Il vuoto è una delle funzionalità più importanti per recuperare le tuple eliminate nelle tabelle e negli indici. Senza il vuoto, tabelle e indici continuerebbero a crescere di dimensioni senza limiti. Questo post del blog descrive l'opzione PARALLEL per il comando VACUUM, che è stata introdotta di recente in PostgreSQL13.
Fasi di elaborazione sottovuoto
Prima di discutere in modo approfondito la nuova opzione, esaminiamo i dettagli di come funziona il vuoto.
Il vuoto (senza opzione FULL) è composto da cinque fasi. Ad esempio, per una tabella con due indici, funziona come segue:
- Fase di scansione dell'heap
- Scansiona il tavolo dall'alto e raccogli le tuple di immondizia in memoria.
- Indice fase di vuoto
- Aspira entrambi gli indici uno per uno.
- Fase di vuoto a mucchio
- Aspira il mucchio (tabella).
- Fase di pulizia dell'indice
- Pulisci entrambi gli indici uno per uno.
- Fase di troncamento dell'heap
- Tronca le pagine vuote alla fine della tabella.
Nella fase di scansione dell'heap, il vuoto può utilizzare la Mappa della visibilità per saltare l'elaborazione di pagine note come prive di immondizia, mentre sia nella fase di vuoto dell'indice che nella fase di pulizia dell'indice, a seconda dei metodi di accesso all'indice, un'intera scansione dell'indice è richiesto.
Ad esempio, gli indici btree, il tipo di indice più popolare, richiedono un'intera scansione dell'indice per rimuovere le tuple di immondizia ed eseguire la pulizia dell'indice. Poiché il vuoto viene sempre eseguito da un unico processo, gli indici vengono elaborati uno per uno. Il tempo di esecuzione più lungo del vuoto soprattutto su un tavolo di grandi dimensioni spesso infastidisce gli utenti.
Opzione PARALLELO
Per risolvere questo problema, ho proposto una patch per parallelizzare il vuoto nel 2016. Dopo un lungo processo di revisione e molte riforme, l'opzione PARALLEL è stata introdotta in PostgreSQL 13. Con questa opzione, il vuoto può eseguire la fase di vuoto dell'indice e la fase di pulizia dell'indice con lavoratori paralleli. I lavoratori del vuoto paralleli si avviano prima di entrare nella fase di vuoto dell'indice o nella fase di pulizia dell'indice ed escono alla fine della fase. Un singolo lavoratore viene assegnato a un indice. Il vuoto parallelo è sempre disabilitato in autovuoto.
L'opzione PARALLELO senza un'opzione argomento intero calcolerà automaticamente il grado parallelo in base al numero di indici sulla tabella.
VACUUM (PARALLEL) tbl;
Poiché il processo leader elabora sempre un indice, il numero massimo di lavoratori paralleli sarà (il numero di indici nella tabella – 1), ulteriormente limitato a max_parallel_maintenance_workers. L'indice di destinazione deve essere maggiore o uguale a min_parallel_index_scan_size.
L'opzione PARALLEL consente di specificare il grado parallelo passando un valore intero diverso da zero. L'esempio seguente utilizza tre lavoratori, per un totale di quattro processi in parallelo.
VACUUM (PARALLEL 3) tbl;
L'opzione PARALLELO è attivata per impostazione predefinita; per disabilitare il vuoto parallelo, impostare max_parallel_maintenance_workers su 0 o specificare PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Osservando l'output VACUUM VERBOSE, possiamo vedere che un lavoratore sta elaborando l'indice.
Le informazioni stampate come "da lavoratore parallelo" sono riportate dal lavoratore.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Metodi di accesso all'indice Vs grado di parallelismo
Il vuoto non esegue necessariamente la fase di vuoto dell'indice e la fase di pulizia dell'indice in parallelo. Se la dimensione dell'indice è piccola o se è noto che il processo può essere completato rapidamente, il costo dell'avvio e della gestione dei lavoratori paralleli per la parallelizzazione provoca invece un sovraccarico. A seconda dei metodi di accesso all'indice e delle sue dimensioni, è meglio non eseguire queste fasi con un processo di vacuum worker parallelo.
Ad esempio, nell'aspirazione di un indice btree sufficientemente grande, la fase di vuoto dell'indice dell'indice può essere eseguita da un lavoratore del vuoto parallelo perché richiede sempre una scansione dell'intero indice, mentre la fase di pulizia dell'indice viene eseguita da un lavoratore del vuoto parallelo se l'indice il vuoto non viene eseguito (ad esempio, non c'è spazzatura sul tavolo). Questo perché ciò che gli indici btree richiedono nella fase di pulizia dell'indice è raccogliere le statistiche dell'indice, che vengono raccolte anche durante la fase di vuoto dell'indice. D'altra parte, gli indici hash non richiedono sempre una scansione dell'indice nella fase di pulizia dell'indice.
Per supportare diversi tipi di strategie di vuoto dell'indice, gli sviluppatori di metodi di accesso all'indice possono specificare questi comportamenti impostando flag su amparallelvacuumoptions campo della IndexAmRoutine struttura. I flag disponibili sono i seguenti:
- VACUUM_OPTION_NO_PARALLEL (predefinito)
- il vuoto parallelo è disabilitato in entrambe le fasi.
- VACUUM_OPTION_PARALLEL_BULKDEL
- la fase di vuoto dell'indice può essere eseguita in parallelo.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- la fase di pulizia dell'indice può essere eseguita in parallelo se la fase di vuoto dell'indice non è ancora stata eseguita.
- VACUUM_OPTION_PARALLEL_CLEANUP
- la fase di pulizia dell'indice può essere eseguita in parallelo anche se la fase di vuoto dell'indice ha già elaborato l'indice.
La tabella seguente mostra come l'indice AM integrato in PostgreSQL supporta il vuoto parallelo.
| nbtree | hash | gin | gist | spgist | brin | fioritura | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Vedi 'src/include/command/vacuum.h' per maggiori dettagli.
Verifica delle prestazioni
Ho valutato le prestazioni del vuoto parallelo sul mio laptop (Core i7 2,6 GHz, 16 GB RAM, 512 GB SSD). La dimensione della tabella è di 6 GB e ha otto indici da 3 GB. La relazione totale è di 30 GB, che non si adatta alla RAM della macchina. Per ogni valutazione, ho sporcato in modo uniforme diverse percentuali del tavolo dopo aver passato l'aspirapolvere, quindi ho eseguito il vuoto cambiando il grado parallelo. Il grafico sottostante mostra il tempo di esecuzione del vuoto.
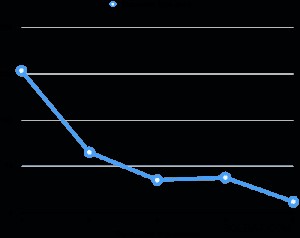
In tutte le valutazioni il tempo di esecuzione del vuoto dell'indice rappresentava più del 95% del tempo di esecuzione totale. Pertanto, la parallelizzazione della fase di vuoto dell'indice ha contribuito a ridurre notevolmente il tempo di esecuzione del vuoto.
Grazie
Un ringraziamento speciale ad Amit Kapila per la revisione, i consigli e l'impegno di questa funzione in PostgreSQL 13. Apprezzo tutti gli sviluppatori coinvolti in questa funzione per la revisione, il test e la discussione.