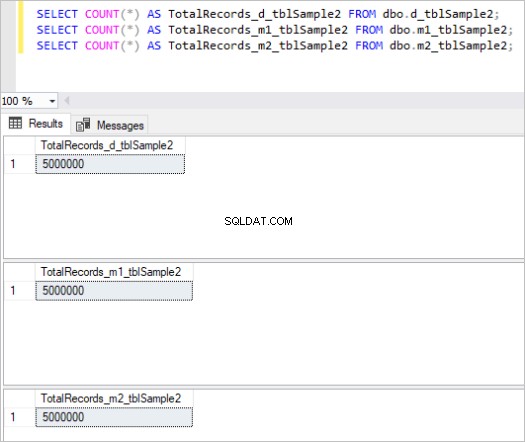
Figura 2:numero totale di record per la seconda serie di tabelle.
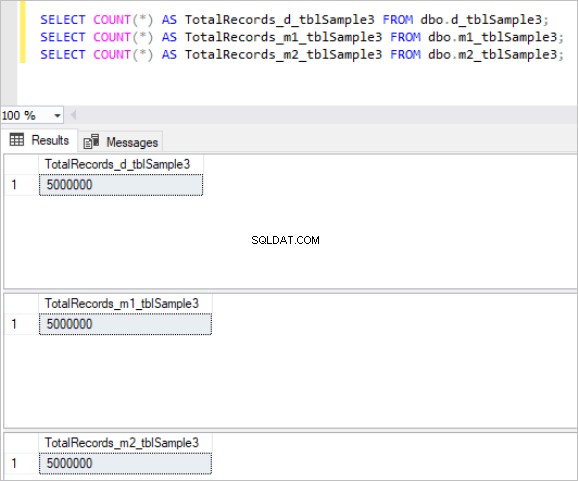
Figura 3:numero totale di record per la terza serie di tabelle.
Query ed esecuzioni di scenari
Ora eseguiremo una serie di query sulle tabelle precedenti e vedremo come si comporta ciascuna tabella.
Queste query eseguono le seguenti operazioni:
- Query 1:Aggregazione (GRUPPO PER)
- Query 2:ricerca dell'indice sui predicati di uguaglianza
- Query 3:ricerca dell'indice sui predicati di uguaglianza e disuguaglianza
Il piano è di eseguire le query come di seguito:
Query 1 – Esecuzione sulle seguenti tabelle:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (nessun indice sulle colonne target)
- m2_tblSample1 (nessun indice sulle colonne target)
Query 2 – Esecuzione sulle seguenti tabelle:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (nessun indice sulle colonne target)
- m2_tblSample1 (nessun indice sulle colonne target)
Query 3 – Esecuzione sulle seguenti tabelle:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (nessun indice sulle colonne target)
- m2_tblSample1 (nessun indice sulle colonne target)
Nota :Anche se la definizione di d_tblSample1 la tabella basata su disco è inclusa nelle definizioni di tabella precedenti, non viene utilizzata nelle query fornite in questo articolo. Il motivo è che, in ogni scenario, viene utilizzata la configurazione più ottimale possibile per la tabella basata su disco, poiché vogliamo che la nostra linea di base sia il più veloce possibile quando la confrontiamo con le prestazioni delle tabelle ottimizzate per la memoria. A tal fine, il d_tblSample1 la tabella è presentata solo a scopo informativo.
Di seguito puoi trovare gli script T-SQL per le tre query insieme ai meccanismi di misurazione del tempo di esecuzione.

Listato 5:Query 1 – Aggregazione (con indici).
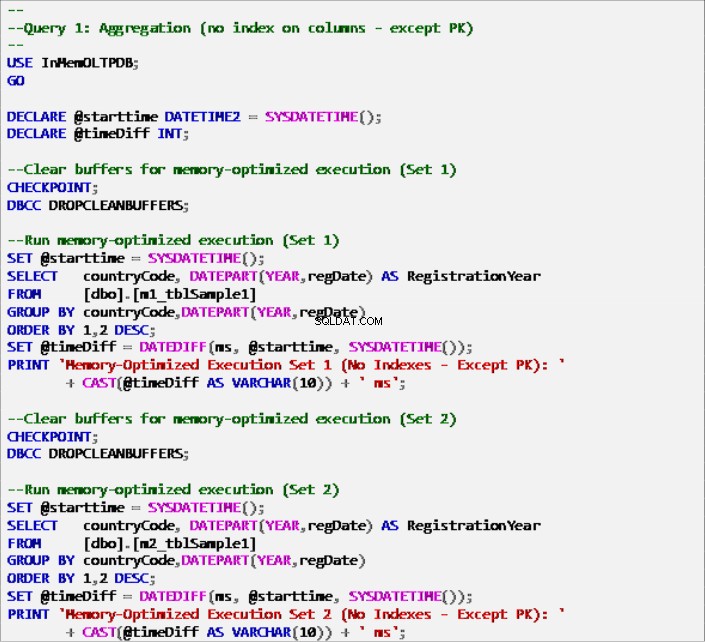
Listato 6:Query 1 – Aggregazione (senza indici – Eccetto chiave primaria).
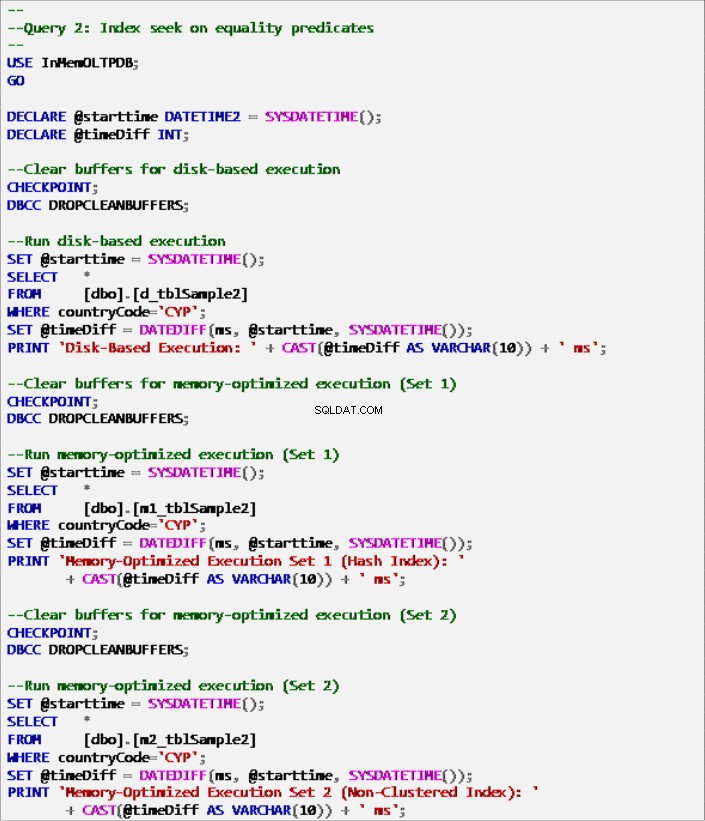
Listato 7:Query 2 – Ricerca dell'indice sui predicati di uguaglianza (con indici).

Listato 8:Query 2 – Ricerca dell'indice sui predicati di uguaglianza (senza indici, eccetto la chiave primaria).
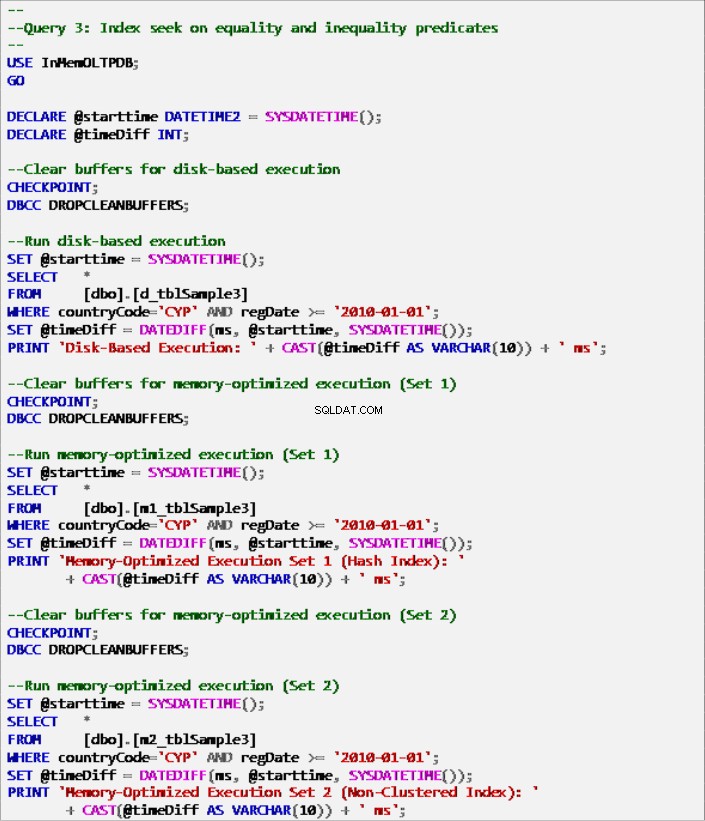
Listato 9:Query 3 – Ricerca dell'indice sui predicati di uguaglianza e disuguaglianza (con indici).

Listato 10:Query 3 – Ricerca dell'indice sui predicati di uguaglianza e disuguaglianza (senza indici – Tranne la chiave primaria).
Gli screenshot seguenti mostrano l'output di ogni esecuzione di query:
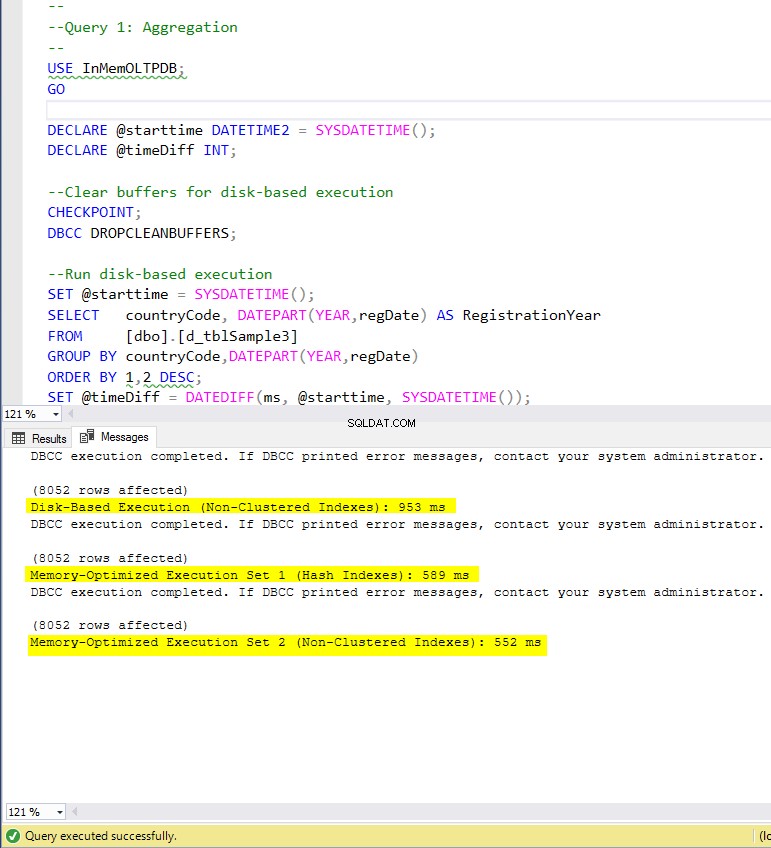
Figura 4:tempo di esecuzione della query 1 (con indici).
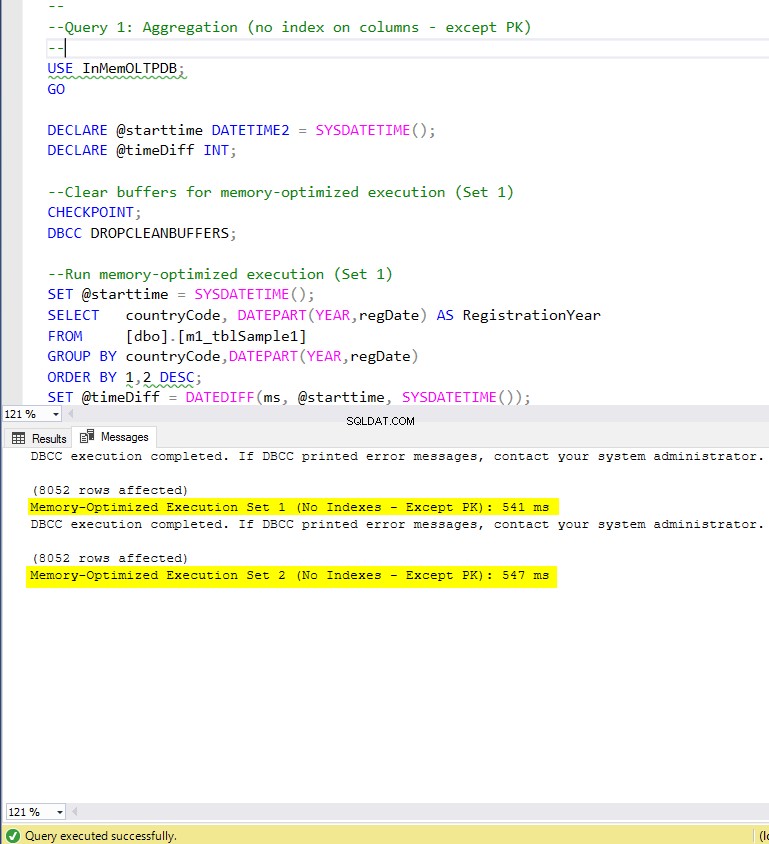
Figura 5:tempo di esecuzione della query 1 (senza indici, eccetto PK).
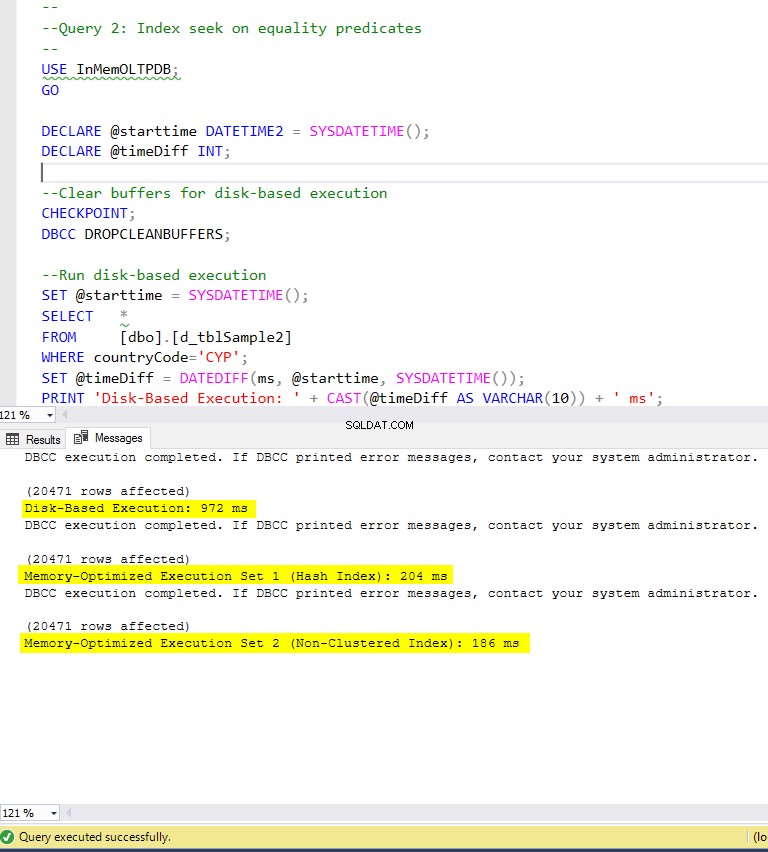
Figura 6:tempo di esecuzione della query 2 (con indici).
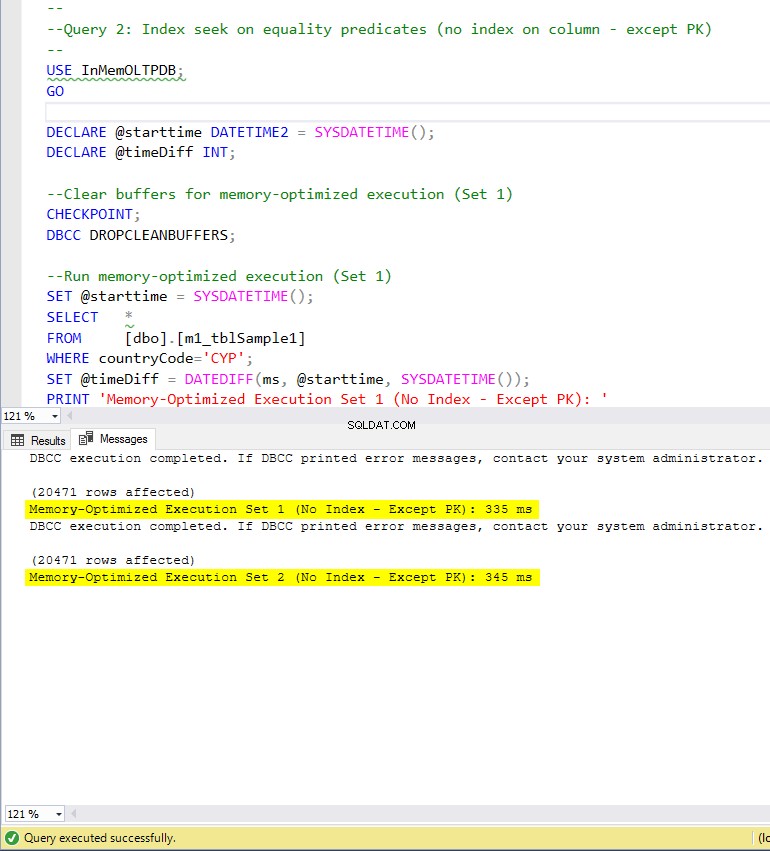
Figura 7:tempo di esecuzione della query 2 (senza indici, tranne PK).
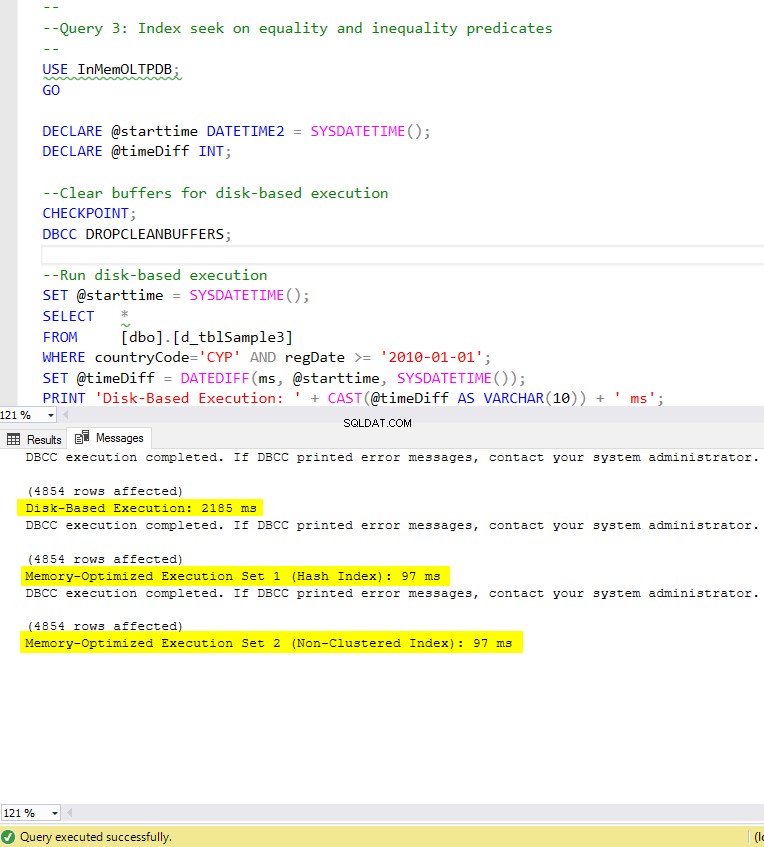
Figura 8:tempo di esecuzione della query 3 (con indici).
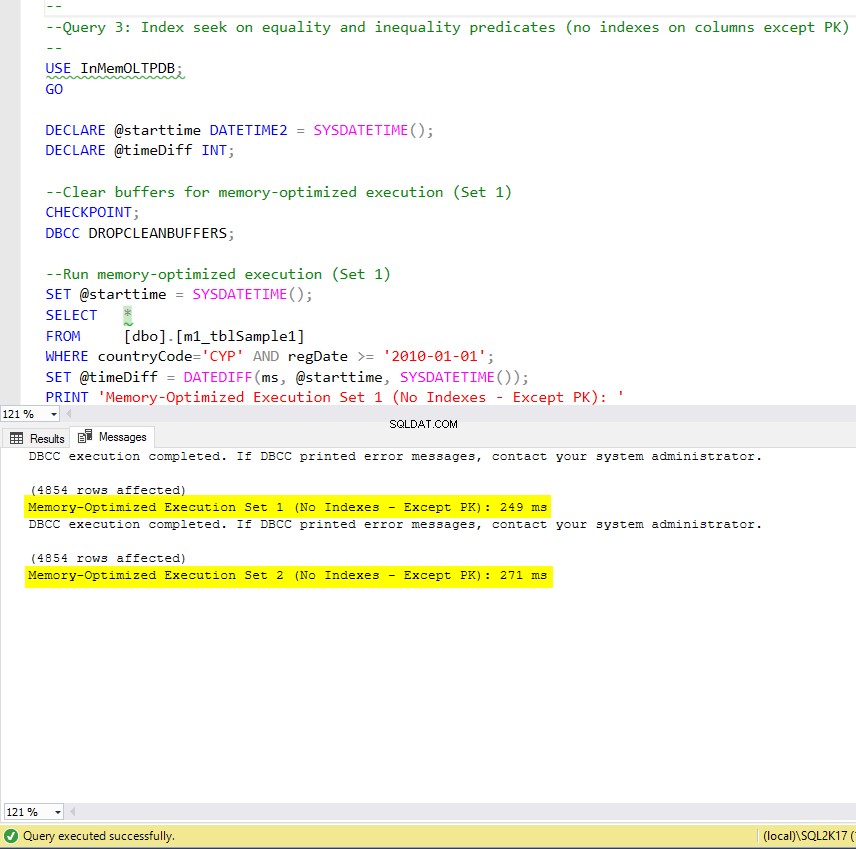
Figura 9:tempo di esecuzione della query 3 (senza indici, tranne PK).
Ora riassumiamo i risultati ottenuti sopra. La tabella seguente mostra i tempi di esecuzione misurati per tutte le query e le combinazioni tabella/indice di cui sopra.
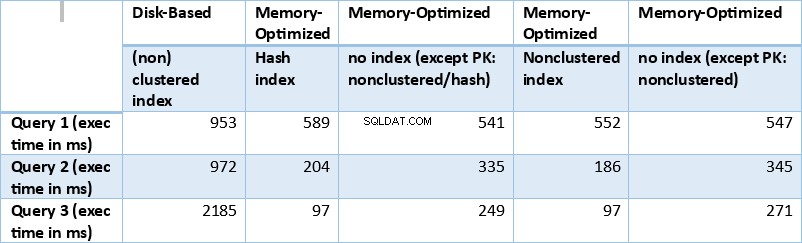
Tabella 1:riepilogo dei tempi di esecuzione (ms) per tutte le query.
Discussione
Se esaminiamo i risultati dell'esecuzione riassunti nella tabella sopra, possiamo giungere ad alcune conclusioni. Tracciamo ogni risultato della query in un grafico. I grafici seguenti illustrano i tempi di esecuzione, nonché la velocità delle tabelle ottimizzate per la memoria rispetto alle tabelle basate su disco.
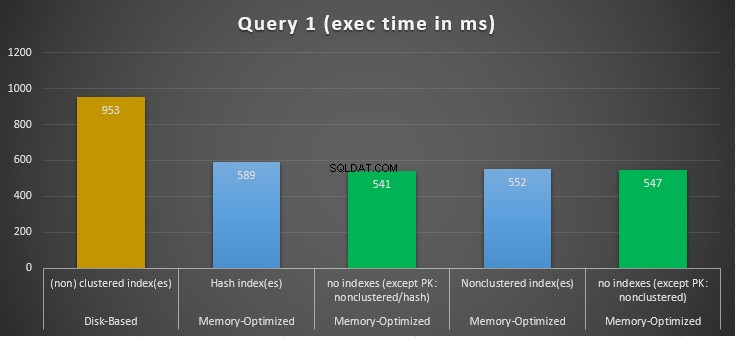
Figura 10:confronto dei tempi di esecuzione della query 1.
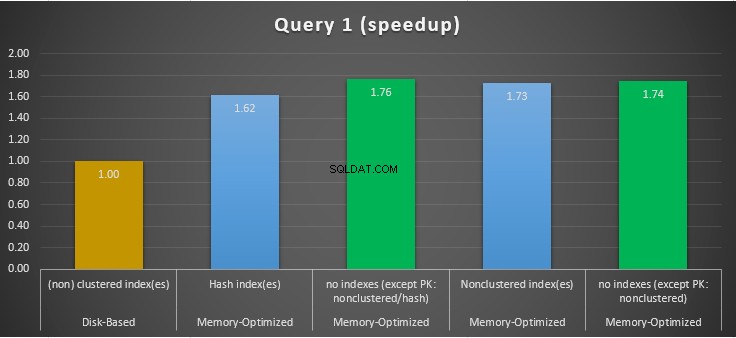
Figura 11:confronto dell'accelerazione della query 1.
Per quanto riguarda la query 1, che era un'aggregazione GROUP BY, possiamo vedere che entrambe le versioni (indici vs nessun indice) di tabelle con ottimizzazione per la memoria, funzionano quasi allo stesso modo avendo una velocità sulla tabella basata su disco (abilitata con indici) tra 1,62 e 1,76 volte più veloce.
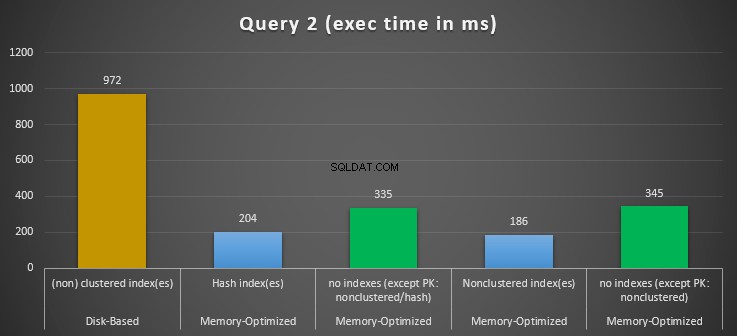
Figura 12:confronto dei tempi di esecuzione della query 2.
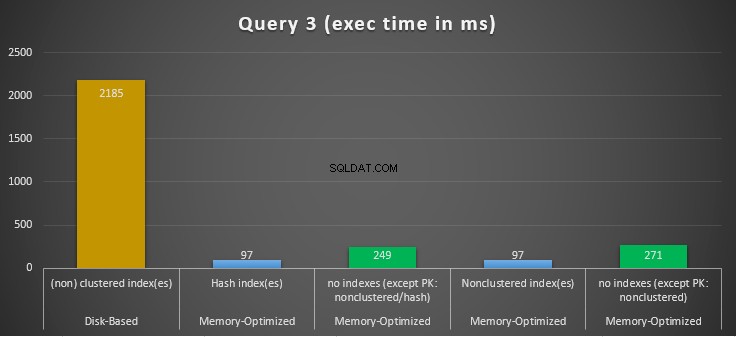
Figura 13:Confronto dell'accelerazione della query 2.
Per quanto riguarda la query 2, che prevedeva una ricerca dell'indice sui predicati di uguaglianza, possiamo vedere che le tabelle ottimizzate per la memoria con indici hanno prestazioni molto migliori rispetto alle tabelle ottimizzate per la memoria senza indici. Inoltre, osserviamo che la tabella ottimizzata per la memoria con indice non cluster nella colonna utilizzata come predicato ha ottenuto risultati migliori rispetto a quella con indice hash.
Quindi, per la query 2, il vincitore è la tabella con ottimizzazione per la memoria con l'indice non cluster, con una velocità complessiva di 5,23 volte più veloce rispetto all'esecuzione basata su disco.
Figura 14:confronto dei tempi di esecuzione della query 3.
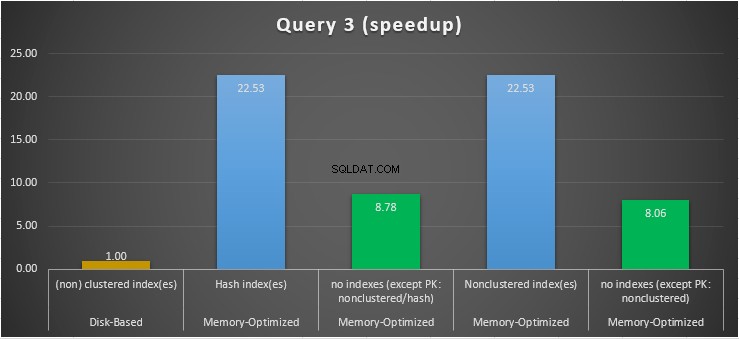
Figura 15:confronto dell'accelerazione della query 3.
Per quanto riguarda la query 3, che prevedeva una ricerca dell'indice sui predicati di uguaglianza e disuguaglianza combinati, possiamo vedere che le tabelle ottimizzate per la memoria con indici hanno funzionato molto meglio delle tabelle ottimizzate per la memoria senza indici. Inoltre, osserviamo che la tabella con ottimizzazione per la memoria con indice non cluster nella colonna utilizzata come predicato si comporta come quella con l'indice hash.
A tal fine, possiamo vedere che entrambe le tabelle con ottimizzazione per la memoria che utilizzano gli indici nelle colonne utilizzate come predicati, hanno ottenuto risultati più rapidi rispetto a quelle prive di indici e hanno raggiunto una velocità di 22,53 volte più veloce sull'esecuzione basata su disco.
Conclusione
In questo articolo è stato esaminato l'utilizzo degli indici nelle tabelle con ottimizzazione per la memoria in SQL Server. Abbiamo utilizzato come base per ogni query la migliore configurazione possibile della tabella basata su disco, quindi abbiamo confrontato le prestazioni di tre query con le tabelle basate su disco e 4 varianti di tabelle ottimizzate per la memoria. Due delle quattro tabelle con ottimizzazione per la memoria utilizzavano indici (hash/non cluster) e le altre due non utilizzavano indici, ad eccezione di quelli utilizzati per le chiavi primarie.
La conclusione generale è che è sempre necessario esaminare in che modo gli indici influiscono sulle prestazioni, non solo per le tabelle ottimizzate per la memoria ma anche per quelle basate su disco, e ogni volta che si identifica che migliorano le prestazioni, utilizzarle. I risultati degli esempi di questo articolo mostrano che se si utilizzano gli indici appropriati nelle tabelle con ottimizzazione per la memoria, è possibile ottenere prestazioni molto migliori per query simili a quelle utilizzate in questo articolo rispetto al solo utilizzo di tabelle con ottimizzazione per la memoria senza indici .
Riferimenti e ulteriori letture:
- Microsoft Docs:tabelle con ottimizzazione per la memoria
- Microsoft Docs:linee guida per l'utilizzo di indici su tabelle con ottimizzazione per la memoria
- Microsoft Docs:indici su tabelle con ottimizzazione per la memoria
Strumento utile:
dbForge Index Manager – pratico componente aggiuntivo SSMS per analizzare lo stato degli indici SQL e risolvere i problemi con la frammentazione degli indici.