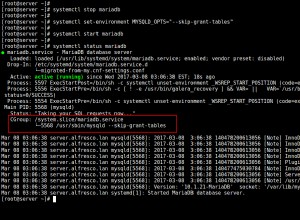
La mia soluzione alternativa è tagliare putback con una semplice funzione come proposto qui
:
def chunk(l, n):
n = max(1, n)
return [l[i:i + n] for i in range(0, len(l), n)]
e poi
for chunk in chunk(putback, 250000):
curs.execute("UPDATE table1
SET col3 = p.result
FROM unnest(%s) p(sid INT, result JSONB)
WHERE sid = p.sid", (chunk,))
Funziona, vale a dire tiene sotto controllo l'impronta di memoria, ma non è molto elegante e più lento del dumping di tutti i dati in una volta, come faccio di solito.