Una delle mie più grandi gioie come sviluppatore è imparare come si intersecano tecnologie diverse.
Negli anni ho avuto l'opportunità di lavorare con diversi tipi di software e strumenti. Tra i molti strumenti che ho usato, Python e Structured Query Language (SQL) sono due dei miei preferiti.
In questo articolo condividerò con te come interagiscono Python e i diversi database SQL.
Parlerò dei database più popolari, SQLite, MySQL e PostgreSQL. Spiegherò le differenze chiave di ciascun database e i casi d'uso corrispondenti. E concluderò l'articolo con del codice Python.
Il codice ti mostrerà come scrivere una query SQL per estrarre dati da un database PostgreSQL e archiviare i dati in un frame di dati panda.
Se non hai familiarità con i database relazionali (RDBMS), ti suggerisco di consultare l'articolo di Sameer sulla terminologia di base di RDBMS qui. Il resto dell'articolo utilizzerà i termini a cui si fa riferimento nell'articolo di Sameer.
Database SQL popolari
SQLite
SQLite è meglio conosciuto per essere un database integrato. Ciò significa che non è necessario installare un'applicazione aggiuntiva o utilizzare un server separato per eseguire il database.
Se stai creando un MVP o non hai bisogno di un sacco di spazio di archiviazione dei dati, ti consigliamo di utilizzare un database SQLite.
I vantaggi sono che puoi muoverti più velocemente con un database SQLite relativo a MySQL e PostgreSQL. Detto questo, rimarrai bloccato con funzionalità limitate. Non sarai in grado di personalizzare le funzionalità o aggiungere un sacco di funzionalità multiutente.
MySQL/PostgreSQL
Ci sono differenze nette tra MySQL e PostgreSQL. Detto questo, dato il contesto dell'articolo, rientrano in una categoria simile.
Entrambi i tipi di database sono ottimi per le soluzioni aziendali. Se hai bisogno di scalare velocemente, MySQL e PostgreSQL sono la soluzione migliore. Forniranno un'infrastruttura a lungo termine e rafforzeranno la tua sicurezza.
Un altro motivo per cui sono ideali per le aziende è che possono gestire attività ad alte prestazioni. Le istruzioni di inserimento, aggiornamento e selezione più lunghe richiedono molta potenza di calcolo. Sarai in grado di scrivere quelle istruzioni con una latenza inferiore a quella che ti darebbe un database SQLite.
Perché collegare Python e un database SQL?
Potresti chiederti "perché dovrei preoccuparmi di connettere Python e un database SQL?"
Ci sono molti casi d'uso per quando qualcuno vorrebbe connettere Python a un database SQL. Come accennato in precedenza, potresti lavorare su un'applicazione web. In questo caso, dovrai connettere un database SQL in modo da poter archiviare i dati provenienti dall'applicazione web.
Forse lavori nell'ingegneria dei dati e devi creare una pipeline ETL automatizzata. La connessione di Python a un database SQL ti consentirà di utilizzare Python per le sue capacità di automazione. Sarai anche in grado di comunicare tra diverse origini dati. Non dovrai passare da un linguaggio di programmazione diverso all'altro.
Il collegamento di Python e di un database SQL renderà anche il lavoro di data science più conveniente. Sarai in grado di utilizzare le tue abilità Python per manipolare i dati da un database SQL. Non avrai bisogno di un file CSV.
Come si collegano Python e i database SQL

I database Python e SQL si connettono tramite librerie Python personalizzate. Puoi importare queste librerie nel tuo script Python.
Le librerie Python specifiche del database servono come istruzioni supplementari. Queste istruzioni guidano il tuo computer su come può interagire con il tuo database SQL. Altrimenti, il tuo codice Python sarà una lingua straniera per il database a cui stai tentando di connetterti.
Come impostare il progetto
Prendiamo ad esempio un database PostgreSQL, AWS Redshift. Innanzitutto, vorrai importare la libreria psycopg. È una libreria Python universale per i database PostgreSQL.
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdNoterai che abbiamo anche importato le librerie JSON e Pandas. Abbiamo importato JSON perché la creazione di un file di configurazione JSON è un modo sicuro per archiviare le credenziali del database. Non vogliamo che nessun altro li guardi!
La libreria panda ti consentirà di utilizzare tutte le capacità statistiche di panda per il tuo script Python. In questo caso, la libreria consentirà a Python di archiviare i dati restituiti dalla query SQL in un frame di dati.
Successivamente, vorrai accedere al tuo file di configurazione. Il json.load() la funzione legge il file JSON in modo da poter accedere alle credenziali del database nel passaggio successivo.
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
Ora che il tuo script Python può accedere al tuo file di configurazione JSON, ti consigliamo di creare una connessione al database. Dovrai leggere e utilizzare le credenziali dal tuo file di configurazione:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()Hai appena creato una connessione al database! Quando hai importato la libreria psycopg, hai tradotto il codice Python che hai scritto sopra per parlare con il database PostgreSQL (AWS Redshift).
Di per sé, AWS Redshift non comprenderebbe il codice sopra. Ma poiché hai importato la libreria psycopg, ora parli una lingua che AWS Redshift può comprendere.
La cosa bella di Python è che ha librerie per SQLite, MySQL e PostgreSQL. Potrai integrare le tecnologie con facilità.
Come scrivere una query SQL
Sentiti libero di scaricare i dati del calcio europeo nel tuo database PostgreSQL. Userò i suoi dati per questo esempio.
La connessione al database che hai creato nell'ultimo passaggio ti consente di scrivere SQL per quindi archiviare i dati in una struttura di dati compatibile con Python. Ora che hai stabilito una connessione al database, puoi scrivere una query SQL per iniziare a estrarre i dati:
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"Il lavoro non è ancora finito, però. Devi scrivere del codice Python aggiuntivo che esegua la query SQL:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()Quindi è necessario archiviare i dati restituiti in un frame di dati panda:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
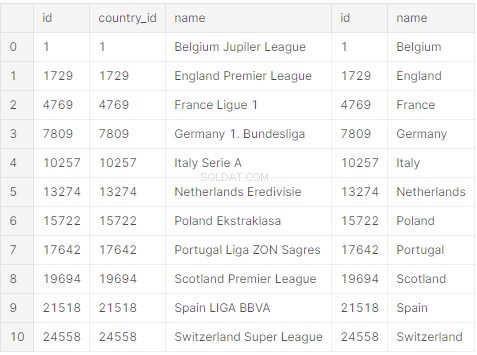
print(raw_initial_df)Dovresti ottenere un frame di dati panda (raw_initial_df) che assomigli a questo:
C'è un database per tutti

SQLite, MySQL e PostgreSQL hanno tutti i loro pro e contro. Quello che selezioni dovrebbe dipendere dal tuo progetto o dalle esigenze dell'azienda. Dovresti anche considerare ciò di cui hai bisogno ora rispetto a diversi anni dopo.
La cosa importante da ricordare è che Python può integrarsi con ogni tipo di database.
Questo articolo graffia la superficie per ciò che è possibile connettere Python a un database SQL. Adoro vedere i modi in cui i software si intersecano e si combinano per aggiungere un valore incredibile.
Se vuoi più di questo tipo di contenuto, puoi trovarmi su Course to Hire! Voglio aiutare più persone a imparare a programmare e ottenere un lavoro nel settore tecnologico. Si prega di contattarci per qualsiasi domanda o se si desidera semplicemente salutare :)