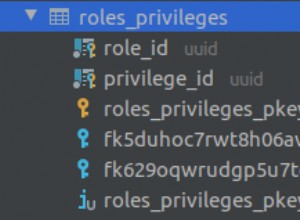
Piuttosto che usare un flag in report_subscriber stesso, penso che faresti meglio con una coda separata di modifiche in sospeso. Questo ha alcuni vantaggi:
- Nessuna ricorsione del trigger
- Sotto il cofano,
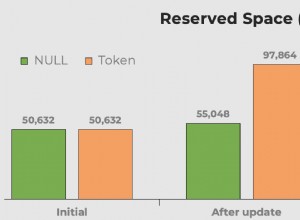
UPDATEè soloDELETE+ re-INSERIRE , quindi l'inserimento in una coda sarà effettivamente più economico che lanciare una bandiera - Forse un po' più economico, dal momento che devi solo mettere in coda il distinto
report_ids, invece di clonare l'interoreport_subscriberrecord e puoi farlo in una tabella temporanea, quindi lo spazio di archiviazione è contiguo e non è necessario sincronizzare nulla sul disco - Nessuna condizione di gara di cui preoccuparsi quando si capovolgono i flag, poiché la coda è locale rispetto alla transazione corrente (nella tua implementazione, i record interessati da
UPDATE report_subscribernon sono necessariamente gli stessi record che hai raccolto inSELECT...)
Quindi, inizializza la tabella della coda:
CREATE FUNCTION create_queue_table() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
CREATE TEMP TABLE pending_subscriber_changes(report_id INT UNIQUE) ON COMMIT DROP;
RETURN NULL;
END
$$;
CREATE TRIGGER create_queue_table_if_not_exists
BEFORE INSERT OR UPDATE OF report_id, subscriber_name OR DELETE
ON report_subscriber
FOR EACH STATEMENT
WHEN (to_regclass('pending_subscriber_changes') IS NULL)
EXECUTE PROCEDURE create_queue_table();
...accoda le modifiche all'arrivo, ignorando tutto ciò che è già in coda:
CREATE FUNCTION queue_subscriber_change() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
IF TG_OP IN ('DELETE', 'UPDATE') THEN
INSERT INTO pending_subscriber_changes (report_id) VALUES (old.report_id)
ON CONFLICT DO NOTHING;
END IF;
IF TG_OP IN ('INSERT', 'UPDATE') THEN
INSERT INTO pending_subscriber_changes (report_id) VALUES (new.report_id)
ON CONFLICT DO NOTHING;
END IF;
RETURN NULL;
END
$$;
CREATE TRIGGER queue_subscriber_change
AFTER INSERT OR UPDATE OF report_id, subscriber_name OR DELETE
ON report_subscriber
FOR EACH ROW
EXECUTE PROCEDURE queue_subscriber_change();
...ed elabora la coda alla fine dell'istruzione:
CREATE FUNCTION process_pending_changes() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
UPDATE report
SET report_subscribers = ARRAY(
SELECT DISTINCT subscriber_name
FROM report_subscriber s
WHERE s.report_id = report.report_id
ORDER BY subscriber_name
)
FROM pending_subscriber_changes c
WHERE report.report_id = c.report_id;
DROP TABLE pending_subscriber_changes;
RETURN NULL;
END
$$;
CREATE TRIGGER process_pending_changes
AFTER INSERT OR UPDATE OF report_id, subscriber_name OR DELETE
ON report_subscriber
FOR EACH STATEMENT
EXECUTE PROCEDURE process_pending_changes();
C'è un piccolo problema con questo:UPDATE non offre alcuna garanzia sull'ordine di aggiornamento. Ciò significa che, se queste due istruzioni sono state eseguite contemporaneamente:
INSERT INTO report_subscriber (report_id, subscriber_name) VALUES (1, 'a'), (2, 'b');
INSERT INTO report_subscriber (report_id, subscriber_name) VALUES (2, 'x'), (1, 'y');
...allora c'è la possibilità di un deadlock, se tentano di aggiornare il report registra in ordine opposto. Puoi evitarlo imponendo un ordine coerente per tutti gli aggiornamenti, ma sfortunatamente non c'è modo di allegare un ORDINA PER a un UPDATE dichiarazione; Penso che tu debba ricorrere ai cursori:
CREATE FUNCTION process_pending_changes() RETURNS TRIGGER LANGUAGE plpgsql AS $$
DECLARE
target_report CURSOR FOR
SELECT report_id
FROM report
WHERE report_id IN (TABLE pending_subscriber_changes)
ORDER BY report_id
FOR NO KEY UPDATE;
BEGIN
FOR target_record IN target_report LOOP
UPDATE report
SET report_subscribers = ARRAY(
SELECT DISTINCT subscriber_name
FROM report_subscriber
WHERE report_id = target_record.report_id
ORDER BY subscriber_name
)
WHERE CURRENT OF target_report;
END LOOP;
DROP TABLE pending_subscriber_changes;
RETURN NULL;
END
$$;
Ciò ha ancora il potenziale di deadlock se il client tenta di eseguire più istruzioni all'interno della stessa transazione (poiché l'ordine di aggiornamento viene applicato solo all'interno di ciascuna istruzione, ma i blocchi di aggiornamento vengono mantenuti fino al commit). Puoi aggirare questo (più o meno) disattivando process_pending_changes() solo una volta al termine della transazione (lo svantaggio è che, all'interno di quella transazione, non vedrai le tue modifiche riflesse nei report_subscribers matrice).
Ecco uno schema generico per un trigger "on commit", se ritieni che valga la pena compilarlo:
CREATE FUNCTION run_on_commit() RETURNS TRIGGER LANGUAGE plpgsql AS $$
BEGIN
<your code goes here>
RETURN NULL;
END
$$;
CREATE FUNCTION trigger_already_fired() RETURNS BOOLEAN LANGUAGE plpgsql VOLATILE AS $$
DECLARE
already_fired BOOLEAN;
BEGIN
already_fired := NULLIF(current_setting('my_vars.trigger_already_fired', TRUE), '');
IF already_fired IS TRUE THEN
RETURN TRUE;
ELSE
SET LOCAL my_vars.trigger_already_fired = TRUE;
RETURN FALSE;
END IF;
END
$$;
CREATE CONSTRAINT TRIGGER my_trigger
AFTER INSERT OR UPDATE OR DELETE ON my_table
DEFERRABLE INITIALLY DEFERRED
FOR EACH ROW
WHEN (NOT trigger_already_fired())
EXECUTE PROCEDURE run_on_commit();