Molto tempo fa, ho risposto a una domanda su NULL su Stack Exchange intitolata "Perché non dovremmo consentire NULL?" Ho la mia parte di irritazioni e passioni da compagnia e la paura dei NULL è piuttosto in cima alla mia lista. Un collega mi ha detto di recente, dopo aver espresso la preferenza per forzare una stringa vuota invece di consentire NULL:
"Non mi piace avere a che fare con i valori null nel codice."
Mi dispiace, ma non è una buona ragione. Il modo in cui il livello di presentazione gestisce stringhe vuote o NULL non dovrebbe essere il driver per la progettazione della tabella e il modello di dati. E se stai consentendo una "mancanza di valore" in alcune colonne, ti importa da un punto di vista logico se la "mancanza di valore" è rappresentata da una stringa di lunghezza zero o da un NULL? O peggio, un valore token come 0 o -1 per numeri interi o 1900-01-01 per date?
Itzik Ben-Gan ha recentemente scritto un'intera serie sui NULL e consiglio vivamente di esaminarla tutta:
- Complessità NULL – Parte 1
- Complessità NULL – Parte 2
- Complessità NULL – Parte 3, Funzionalità standard mancanti e alternative T-SQL
- Complessità NULL – Parte 4, Vincolo unico standard mancante
Ma il mio obiettivo qui è un po' meno complicato di così, dopo che l'argomento è emerso in una domanda diversa di Stack Exchange:"Aggiungi un campo automatico ora a una tabella esistente". Lì, l'utente stava aggiungendo una nuova colonna a una tabella esistente, con l'intenzione di popolarla automaticamente con la data/ora corrente. Si chiedevano se avrebbero dovuto lasciare NULL in quella colonna per tutte le righe esistenti o impostare un valore predefinito (come 1900-01-01, presumibilmente, anche se non erano espliciti).
Potrebbe essere facile per qualcuno esperto filtrare le vecchie righe in base a un valore simbolico, dopotutto, come si può credere che una sorta di doodad Bluetooth sia stato prodotto o acquistato il 1900-01-01? Bene, l'ho visto nei sistemi attuali in cui usano alcune date dal suono arbitrario nelle viste per fungere da filtro magico, presentando solo righe in cui il valore può essere considerato attendibile. Infatti, in tutti i casi che ho visto finora, la data nella clausola WHERE è la data/ora in cui è stata aggiunta la colonna (o il suo vincolo predefinito). Che va tutto bene; forse non è il modo migliore per risolvere il problema, ma è un modo.
Se non accedi alla tabella attraverso la vista, tuttavia, questa implica un conosciuto value può comunque causare problemi sia logici che relativi ai risultati. Il problema logico è semplicemente che qualcuno che interagisce con la tabella deve sapere che 1900-01-01 è un valore simbolico fasullo che rappresenta "sconosciuto" o "non pertinente". Per un esempio reale, qual era la velocità media di rilascio, in secondi, per un quarterback che ha giocato negli anni '70, prima che misurassimo o monitorassimo una cosa del genere? 0 è un buon valore di token per "sconosciuto"? Che ne dici di -1? O 100? Tornando alle date, se un paziente senza ID viene ricoverato in ospedale ed è privo di sensi, quale dovrebbe inserire come data di nascita? Non credo che 1900-01-01 sia una buona idea, e di certo non era una buona idea quando era più probabile che fosse una vera data di nascita.
Implicazioni sulle prestazioni dei valori dei token
Dal punto di vista delle prestazioni, valori falsi o "token" come 1900-01-01 o 9999-21-31 possono introdurre problemi. Diamo un'occhiata a un paio di questi con un esempio basato vagamente sulla recente domanda sopra menzionata. Abbiamo una tabella Widget e, dopo alcuni resi in garanzia, abbiamo deciso di aggiungere una colonna EnteredService in cui inseriremo la data/ora corrente per le nuove righe. In un caso lasceremo tutte le righe esistenti come NULL e nell'altro aggiorneremo il valore alla nostra magica data 1900-01-01. (Per ora lasceremo qualsiasi tipo di compressione fuori dalla conversazione.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Ora inseriremo le stesse 100.000 righe in ogni tabella:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Quindi possiamo aggiungere la nuova colonna e aggiornare il 10% dei valori esistenti con una distribuzione di date correnti e l'altro 90% alla nostra data di token solo in una delle tabelle:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Infine, possiamo aggiungere indici:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Spazio utilizzato
Sento sempre "lo spazio su disco è a buon mercato" quando parliamo di scelte di tipo di dati, frammentazione e valori dei token rispetto a NULL. La mia preoccupazione non è tanto per lo spazio su disco che questi valori extra insignificanti occupano. È più che, quando si interroga la tabella, si sta sprecando memoria. Qui possiamo avere una rapida idea di quanto spazio occupano i nostri valori di token prima e dopo l'aggiunta della colonna e dell'indice:
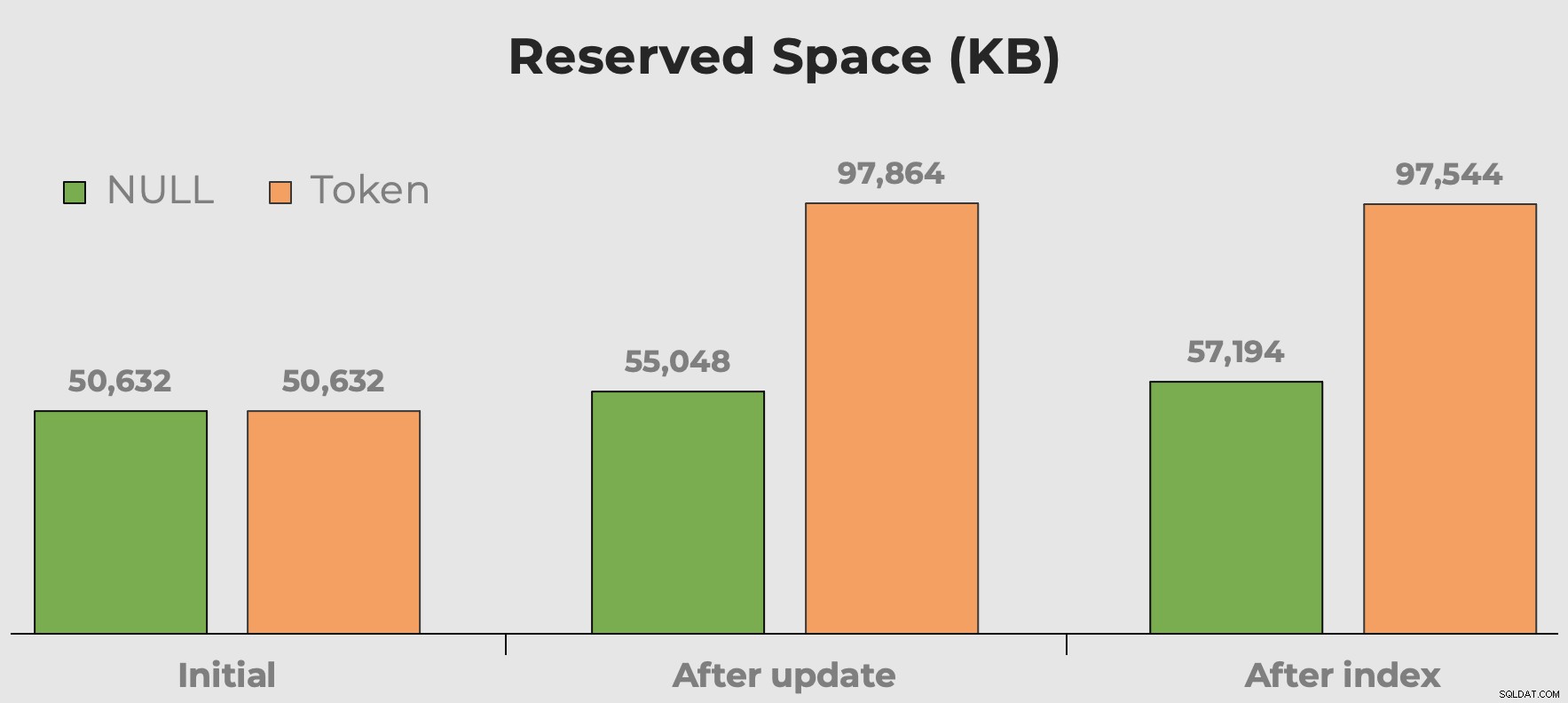 Spazio riservato della tabella dopo aver aggiunto una colonna e aggiunto un indice. Lo spazio quasi raddoppia con i valori dei token.
Spazio riservato della tabella dopo aver aggiunto una colonna e aggiunto un indice. Lo spazio quasi raddoppia con i valori dei token.
Esecuzione della query
Inevitabilmente, qualcuno farà ipotesi sui dati nella tabella e interrogherà la colonna EnteredService come se tutti i valori fossero legittimi. Ad esempio:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; I valori dei token possono pasticciare con le stime in alcuni casi ma, soprattutto, produrranno risultati errati (o almeno inaspettati). Ecco il piano di esecuzione per la query sulla tabella con valori di token:
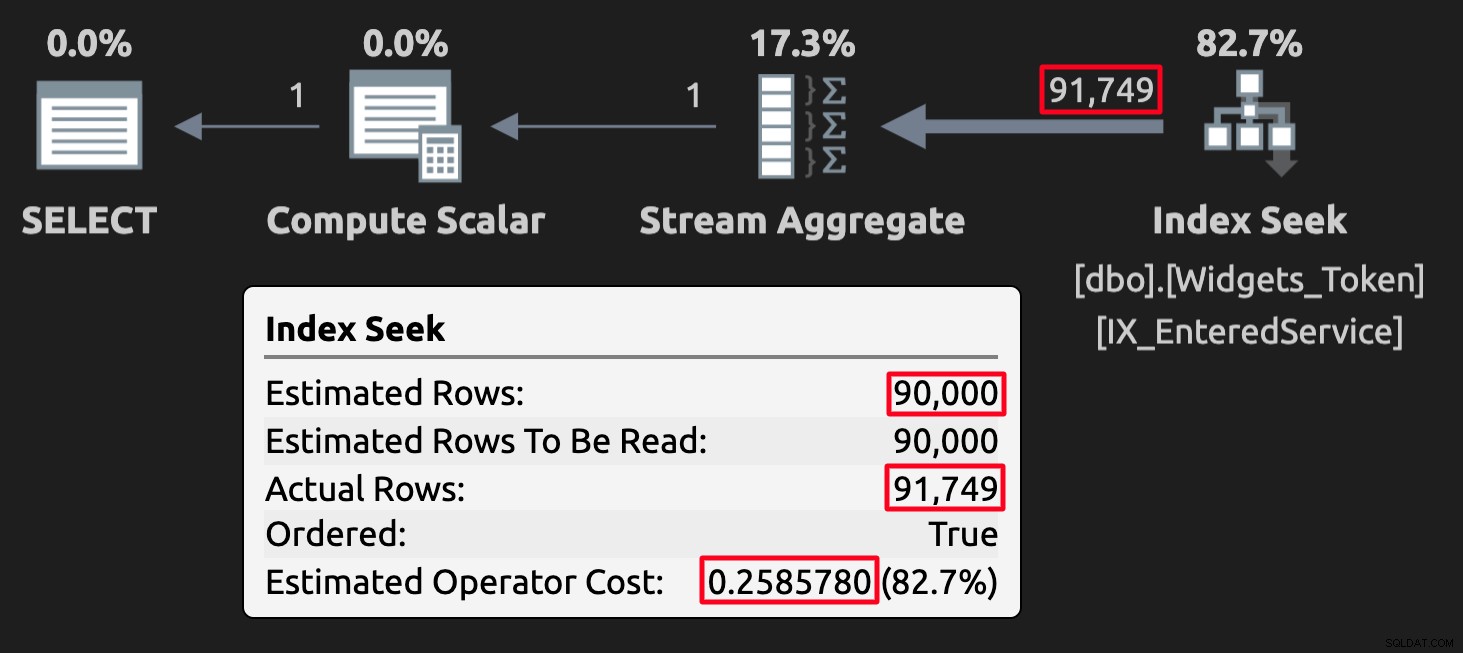 Piano di esecuzione per la tabella dei token; nota il costo elevato.
Piano di esecuzione per la tabella dei token; nota il costo elevato.
Ed ecco il piano di esecuzione per la query sulla tabella con NULL:
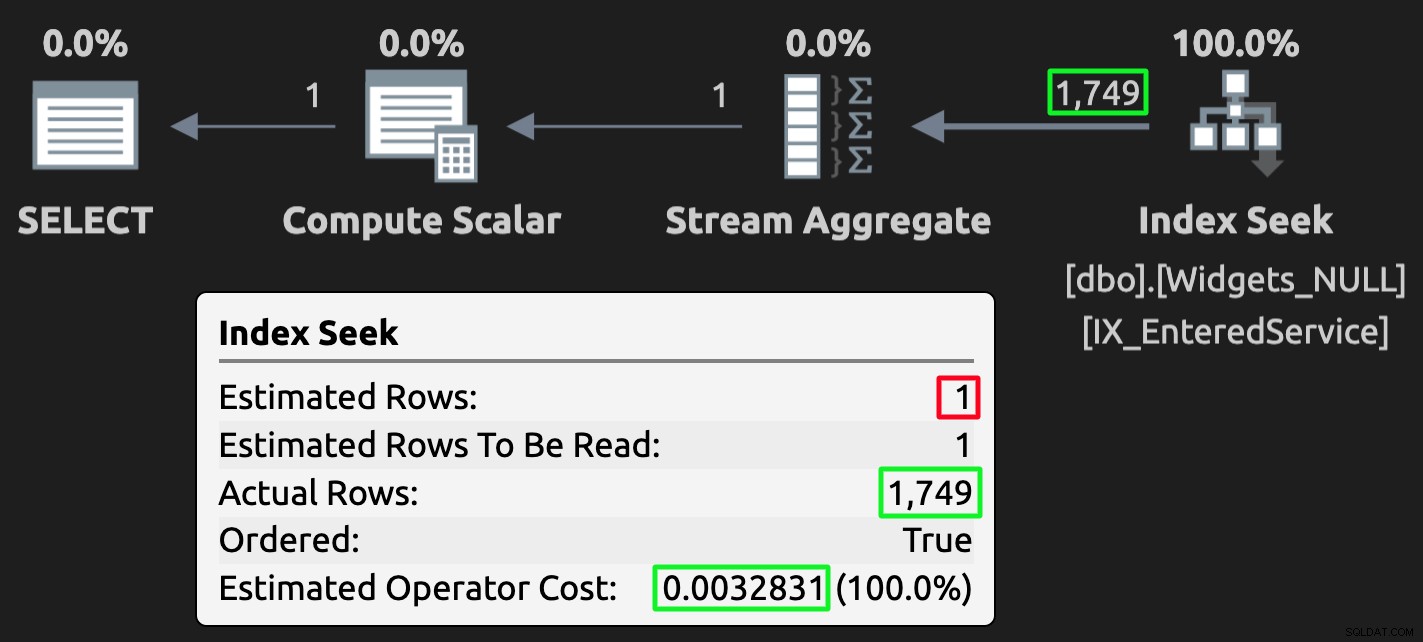 Piano di esecuzione per la tabella NULL; stima errata, ma costo molto inferiore.
Piano di esecuzione per la tabella NULL; stima errata, ma costo molto inferiore.
Lo stesso accadrebbe nell'altro modo se la query richiesta>={qualche data} e 9999-12-31 fosse usata come valore magico che rappresenta sconosciuto.
Ancora una volta, per le persone a cui capita di sapere che i risultati sono sbagliati proprio perché hai usato valori token, questo non è un problema. Ma tutti gli altri che non lo sanno, inclusi futuri colleghi, altri eredi e manutentori del codice e persino te con problemi di memoria, probabilmente inciamperanno.
Conclusione
La scelta di consentire NULL in una colonna (o di evitare completamente NULL) non dovrebbe essere ridotta a una decisione ideologica o basata sulla paura. Esistono svantaggi reali e tangibili nell'architettura del modello di dati per assicurarsi che nessun valore possa essere NULL o nell'utilizzo di valori privi di significato per rappresentare qualcosa che potrebbe facilmente non essere stato archiviato affatto. Non sto suggerendo che ogni colonna nel tuo modello dovrebbe consentire NULL; solo per non essere contrari all'idea di NULL.