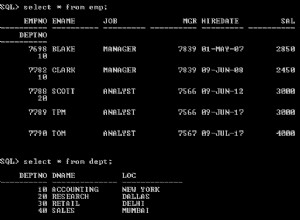
Creiamo dati di test su Postgresl 13 con 600 set di dati, 45k cfile.
BEGIN;
CREATE TABLE cfiles (
id SERIAL PRIMARY KEY,
dataset_id INTEGER NOT NULL,
property_values jsonb NOT NULL);
INSERT INTO cfiles (dataset_id,property_values)
SELECT 1+(random()*600)::INTEGER AS did,
('{"Sample Names": ["'||array_to_string(array_agg(DISTINCT prop),'","')||'"]}')::jsonb prop
FROM (
SELECT 1+(random()*45000)::INTEGER AS cid,
'Samp'||(power(random(),2)*30)::INTEGER AS prop
FROM generate_series(1,45000*4)) foo
GROUP BY cid;
COMMIT;
CREATE TABLE datasets ( id INTEGER PRIMARY KEY, name TEXT NOT NULL );
INSERT INTO datasets SELECT n, 'dataset'||n FROM (SELECT DISTINCT dataset_id n FROM cfiles) foo;
CREATE INDEX cfiles_dataset ON cfiles(dataset_id);
VACUUM ANALYZE cfiles;
VACUUM ANALYZE datasets;
La tua query originale è molto più veloce qui, ma probabilmente è perché Postgres 13 è solo più intelligente.
Sort (cost=114127.87..114129.37 rows=601 width=46) (actual time=658.943..659.012 rows=601 loops=1)
Sort Key: datasets.name
Sort Method: quicksort Memory: 334kB
-> GroupAggregate (cost=0.57..114100.13 rows=601 width=46) (actual time=13.954..655.916 rows=601 loops=1)
Group Key: datasets.id
-> Nested Loop (cost=0.57..92009.62 rows=4416600 width=46) (actual time=13.373..360.991 rows=163540 loops=1)
-> Merge Join (cost=0.56..3677.61 rows=44166 width=78) (actual time=13.350..113.567 rows=44166 loops=1)
Merge Cond: (cfiles.dataset_id = datasets.id)
-> Index Scan using cfiles_dataset on cfiles (cost=0.29..3078.75 rows=44166 width=68) (actual time=0.015..69.098 rows=44166 loops=1)
-> Index Scan using datasets_pkey on datasets (cost=0.28..45.29 rows=601 width=14) (actual time=0.024..0.580 rows=601 loops=1)
-> Function Scan on jsonb_array_elements_text sn (cost=0.01..1.00 rows=100 width=32) (actual time=0.003..0.004 rows=4 loops=44166)
Execution Time: 661.978 ms
Questa query legge prima una tabella grande (cfiles) e produce molte meno righe a causa dell'aggregazione. Quindi sarà più veloce unire i set di dati dopo che il numero di righe da unire è stato ridotto, non prima. Spostiamo quell'unione. Inoltre mi sono sbarazzato del CROSS JOIN che non è necessario, quando c'è una funzione di ritorno di set in un SELECT postgres farà quello che vuoi gratuitamente.
SELECT dataset_id, d.name, sample_names FROM (
SELECT dataset_id, string_agg(sn, '; ') as sample_names FROM (
SELECT DISTINCT dataset_id,
jsonb_array_elements_text(cfiles.property_values -> 'Sample Names') AS sn
FROM cfiles
) f GROUP BY dataset_id
)g JOIN datasets d ON (d.id=g.dataset_id)
ORDER BY d.name;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=536207.44..536207.94 rows=200 width=46) (actual time=264.435..264.502 rows=601 loops=1)
Sort Key: d.name
Sort Method: quicksort Memory: 334kB
-> Hash Join (cost=536188.20..536199.79 rows=200 width=46) (actual time=261.404..261.784 rows=601 loops=1)
Hash Cond: (d.id = cfiles.dataset_id)
-> Seq Scan on datasets d (cost=0.00..10.01 rows=601 width=14) (actual time=0.025..0.124 rows=601 loops=1)
-> Hash (cost=536185.70..536185.70 rows=200 width=36) (actual time=261.361..261.363 rows=601 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 170kB
-> HashAggregate (cost=536181.20..536183.70 rows=200 width=36) (actual time=260.805..261.054 rows=601 loops=1)
Group Key: cfiles.dataset_id
Batches: 1 Memory Usage: 1081kB
-> HashAggregate (cost=409982.82..507586.70 rows=1906300 width=36) (actual time=244.419..253.094 rows=18547 loops=1)
Group Key: cfiles.dataset_id, jsonb_array_elements_text((cfiles.property_values -> 'Sample Names'::text))
Planned Partitions: 4 Batches: 1 Memory Usage: 13329kB
-> ProjectSet (cost=0.00..23530.32 rows=4416600 width=36) (actual time=0.030..159.741 rows=163540 loops=1)
-> Seq Scan on cfiles (cost=0.00..1005.66 rows=44166 width=68) (actual time=0.006..9.588 rows=44166 loops=1)
Planning Time: 0.247 ms
Execution Time: 269.362 ms
Va meglio. Ma vedo un LIMITE nella tua query, il che significa che probabilmente stai facendo qualcosa come l'impaginazione. In questo caso è solo necessario calcolare l'intera query per l'intera tabella cfiles e quindi buttare via la maggior parte dei risultati a causa del LIMITE, SE i risultati di quella grande query possono cambiare se una riga di set di dati è inclusa nel risultato finale o no. In tal caso, le righe nei set di dati che non hanno cfile corrispondenti non verranno visualizzate nel risultato finale, il che significa che il contenuto di cfile influirà sull'impaginazione. Bene, possiamo sempre imbrogliare:per sapere se una riga di set di dati deve essere inclusa, tutto ciò che serve è che esista UNA riga da cfiles con quell'id...
Quindi, per sapere quali righe di set di dati verranno incluse nel risultato finale, possiamo utilizzare una di queste due query:
SELECT id FROM datasets WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = datasets.id )
ORDER BY name LIMIT 20;
SELECT dataset_id FROM
(SELECT id AS dataset_id, name AS dataset_name FROM datasets ORDER BY dataset_name) f1
WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = f1.dataset_id )
ORDER BY dataset_name
LIMIT 20;
Quelli impiegano circa 2-3 millisecondi. Possiamo anche imbrogliare:
CREATE INDEX datasets_name_id ON datasets(name,id);
Questo lo porta a circa 300 microsecondi. Quindi, ora abbiamo l'elenco di dataset_id che verrà effettivamente utilizzato (e non gettato via) in modo che possiamo usarlo per eseguire la grande aggregazione lenta solo sulle righe che saranno effettivamente nel risultato finale, il che dovrebbe risparmiare una grande quantità di lavoro non necessario...
WITH ds AS (SELECT id AS dataset_id, name AS dataset_name
FROM datasets WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = datasets.id )
ORDER BY name LIMIT 20)
SELECT dataset_id, dataset_name, sample_names FROM (
SELECT dataset_id, string_agg(DISTINCT sn, '; ' ORDER BY sn) as sample_names FROM (
SELECT dataset_id,
jsonb_array_elements_text(cfiles.property_values -> 'Sample Names') AS sn
FROM ds JOIN cfiles USING (dataset_id)
) g GROUP BY dataset_id
) h JOIN ds USING (dataset_id)
ORDER BY dataset_name;
Ci vogliono circa 30 ms, inoltre ho inserito l'ordine per sample_name che avevo dimenticato prima. Dovrebbe funzionare per il tuo caso. Un punto importante è che il tempo di query non dipende più dalla dimensione dei file c della tabella, poiché elaborerà solo le righe effettivamente necessarie.
Si prega di pubblicare i risultati;)