Sebbene in futuro la maggior parte dei server di database (in particolare quelli che gestiscono carichi di lavoro simili a OLTP) utilizzerà uno storage basato su flash, non ci siamo ancora:lo storage flash è ancora notevolmente più costoso dei tradizionali dischi rigidi e così tanti sistemi utilizzano un mix di unità SSD e HDD. Ciò tuttavia significa che dobbiamo decidere come dividere il database:cosa dovrebbe andare allo spinning rust (HDD) e qual è un buon candidato per l'archiviazione flash che è più costosa ma molto migliore nella gestione di I/O casuali.
Ci sono soluzioni che cercano di gestirlo automaticamente a livello di archiviazione utilizzando automaticamente gli SSD come cache, mantenendo automaticamente la parte attiva dei dati su SSD. I dispositivi di archiviazione/SAN spesso lo fanno internamente, ci sono unità SATA/SAS ibride con HDD di grandi dimensioni e SSD di piccole dimensioni in un unico pacchetto e, naturalmente, ci sono soluzioni per farlo direttamente sull'host, ad esempio c'è dm-cache in Linux, LVM ha anche ottenuto tale capacità (costruita su dm-cache) nel 2014 e, naturalmente, ZFS ha L2ARC.
Ma ignoriamo tutte queste opzioni automatiche e diciamo che abbiamo due dispositivi collegati direttamente al sistema:uno basato su HDD, l'altro basato su flash. Come dividere il database per ottenere il massimo vantaggio dal costoso flash? Un modello comunemente usato consiste nel farlo in base al tipo di oggetto, in particolare tabelle e indici. Il che ha senso in generale, ma vediamo spesso persone che posizionano indici sull'archiviazione SSD, poiché gli indici sono associati a I/O casuali. Anche se può sembrare ragionevole, si scopre che è esattamente l'opposto di ciò che dovresti fare.
Lascia che ti mostri un benchmark...
Lasciate che lo dimostri su un sistema con storage HDD (RAID10 costruito da 4 unità SAS da 10k) e un singolo dispositivo SSD (Intel S3700). Il sistema ha 16 GB di RAM, quindi utilizziamo pgbench con scale 300 (=4,5 GB) e 3000 (=45 GB), ovvero uno che si adatta facilmente alla RAM e un multiplo di RAM. Quindi posizioniamo tabelle e indici su diversi sistemi di archiviazione (utilizzando i tablespace) e misuriamo le prestazioni. Il cluster di database è stato configurato in modo ragionevole (buffer condivisi, limiti WAL ecc.) rispetto alle risorse hardware. Il WAL è stato posizionato su un dispositivo SSD separato, collegato a un controller RAID condiviso con le unità SAS.
Sul piccolo set di dati (4,5 GB), i risultati sono simili a questo (notare che l'asse y inizia a 3000 tps):
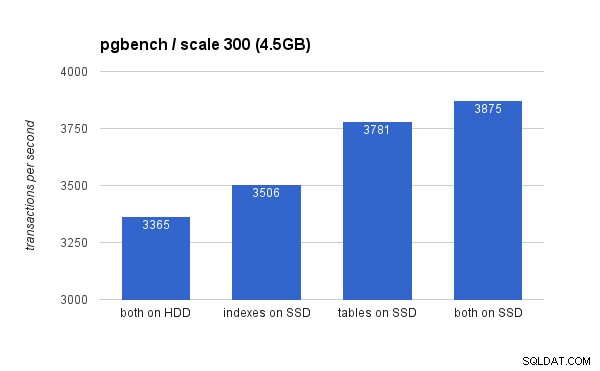
Chiaramente, posizionare gli indici su SSD offre un vantaggio inferiore rispetto all'utilizzo dell'SSD per le tabelle. Sebbene il set di dati si adatti facilmente alla RAM, le modifiche devono eventualmente essere scritte su disco e, sebbene il controller RAID abbia una cache di scrittura, non può davvero competere con la memoria flash. I nuovi controller RAID probabilmente funzionerebbero un po' meglio, ma anche le nuove unità SSD.
Sul set di dati di grandi dimensioni, le differenze sono molto più significative (questa volta l'asse y inizia da 0):
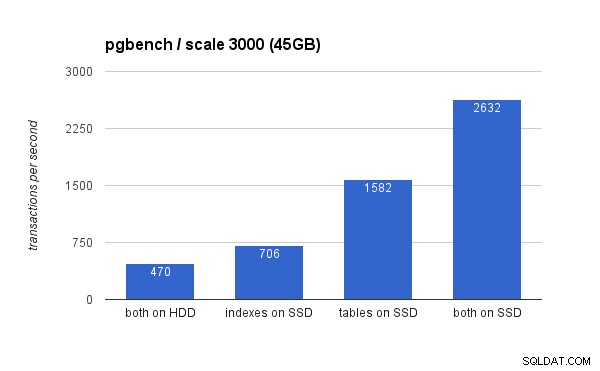
Posizionando gli indici su SSD si ottiene un aumento significativo delle prestazioni (quasi il 50%, prendendo come base l'archiviazione HDD), ma lo spostamento delle tabelle sull'SSD lo supera facilmente guadagnando oltre il 200%. Ovviamente, se posizioni sia le tabelle che l'indice su SSD, migliorerai ulteriormente le prestazioni, ma se puoi farlo, non devi preoccuparti degli altri casi.
Ma perché?
Ottenere prestazioni migliori posizionando tabelle su SSD può sembrare un po' controintuitivo, quindi perché si comporta in questo modo? Bene, è probabilmente una combinazione di diversi fattori:
- Gli indici sono generalmente molto più piccoli delle tabelle e quindi si adattano più facilmente alla memoria
- le pagine nei livelli degli indici (nell'albero) sono generalmente piuttosto calde, e quindi rimangono in memoria
- durante la scansione e l'indicizzazione, gran parte dell'I/O effettivo è di natura sequenziale (in particolare per le pagine foglia)
La conseguenza di ciò è che una quantità sorprendente di I/O sugli indici non si verifica affatto (grazie alla memorizzazione nella cache) o è sequenziale. D'altra parte, gli indici sono un'ottima fonte di I/O casuali rispetto alle tabelle.
È più complicato, però...
Naturalmente, questo era solo un semplice esempio e le conclusioni potrebbero essere diverse per carichi di lavoro sostanzialmente diversi, ad esempio. Allo stesso modo, poiché gli SSD sono più costosi, i sistemi tendono ad avere più spazio su disco sulle unità HDD rispetto alle unità SSD, quindi le tabelle potrebbero non adattarsi all'SSD mentre gli indici lo farebbero. In questi casi è necessario un posizionamento più elaborato, ad esempio considerando non solo il tipo di oggetto, ma anche la frequenza con cui viene utilizzato (e spostando solo le tabelle molto utilizzate su SSD), o anche sottoinsiemi di tabelle (ad esempio spostando gradualmente le vecchie tabelle dati da SSD a HDD).