Il principio "Non ripetere te stesso" suggerisce di ridurre le ripetizioni. Questa settimana mi sono imbattuto in un caso in cui DRY dovrebbe essere buttato fuori dalla finestra. Ci sono anche altri casi (ad esempio, funzioni scalari), ma questo era interessante che coinvolgeva la logica Bitwise.
Immaginiamo la seguente tabella:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); I bit "WheelFlag" rappresentano le seguenti opzioni:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Quindi le possibili combinazioni sono:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Mettiamo da parte le argomentazioni, almeno per ora, sul fatto se questo debba essere impacchettato in un unico TINYINT in primo luogo, o memorizzato come colonne separate, o utilizzare un modello EAV... la correzione del design è una questione a parte. Si tratta di lavorare con ciò che hai.
Per rendere utili gli esempi, riempiamo questa tabella con una serie di dati casuali. (E assumeremo, per semplicità, che questa tabella contenga solo ordini che non sono ancora stati spediti.) Questo inserirà 50.000 righe di distribuzione più o meno uguale tra le sei combinazioni di opzioni:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Se osserviamo la ripartizione, possiamo vedere questa distribuzione. Nota che i tuoi risultati potrebbero differire leggermente dai miei a seconda degli oggetti nel tuo sistema:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Risultati:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Ora diciamo che è martedì e abbiamo appena ricevuto una spedizione di ruote da 18", che in precedenza erano esaurite. Ciò significa che siamo in grado di soddisfare tutti gli ordini che richiedono ruote da 18", sia quelli che hanno pneumatici aggiornati (6), e quelli che non lo facevano (2). Quindi *potremmo* scrivere una query come la seguente:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Nella vita reale, ovviamente, non puoi davvero farlo; cosa succede se in seguito vengono aggiunte altre opzioni, come i bloccaruota, la garanzia a vita sulle ruote o più opzioni di pneumatici? Non vuoi dover scrivere una serie di valori IN() per ogni possibile combinazione. Possiamo invece scrivere un'operazione BITWISE AND, per trovare tutte le righe dove è impostato il 2° bit, come ad esempio:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Questo mi dà gli stessi risultati della query IN(), ma se li confronto utilizzando SQL Sentry Plan Explorer, le prestazioni sono abbastanza diverse:

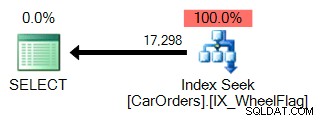
È facile capire perché. Il primo utilizza un index search per isolare le righe che soddisfano la query, con un filtro sulla colonna WheelFlag:

Il secondo utilizza una scansione, insieme a una conversione implicita e statistiche terribilmente imprecise. Tutto merito dell'operatore BITWISE AND:
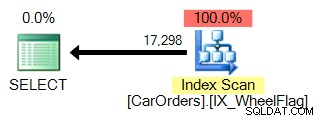


Che cosa significa questo? Al centro, questo ci dice che l'operazione BITWISE AND non è sargable .
Ma ogni speranza non è perduta.
Se ignoriamo per un momento il principio DRY, possiamo scrivere una query leggermente più efficiente essendo un po' ridondante per sfruttare l'indice sulla colonna WheelFlag. Supponendo che stiamo cercando qualsiasi opzione WheelFlag superiore a 0 (nessun aggiornamento), possiamo riscrivere la query in questo modo, dicendo a SQL Server che il valore WheelFlag deve essere almeno lo stesso valore di flag (che elimina 0 e 1 ), e quindi aggiungendo le informazioni supplementari che devono contenere anche quel flag (eliminando così 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
La parte>=di questa clausola è ovviamente coperta dalla parte BITWISE, quindi è qui che violiamo DRY. Ma poiché questa clausola che abbiamo aggiunto è sargable, relegare l'operazione BITWISE AND a una condizione di ricerca secondaria produce comunque lo stesso risultato e la query complessiva fornisce prestazioni migliori. Vediamo un indice simile che cerca la versione codificata della query precedente e, sebbene le stime siano ancora più lontane (qualcosa che potrebbe essere affrontato come un problema separato), le letture sono ancora inferiori rispetto alla sola operazione BITWISE AND:

Possiamo anche vedere che viene utilizzato un filtro contro l'indice, cosa che non abbiamo visto utilizzando l'operazione BITWISE AND da sola:

Conclusione
Non aver paura di ripeterti. Ci sono momenti in cui queste informazioni possono aiutare l'ottimizzatore; anche se potrebbe non essere del tutto intuitivo *aggiungere* criteri per migliorare le prestazioni, è importante capire quando clausole aggiuntive aiutano a ridurre i dati per il risultato finale piuttosto che rendere "facile" per l'ottimizzatore trovare le righe esatte da solo.