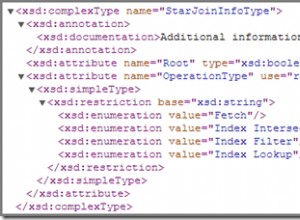
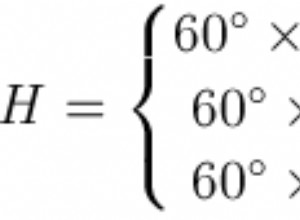Alcuni problemi emergono:
Innanzitutto, considera l'upgrade a una versione corrente di Postgres . Al momento della scrittura è pg 9.6 o pg 10 (attualmente beta). Da Pg 9.4 ci sono stati molteplici miglioramenti per gli indici GIN, il modulo aggiuntivo pg_trgm e i big data in generale.
Successivamente, hai bisogno di molta più RAM , in particolare un work_mem più alto ambientazione. Posso dire da questa riga in EXPLAIN uscita:
Heap Blocks: exact=7625 lossy=223807
"perdita" nei dettagli per una Scansione Heap Bitmap (con i tuoi numeri particolari) indica una drammatica carenza di work_mem . Postgres raccoglie solo gli indirizzi dei blocchi nella scansione dell'indice bitmap invece dei puntatori di riga perché dovrebbe essere più veloce con il tuo work_mem basso impostazione (non può contenere indirizzi esatti nella RAM). Molte altre righe non qualificanti devono essere filtrate nella seguente Scansione heap bitmap Da questa parte. Questa risposta correlata ha dettagli:
Ma non impostare work_mem anche alto senza considerare l'intera situazione:
Potrebbero esserci altri problemi, come l'aumento dell'indice o della tabella o più colli di bottiglia nella configurazione. Ma se correggi solo questi due elementi, la query dovrebbe essere molto già più veloce.
Inoltre, hai davvero bisogno di recuperare tutte le 40.000 righe nell'esempio? Probabilmente vuoi aggiungere un piccolo LIMIT alla query e trasformarla in una ricerca "vicino più vicino", nel qual caso un indice GiST è la scelta migliore dopo tutto, perché quello dovrebbe essere più veloce con un indice GiST. Esempio: