Vedo molti consigli là fuori che dicono qualcosa sulla falsariga di "Cambia il cursore su un'operazione basata su set; questo lo renderà più veloce". Anche se spesso può essere così, non è sempre vero. Un caso d'uso che vedo in cui un cursore supera ripetutamente il tipico approccio basato su insiemi è il calcolo dei totali parziali. Questo perché l'approccio basato sugli insiemi di solito deve esaminare alcune parti dei dati sottostanti più di una volta, il che può essere una cosa esponenzialmente negativa man mano che i dati diventano più grandi; mentre un cursore, per quanto doloroso possa sembrare, può scorrere ogni riga/valore esattamente una volta.
Queste sono le nostre opzioni di base nelle versioni più comuni di SQL Server. In SQL Server 2012, tuttavia, sono stati apportati numerosi miglioramenti alle funzioni di windowing e alla clausola OVER, per lo più derivanti da diversi ottimi suggerimenti inviati dal collega MVP Itzik Ben-Gan (ecco uno dei suoi suggerimenti). In effetti, Itzik ha un nuovo libro MS-Press che tratta tutti questi miglioramenti in modo molto più dettagliato, intitolato "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions".
Quindi, naturalmente, ero curioso; la nuova funzionalità di windowing renderebbe obsolete le tecniche del cursore e del self-join? Sarebbero più facili da codificare? Sarebbero più veloci in tutti i casi (non importa tutti)? Quali altri approcci potrebbero essere validi?
La configurazione
Per fare dei test, configuriamo un database:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO E quindi riempire una tabella con 10.000 righe che possiamo utilizzare per eseguire alcuni totali parziali. Niente di troppo complicato, solo una tabella riassuntiva con una riga per ogni data e un numero che rappresenta quante multe per eccesso di velocità sono state emesse. Non ho una multa per eccesso di velocità da un paio d'anni, quindi non so perché questa sia stata la mia scelta inconscia per un modello di dati semplicistico, ma eccolo.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Risultati ridotti:
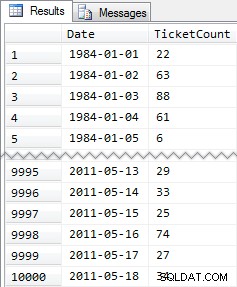
Quindi, di nuovo, 10.000 righe di dati piuttosto semplici:piccoli valori INT e una serie di date dal 1984 al maggio 2011.
Gli Approcci
Ora il mio compito è relativamente semplice e tipico di molte applicazioni:restituire un set di risultati che contiene tutte le 10.000 date, insieme al totale cumulativo di tutti i ticket per eccesso di velocità fino a quella data inclusa. La maggior parte delle persone proverebbe prima qualcosa del genere (lo chiameremo "inner join " metodo):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
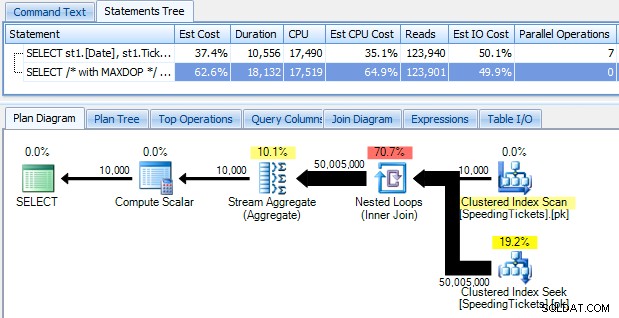
...e rimani scioccato nello scoprire che ci vogliono quasi 10 secondi per funzionare. Esaminiamo rapidamente il motivo visualizzando il piano di esecuzione grafico, utilizzando SQL Sentry Plan Explorer:

Le grandi frecce grosse dovrebbero dare un'indicazione immediata di cosa sta succedendo:il ciclo nidificato legge una riga per la prima aggregazione, due righe per la seconda, tre righe per la terza e così via per l'intero set di 10.000 righe. Ciò significa che dovremmo vedere approssimativamente ((10000 * (10000 + 1)) / 2) righe elaborate una volta che l'intero set è stato attraversato e ciò sembra corrispondere al numero di righe mostrato nel piano.
Si noti che l'esecuzione della query senza parallelismo (usando il suggerimento per la query OPTION (MAXDOP 1)) rende la forma del piano un po' più semplice, ma non aiuta affatto né nel tempo di esecuzione né nell'I/O; come mostrato nel piano, la durata in realtà quasi raddoppia e le letture diminuiscono solo di una percentuale molto piccola. Confronto con il piano precedente:
Ci sono molti altri approcci che le persone hanno provato per ottenere totali parziali efficienti. Un esempio è il "metodo di sottoquery " che usa solo una sottoquery correlata più o meno allo stesso modo del metodo inner join descritto sopra:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Confrontando questi due piani:
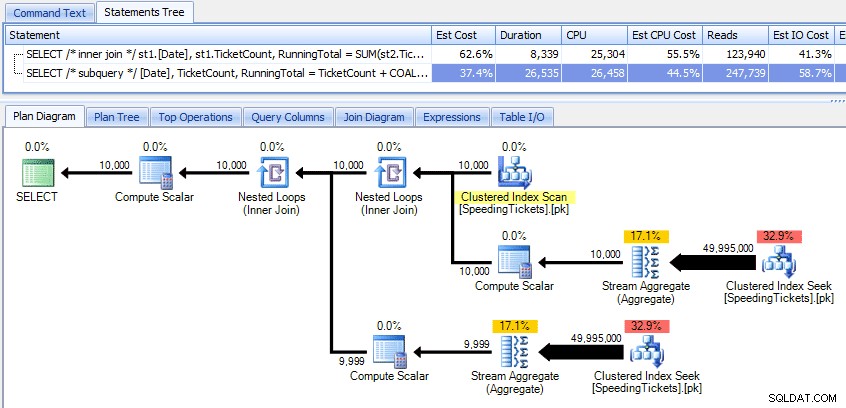
Quindi, mentre il metodo subquery sembra avere un piano generale più efficiente, è peggio dove conta:durata e I/O. Possiamo vedere cosa contribuisce a questo scavando un po' più a fondo nei piani. Passando alla scheda Operazioni principali, possiamo vedere che nel metodo inner join, la ricerca dell'indice cluster viene eseguita 10.000 volte e tutte le altre operazioni vengono eseguite solo poche volte. Tuttavia, diverse operazioni vengono eseguite 9.999 o 10.000 volte nel metodo della sottoquery:
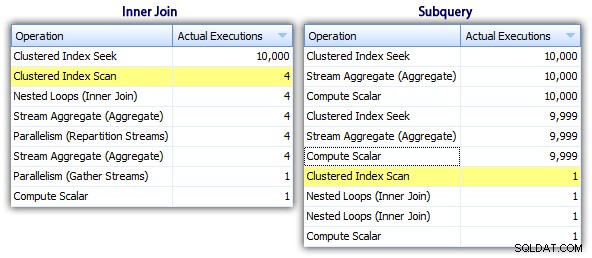
Quindi, l'approccio subquery sembra essere peggiore, non migliore. Il prossimo metodo che proveremo, lo chiamerò "aggiornamento stravagante " metodo. Questo non è esattamente garantito per funzionare e non lo consiglierei mai per il codice di produzione, ma lo sto includendo per completezza. Fondamentalmente l'eccentrico aggiornamento sfrutta il fatto che durante un aggiornamento puoi reindirizzare l'assegnazione e la matematica così che la variabile incrementi dietro le quinte man mano che ogni riga viene aggiornata.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Riaffermerò che non credo che questo approccio sia sicuro per la produzione, indipendentemente dalla testimonianza che sentirai da persone che indicano che "non fallisce mai". A meno che il comportamento non sia documentato e garantito, cerco di stare lontano da ipotesi basate sul comportamento osservato. Non si sa mai quando alcune modifiche al percorso decisionale dell'ottimizzatore (basato su una modifica delle statistiche, una modifica dei dati, un service pack, un flag di traccia, un suggerimento per la query, che cos'è) modificheranno drasticamente il piano e potenzialmente porteranno a un ordine diverso. Se ti piace davvero questo approccio non intuitivo, puoi farti sentire un po' meglio usando l'opzione di query FORCE ORDER (e questo proverà a utilizzare una scansione ordinata del PK, poiché questo è l'unico indice idoneo sulla variabile della tabella):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Per un po' più di sicurezza a un costo di I/O leggermente superiore, puoi riportare in gioco la tabella originale e assicurarti che venga utilizzata la PK sulla tabella di base:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Personalmente non penso che sia molto più garantito, poiché la parte SET dell'operazione potrebbe potenzialmente influenzare l'ottimizzatore indipendentemente dal resto della query. Ancora una volta, non sto raccomandando questo approccio, sto solo includendo il confronto per completezza. Ecco il piano da questa query:
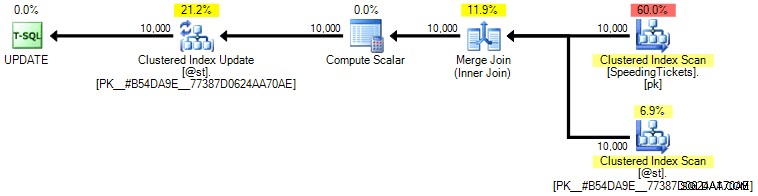
In base al numero di esecuzioni che vediamo nella scheda Operazioni principali (ti risparmio lo screenshot; è 1 per ogni operazione), è chiaro che anche se eseguiamo un join per sentirci meglio con l'ordinazione, l'eccentrico update consente di calcolare i totali parziali in un unico passaggio di dati. Confrontandolo con le query precedenti, è molto più efficiente, anche se prima scarica i dati in una variabile di tabella e viene separato in più operazioni:

Questo ci porta a un "CTE ricorsivo " metodo. Questo metodo utilizza il valore della data e si basa sul presupposto che non ci siano spazi vuoti. Poiché abbiamo popolato questi dati sopra, sappiamo che si tratta di una serie completamente contigua, ma in molti scenari non è possibile farlo assunzione. Quindi, anche se l'ho incluso per completezza, questo approccio non sarà sempre valido. In ogni caso, questo utilizza un CTE ricorsivo con la prima data (nota) nella tabella come ancora e il ricorsivo porzione determinata aggiungendo un giorno (aggiungendo l'opzione MAXRECURSION poiché sappiamo esattamente quante righe abbiamo):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Questa query funziona in modo efficiente quanto il metodo di aggiornamento eccentrico. Possiamo confrontarlo con i metodi subquery e inner join:

Come il bizzarro metodo di aggiornamento, non consiglierei questo approccio CTE in produzione a meno che tu non possa assolutamente garantire che la tua colonna chiave non abbia lacune. Se potresti avere delle lacune nei tuoi dati, puoi costruire qualcosa di simile usando ROW_NUMBER(), ma non sarà più efficiente del metodo di auto-unione sopra.
E poi abbiamo il "cursore " approccio:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; ...che è molto più codice, ma contrariamente a quanto potrebbe suggerire l'opinione popolare, ritorna in 1 secondo. Possiamo capire perché da alcuni dei dettagli del piano sopra:la maggior parte degli altri approcci finisce per leggere gli stessi dati più e più volte, mentre l'approccio del cursore legge ogni riga una volta e mantiene il totale parziale in una variabile invece di calcolare la somma su e ancora. Possiamo vederlo osservando le dichiarazioni acquisite generando un piano effettivo in Plan Explorer:
Possiamo vedere che sono state raccolte oltre 20.000 istruzioni, ma se ordiniamo per righe stimate o effettive discendenti, scopriamo che ci sono solo due operazioni che gestiscono più di una riga. Che è ben diverso da alcuni dei metodi precedenti che causano letture esponenziali a causa della lettura delle stesse righe precedenti più e più volte per ogni nuova riga.
Ora, diamo un'occhiata ai nuovi miglioramenti delle finestre in SQL Server 2012. In particolare, ora possiamo calcolare SUM OVER() e specificare un set di righe relativo alla riga corrente. Quindi, ad esempio:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Queste due domande danno la stessa risposta, con totali parziali corretti. Ma funzionano esattamente allo stesso modo? I piani suggeriscono che non lo fanno. La versione con ROWS ha un operatore aggiuntivo, un progetto di sequenza di 10.000 righe:
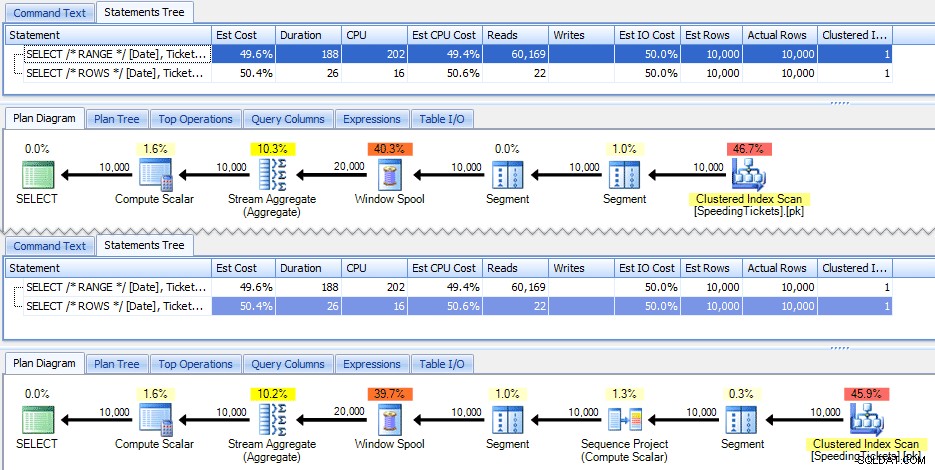
E questo riguarda l'entità della differenza nel piano grafico. Ma se guardi un po' più da vicino le metriche di runtime effettive, noterai piccole differenze nella durata e nella CPU e un'enorme differenza nelle letture. Perchè è questo? Bene, questo perché RANGE usa una bobina su disco, mentre ROWS usa una bobina in memoria. Con piccoli set la differenza è probabilmente trascurabile, ma il costo della bobina su disco può sicuramente diventare più evidente man mano che i set diventano più grandi. Non voglio rovinare il finale, ma potresti sospettare che una di queste soluzioni funzionerà meglio dell'altra in un test più approfondito.
Per inciso, la seguente versione della query produce gli stessi risultati, ma funziona come la versione più lenta RANGE sopra:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Quindi, mentre stai giocando con le nuove funzioni di windowing, tieni a mente piccole curiosità come questa:la versione abbreviata di una query, o quella che hai scritto per prima, non è necessariamente quella che desideri per passare alla produzione.
I test effettivi
Per condurre test corretti, ho creato una procedura memorizzata per ogni approccio e misurato i risultati acquisendo istruzioni su un server su cui stavo già monitorando con SQL Sentry (se non stai utilizzando il nostro strumento, puoi raccogliere eventi SQL:BatchCompleted in modo simile utilizzando SQL Server Profiler).
Con "test equi" intendo che, ad esempio, il metodo di aggiornamento eccentrico richiede un aggiornamento effettivo ai dati statici, il che significa modificare lo schema sottostante o utilizzare una tabella temporanea/variabile di tabella. Quindi ho strutturato le procedure memorizzate in modo da creare ciascuna la propria variabile di tabella e archiviare i risultati lì o archiviare i dati grezzi lì e quindi aggiornare il risultato. L'altro problema che volevo eliminare era la restituzione dei dati al client, quindi le procedure hanno ciascuna un parametro di debug che specifica se restituire nessun risultato (impostazione predefinita), top/bottom 5 o tutto. Nei test delle prestazioni l'ho impostato per non restituire risultati, ma ovviamente li ho convalidati per assicurarmi che stessero restituendo i risultati corretti.
Le procedure memorizzate sono tutte modellate in questo modo (ho allegato uno script che crea il database e le procedure memorizzate, quindi sto solo includendo un modello qui per brevità):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO E li ho chiamati in batch come segue:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Mi sono subito reso conto che alcune di queste chiamate non venivano visualizzate in Top SQL perché la soglia predefinita è 5 secondi. L'ho cambiato in 100 millisecondi (cosa che non vorresti mai fare su un sistema di produzione!) come segue:
Ripeto:questo comportamento non è condonato per i sistemi di produzione!
Ho comunque riscontrato che uno dei comandi precedenti non veniva catturato dalla soglia SQL superiore; era la versione Windowed_Rows. Quindi ho aggiunto quanto segue solo a quel batch:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
E ora stavo ottenendo tutte e 7 le righe restituite in Top SQL. Qui sono ordinati in base all'utilizzo della CPU decrescente:
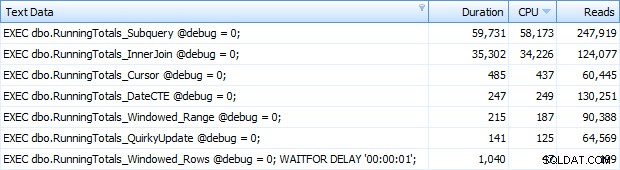
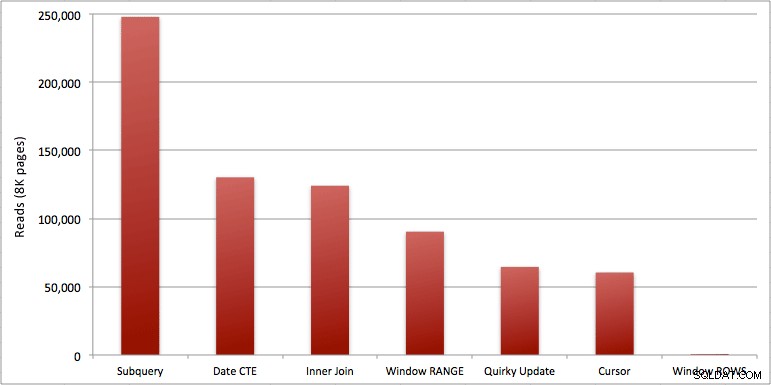
Puoi vedere il secondo in più che ho aggiunto al batch Windowed_Rows; non veniva catturato dalla soglia SQL superiore perché è stato completato in soli 40 millisecondi! Questo è chiaramente il nostro miglior rendimento e, se abbiamo SQL Server 2012 disponibile, dovrebbe essere il metodo che utilizziamo. Anche il cursore non è male per metà, date le prestazioni o altri problemi con le restanti soluzioni. Tracciare la durata su un grafico è piuttosto privo di significato:due punti alti e cinque punti bassi indistinguibili. Ma se l'I/O è il tuo collo di bottiglia, potresti trovare interessante la visualizzazione delle letture:
Conclusione
Da questi risultati possiamo trarre alcune conclusioni:
- Gli aggregati finestrati in SQL Server 2012 rendono i problemi di prestazioni con i calcoli dei totali di esecuzione (e molti altri problemi di righe successive/righe precedenti) in modo allarmante più efficienti. Quando ho visto il basso numero di letture, ho pensato che ci fosse stato un errore, che dovevo aver dimenticato di eseguire effettivamente qualsiasi lavoro. Ma no, ottieni lo stesso numero di letture se la tua procedura memorizzata esegue semplicemente un normale SELECT dalla tabella SpeedingTickets. (Sentiti libero di testarlo tu stesso con STATISTICS IO.)
- I problemi che ho sottolineato in precedenza su RANGE e ROWS producono tempi di esecuzione leggermente diversi (differenza di durata di circa 6x – ricorda di ignorare il secondo che ho aggiunto con WAITFOR), ma le differenze di lettura sono astronomiche a causa della bobina su disco. Se il tuo aggregato finestrato può essere risolto usando ROWS, evita RANGE, ma dovresti verificare che entrambi diano lo stesso risultato (o almeno che ROWS dia la risposta giusta). Tieni inoltre presente che se stai utilizzando una query simile e non specifichi RANGE né ROWS, il piano funzionerà come se avessi specificato RANGE).
- I metodi subquery e inner join sono relativamente pessimi. Da 35 secondi a un minuto per generare questi totali parziali? E questo era su un unico tavolo magro senza restituire risultati al cliente. Questi confronti possono essere utilizzati per mostrare alle persone perché una soluzione puramente basata su insiemi non è sempre la risposta migliore.
- Degli approcci più veloci, supponendo che tu non sia ancora pronto per SQL Server 2012 e supponendo che scarti sia il metodo di aggiornamento eccentrico (non supportato) che il metodo della data CTE (non può garantire una sequenza contigua), solo il cursore esegue accettabilmente. Ha la durata più alta delle soluzioni "più veloci", ma il minor numero di letture.
Spero che questi test aiutino ad apprezzare meglio i miglioramenti delle finestre che Microsoft ha aggiunto a SQL Server 2012. Assicurati di ringraziare Itzik se lo vedi online o di persona, poiché è stato la forza trainante di questi cambiamenti. Inoltre, spero che questo aiuti ad aprire alcune menti là fuori sul fatto che un cursore potrebbe non essere sempre la soluzione malvagia e temuta che viene spesso raffigurata.
(Come aggiunta, ho testato la funzione CLR offerta da Pavel Pawlowski e le caratteristiche delle prestazioni erano quasi identiche alla soluzione SQL Server 2012 utilizzando ROWS. Le letture erano identiche, la CPU era 78 contro 47 e la durata complessiva era 73 invece di 40. Quindi, se non passerai a SQL Server 2012 nel prossimo futuro, potresti voler aggiungere la soluzione di Pavel ai tuoi test.)
Allegati:RunningTotals_Demo.sql.zip (2kb)