Nel precedente post sul blog, ho spiegato brevemente come abbiamo ottenuto i numeri delle prestazioni pubblicati nell'annuncio pglogical. In questo post del blog vorrei discutere i limiti di prestazioni delle soluzioni di replica logica in generale e anche come si applicano a pglogical.
replica fisica
Innanzitutto, vediamo come funziona la replica fisica (integrata in PostgreSQL dalla versione 9.0). Una figura in qualche modo semplificata con due soli due nodi appare così:
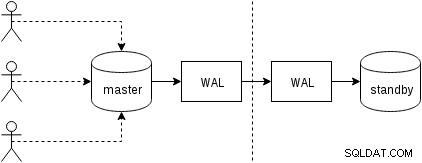
I client eseguono query sul nodo master, le modifiche vengono scritte in un registro delle transazioni (WAL) e copiate in rete su WAL sul nodo standby. Il processo di ripristino in standby in standby legge quindi le modifiche da WAL e le applica ai file di dati proprio come durante il ripristino. Se lo standby è in modalità "hot_standby", i client possono inviare query di sola lettura sul nodo mentre ciò sta accadendo.
Questo è molto efficiente perché c'è pochissima elaborazione aggiuntiva:le modifiche vengono trasferite e scritte in standby come un blob binario opaco. Ovviamente il ripristino non è gratuito (sia in termini di CPU che di I/O), ma è difficile diventare più efficienti di così.
Gli ovvi potenziali colli di bottiglia con la replica fisica sono la larghezza di banda della rete (trasferimento del WAL dal master allo standby) e anche l'I/O in standby, che può essere saturato dal processo di ripristino che spesso emette molte richieste di I/O casuali ( in alcuni casi più del master, ma non entriamo in quello).
replica logica
La replica logica è un po' più complicata, in quanto non si occupa del flusso WAL binario opaco, ma di un flusso di modifiche "logiche" (immagina le istruzioni INSERT, UPDATE o DELETE, anche se non è perfettamente corretto poiché abbiamo a che fare con la rappresentazione strutturata di i dati). Avere le modifiche logiche consente di fare cose interessanti come la risoluzione dei conflitti, replicare solo tabelle selezionate, su uno schema diverso o tra versioni diverse (o anche database diversi).
Esistono diversi modi per ottenere le modifiche:l'approccio tradizionale consiste nell'utilizzare i trigger che registrano le modifiche in una tabella e lasciare che un processo personalizzato legga continuamente tali modifiche e le applichi in standby eseguendo query SQL. E tutto questo è guidato da un processo demone esterno (o possibilmente più processi, in esecuzione su entrambi i nodi), come illustrato nella figura successiva

Questo è ciò che fanno slony o londiste e, sebbene abbia funzionato abbastanza bene, significa molto sovraccarico:ad esempio richiede l'acquisizione delle modifiche ai dati e la scrittura dei dati più volte (nella tabella originale e in una tabella "registro", e anche a WAL per entrambi i tavoli). Discuteremo altre fonti di sovraccarico in seguito. Sebbene pglogical debba raggiungere gli stessi obiettivi, li raggiunge in modo diverso, grazie a diverse funzionalità aggiunte alle recenti versioni di PostgreSQL (quindi non disponibili quando gli altri strumenti sono stati implementati):

Cioè, invece di mantenere un registro separato delle modifiche, pglogical si basa su WAL:ciò è possibile grazie a una decodifica logica disponibile in PostgreSQL 9.4, che consente di estrarre le modifiche logiche dal registro WAL. Grazie a questo pglogic non ha bisogno di trigger costosi e di solito può evitare di scrivere i dati due volte sul master (tranne che per grandi transazioni che potrebbero riversarsi su disco).
Dopo aver decodificato ogni transazione, viene trasferita in standby e il processo di applicazione applica le modifiche al database di standby. pglogical non applica le modifiche eseguendo query SQL regolari, ma a un livello inferiore, ignorando il sovraccarico associato all'analisi e alla pianificazione delle query SQL. Ciò offre a pglogic un vantaggio significativo rispetto alle soluzioni esistenti che passano tutte attraverso il livello SQL (pagando così l'analisi e la pianificazione).
Potenziali colli di bottiglia
Chiaramente, la replica logica è soggetta agli stessi colli di bottiglia della replica fisica, ovvero è possibile saturare la rete durante il trasferimento delle modifiche e l'I/O in standby quando le si applicano in standby. C'è anche una discreta quantità di sovraccarico dovuto a passaggi aggiuntivi non presenti in una replica fisica.
Abbiamo bisogno di raccogliere in qualche modo le modifiche logiche, mentre la replica fisica inoltra semplicemente il WAL come flusso di byte. Come già accennato, le soluzioni esistenti di solito si basano su trigger che scrivono le modifiche in una tabella "log". pglogical invece si basa sul registro write-ahead (WAL) e sulla decodifica logica per ottenere la stessa cosa, che è più economica dei trigger e inoltre non ha bisogno di scrivere i dati due volte nella maggior parte dei casi (con il bonus aggiuntivo che applichiamo automaticamente le modifiche in ordine di commit).
Questo non vuol dire che non ci siano opportunità per ulteriori miglioramenti, ad esempio la decodifica attualmente avviene solo una volta che la transazione viene impegnata, quindi con transazioni di grandi dimensioni ciò può aumentare il ritardo di replica. La replica fisica trasmette semplicemente le modifiche WAL all'altro nodo e quindi non ha questa limitazione. Le transazioni di grandi dimensioni possono anche riversarsi su disco, causando scritture duplicate, perché l'upstream deve archiviarle fino al commit e possono essere inviate al downstream.
È previsto un lavoro futuro per consentire a pglogic di avviare lo streaming di transazioni di grandi dimensioni mentre sono ancora in corso a monte, riducendo la latenza tra commit a monte e commit a valle e riducendo l'amplificazione della scrittura a monte.
Dopo che le modifiche sono state trasferite in standby, il processo di applicazione deve effettivamente applicarle in qualche modo. Come accennato nella sezione precedente, le soluzioni esistenti lo hanno fatto costruendo ed eseguendo comandi SQL, mentre pglogical ignora completamente il livello SQL e l'overhead associato.
Tuttavia, ciò non rende l'applicazione completamente gratuita poiché deve comunque eseguire cose come ricerche di chiavi primarie, aggiornare gli indici, eseguire trigger ed eseguire vari altri controlli. Ma è significativamente più economico dell'approccio basato su SQL. In un certo senso funziona in modo molto simile a COPY ed è particolarmente veloce su tabelle semplici senza trigger, chiavi esterne, ecc.
In tutte le soluzioni di replica logica, ciascuno di questi passaggi (decodifica e applicazione) avviene in un unico processo, quindi il tempo della CPU è piuttosto limitato. Questo è probabilmente il collo di bottiglia più urgente in tutte le soluzioni esistenti, perché potresti avere una macchina piuttosto robusta con decine o addirittura centinaia di client che eseguono query in parallelo, ma tutto ciò deve passare attraverso un unico processo che decodifica tali modifiche (sul master) e un processo che applica tali modifiche (in standby).
La limitazione del "processo singolo" può essere in qualche modo attenuata utilizzando database separati, poiché ogni database è gestito da un processo separato. Quando si tratta di un unico database, il lavoro futuro è pianificato per essere applicato in parallelo tramite un pool di lavoratori in background per alleviare questo collo di bottiglia.