Un paio di anni fa (al pgconf.eu 2014 a Madrid) ho presentato un discorso chiamato "Performance Archaeology" che ha mostrato come le prestazioni sono cambiate nelle recenti versioni di PostgreSQL. Ho fatto quel discorso perché penso che la visione a lungo termine sia interessante e potrebbe darci spunti che potrebbero essere molto preziosi. Per le persone che lavorano effettivamente sul codice PostgreSQL come me, è una guida utile per lo sviluppo futuro e per gli utenti di PostgreSQL può aiutare a valutare gli aggiornamenti.
Quindi ho deciso di ripetere questo esercizio e di scrivere un paio di post sul blog che analizzano le prestazioni per un certo numero di versioni di PostgreSQL. Nel discorso del 2014 ho iniziato con PostgreSQL 7.4, che a quel punto aveva circa 10 anni (rilasciato nel 2003). Questa volta inizierò con PostgreSQL 8.3, che ha circa 12 anni.
Perché non ricominciare con PostgreSQL 7.4? Ci sono circa tre ragioni principali per cui ho deciso di iniziare con PostgreSQL 8.3. In primo luogo, la pigrizia generale. Più vecchia è la versione, più difficile può essere da costruire usando le versioni correnti del compilatore ecc. In secondo luogo, ci vuole tempo per eseguire benchmark adeguati, specialmente con quantità maggiori di dati, quindi l'aggiunta di una singola versione principale può facilmente aggiungere un paio di giorni di tempo macchina. Semplicemente non sembrava ne valesse la pena. Infine, 8.3 ha introdotto una serie di importanti modifiche:miglioramenti dell'autovacuum (abilitati per impostazione predefinita, processi di lavoro simultanei, …), ricerca full-text integrata nel core, punti di controllo diffusi e così via. Quindi penso che abbia perfettamente senso iniziare con PostgreSQL 8.3. Che è stato rilasciato circa 12 anni fa, quindi questo confronto coprirà effettivamente un periodo di tempo più lungo.
Ho deciso di confrontare tre tipi di carico di lavoro di base:OLTP, analisi e ricerca full-text. Penso che OLTP e analisi siano scelte abbastanza ovvie, poiché la maggior parte delle applicazioni sono un mix di questi due tipi di base. La ricerca full-text mi consente di dimostrare miglioramenti in tipi speciali di indici, che vengono utilizzati anche per indicizzare tipi di dati popolari come JSONB, tipi utilizzati da PostGIS ecc.
Perché farlo?
Ne vale davvero la pena? Dopotutto, facciamo continuamente benchmark durante lo sviluppo per mostrare che una patch aiuta e/o che non causa regressioni, giusto? Il problema è che di solito si tratta solo di benchmark "parziali", che confrontano due commit particolari e di solito con una selezione abbastanza limitata di carichi di lavoro che riteniamo possano essere rilevanti. Il che ha perfettamente senso:semplicemente non puoi eseguire una batteria completa di carichi di lavoro per ogni commit.
Di tanto in tanto (di solito poco dopo il rilascio di una nuova versione principale di PostgreSQL) le persone eseguono test confrontando la nuova versione con la precedente, il che è carino e ti incoraggio a eseguire tali benchmark (che si tratti di una sorta di benchmark standard o qualcosa di specifico per la tua applicazione). Ma è difficile combinare questi risultati in una visione a lungo termine, perché quei test utilizzano configurazioni e hardware diversi (di solito uno più recente per la versione più recente) e così via. Quindi è difficile esprimere giudizi chiari sui cambiamenti in generale.
Lo stesso vale per le prestazioni dell'applicazione, che ovviamente è il "benchmark definitivo". Ma le persone potrebbero non eseguire l'aggiornamento a tutte le versioni principali (a volte possono saltare un paio di versioni, ad esempio dalla 9.5 alla 12). E quando eseguono l'aggiornamento, è spesso combinato con aggiornamenti hardware, ecc. Per non parlare del fatto che le applicazioni si evolvono nel tempo (nuove funzionalità, complessità aggiuntiva), la quantità di dati e il numero di utenti simultanei crescono, ecc.
Questo è ciò che questa serie di blog cerca di mostrare:tendenze a lungo termine nelle prestazioni di PostgreSQL per alcuni carichi di lavoro di base, in modo che noi, gli sviluppatori, proviamo una sensazione calda e confusa sul buon lavoro nel corso degli anni. E per mostrare agli utenti che anche se PostgreSQL è un prodotto maturo a questo punto, ci sono ancora miglioramenti significativi in ogni nuova versione principale.
Non è mio obiettivo utilizzare questi benchmark per il confronto con altri prodotti di database o produrre risultati per soddisfare qualsiasi classifica ufficiale (come quella TPC-H). Il mio obiettivo è semplicemente quello di formarmi come sviluppatore PostgreSQL, magari identificare e indagare su alcuni problemi e condividere i risultati con gli altri.
Confronto equo?
Non credo che tali confronti tra versioni rilasciate in 12 anni non possano essere del tutto equi, perché qualsiasi software è sviluppato in un contesto particolare:l'hardware è un buon esempio, per un sistema di database. Se guardi le macchine che hai usato 12 anni fa, quanti core avevano, quanta RAM? Che tipo di spazio di archiviazione hanno utilizzato?
Un tipico server di fascia media nel 2008 aveva forse 8-12 core, 16 GB di RAM e un RAID con un paio di unità SAS. Un tipico server di fascia media oggi potrebbe avere un paio di dozzine di core, centinaia di GB di RAM e spazio di archiviazione SSD.
Lo sviluppo del software è organizzato per priorità:ci sono sempre più attività potenziali di quante ne hai tempo, quindi è necessario scegliere attività con il miglior rapporto costi/benefici per i tuoi utenti (soprattutto quelli che finanziano il progetto, direttamente o indirettamente). E nel 2008 alcune ottimizzazioni probabilmente non erano ancora rilevanti:la maggior parte delle macchine non aveva quantità estreme di RAM, quindi l'ottimizzazione per buffer condivisi di grandi dimensioni non valeva ancora la pena, ad esempio. E molti colli di bottiglia della CPU sono stati messi in ombra dall'I/O, perché la maggior parte delle macchine disponeva di una memoria "spinning rust".
Nota:ovviamente, anche allora c'erano clienti che utilizzavano macchine piuttosto grandi. Alcuni hanno utilizzato la community Postgres con varie modifiche, altri hanno deciso di eseguire uno dei vari fork di Postgres con funzionalità aggiuntive (ad es. parallelismo massiccio, query distribuite, utilizzo di FPGA ecc.). E questo ha influenzato anche lo sviluppo della comunità, ovviamente.
Poiché le macchine più grandi sono diventate più comuni nel corso degli anni, più persone potevano permettersi macchine con grandi quantità di RAM e conteggi di core elevati, spostando il rapporto costi/benefici. I colli di bottiglia sono stati studiati e risolti, consentendo alle versioni più recenti di funzionare meglio.
Ciò significa che un benchmark come questo è sempre un po' ingiusto:favorirà la versione precedente o quella più recente, a seconda della configurazione (hardware, configurazione). Ho provato a scegliere l'hardware e i parametri di configurazione in modo che non sia troppo male per le versioni precedenti, però.
Il punto che sto cercando di sottolineare è che questo non significa che le versioni precedenti di PostgreSQL fossero una schifezza:è così che funziona lo sviluppo del software. Affronta i colli di bottiglia che i tuoi utenti potrebbero incontrare, non i colli di bottiglia che potrebbero incontrare tra 10 anni.
Hardware
Preferisco fare benchmark su hardware fisico a cui ho accesso diretto, perché ciò mi consente di controllare tutti i dettagli, ho accesso a tutti i dettagli e così via. Quindi ho usato la macchina che ho nel nostro ufficio:niente di speciale, ma si spera abbastanza buono per questo scopo.
- 2x E5-2620 v4 (16 core, 32 thread)
- 64 GB di RAM
- SSD Intel Optane 900P 280 GB NVMe (dati)
- 3 x 7.2k SATA RAID0 (tablespace temporaneo)
- kernel 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Ho utilizzato anche una seconda macchina, molto più piccola, con soli 4 core e 8GB di RAM, che generalmente mostra gli stessi miglioramenti/regressioni, solo meno pronunciati.
panca di gioco
Come strumento di benchmarking ho utilizzato il noto pgbench, utilizzando la versione più recente (da PostgreSQL 13) per testare tutte le versioni. Ciò elimina possibili distorsioni dovute alle ottimizzazioni effettuate in pgbench nel tempo, rendendo i risultati più comparabili.
Il benchmark verifica una serie di casi diversi, variando un numero di parametri, vale a dire:
scala
- piccolo:i dati si inseriscono in buffer condivisi, mostrano problemi di blocco ecc.
- medio:dati più grandi dei buffer condivisi ma si adattano alla RAM, solitamente vincolati alla CPU (o possibilmente I/O per carichi di lavoro di lettura-scrittura)
- grande:dati più grandi della RAM, principalmente legati all'I/O
modalità
- sola lettura – pgbench -S
- lettura-scrittura – pgbench -N
conta i clienti
- 1, 4, 8, 16, 32, 64, 128, 256
- il numero di thread di pgbench (-j) è stato modificato di conseguenza
Risultati
OK, diamo un'occhiata ai risultati. Presenterò prima i risultati dell'archiviazione NVMe, quindi mostrerò alcuni risultati interessanti utilizzando l'archiviazione RAID SATA.
SSD NVMe / sola lettura
Per il piccolo set di dati (che si adatta completamente ai buffer condivisi), i risultati di sola lettura sono simili a questo:
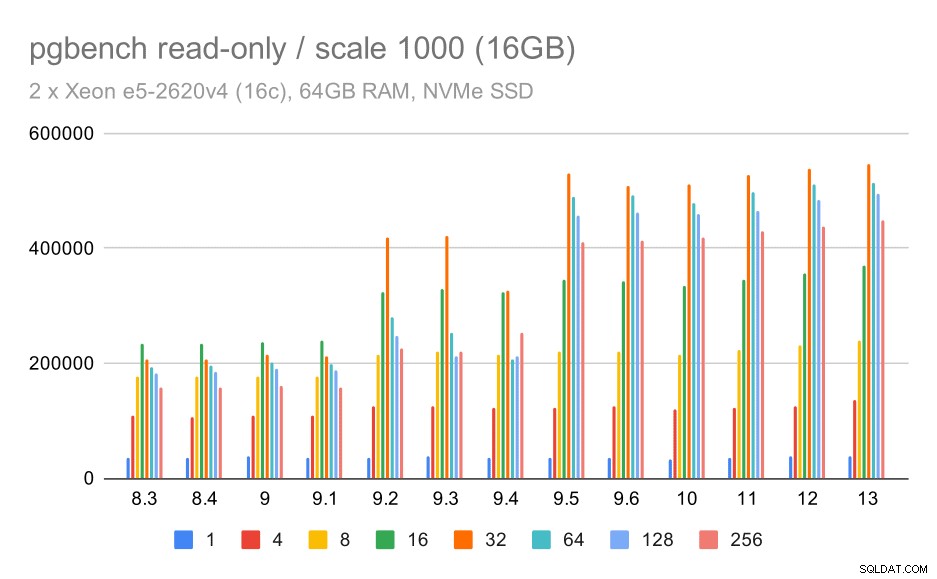
risultati di pgbench / sola lettura su set di dati di piccole dimensioni (scala 100, ovvero 1,6 GB)
Chiaramente, c'è stato un aumento significativo del throughput in 9.2, che conteneva una serie di miglioramenti delle prestazioni, ad esempio il percorso rapido per il blocco. Il throughput per un singolo client in realtà diminuisce leggermente, da 47.000 tps a solo circa 42.000 tps. Ma per un numero di clienti più elevato, il miglioramento in 9.2 è abbastanza chiaro.
risultati pgbench / sola lettura su set di dati medio (scala 1000, ovvero 16 GB)
Per il set di dati medio (che è più grande dei buffer condivisi ma si adatta ancora alla RAM) sembra esserci qualche miglioramento anche in 9.2, sebbene non così chiaro come sopra, seguito da un miglioramento molto più chiaro in 9.5 molto probabilmente grazie ai miglioramenti della scalabilità del blocco .
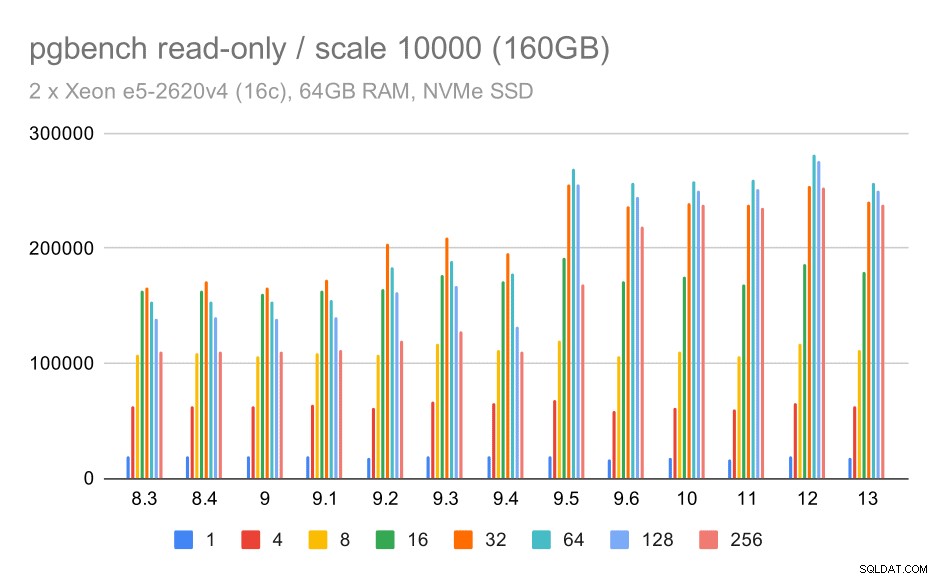
risultati pgbench / sola lettura su set di dati di grandi dimensioni (scala 10000, ovvero 160 GB)
Sul set di dati più grande, che riguarda principalmente la capacità di utilizzare in modo efficiente lo spazio di archiviazione, c'è anche un po' di accelerazione, molto probabilmente anche grazie ai miglioramenti 9.5.
NVMe SSD / lettura-scrittura
Anche i risultati di lettura e scrittura mostrano alcuni miglioramenti, sebbene non così pronunciati. Sul piccolo set di dati, i risultati appaiono così:
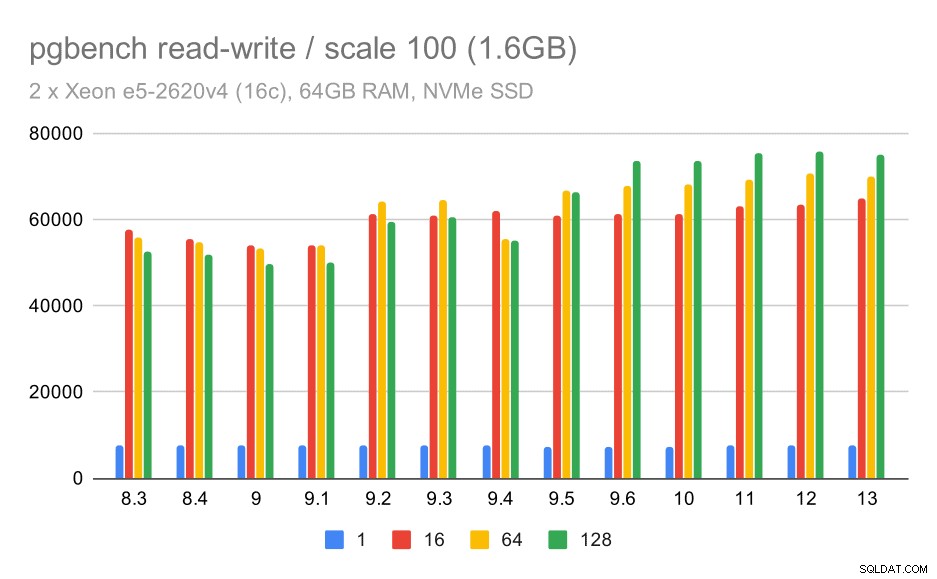
risultati pgbench / lettura-scrittura su set di dati di piccole dimensioni (scala 100, ovvero 1,6 GB)
Quindi un modesto miglioramento da circa 52k a 75k tps con un numero sufficiente di clienti.
Per il set di dati medio, il miglioramento è molto più chiaro:da circa 27.000 a 63.000 tps, ovvero il throughput è più che raddoppiato.
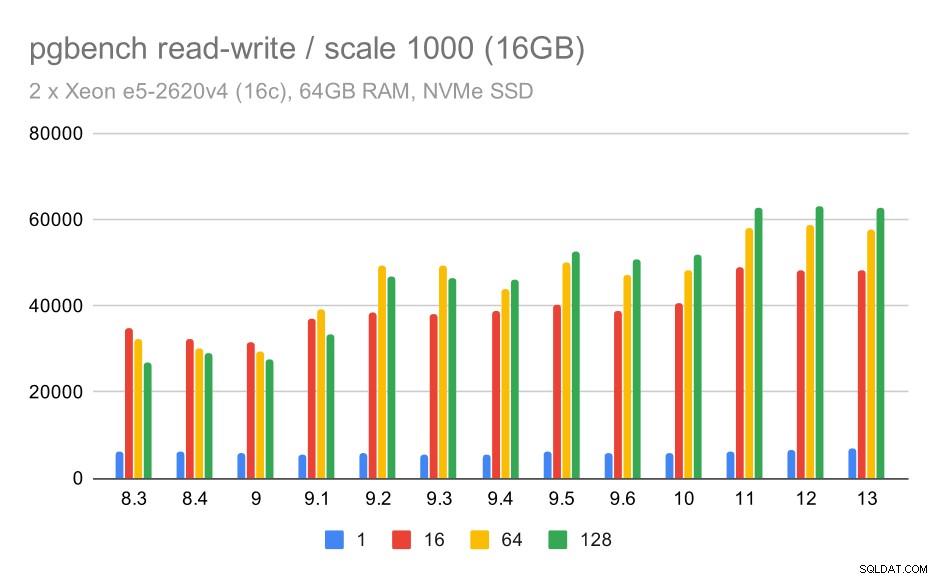
risultati pgbench / lettura-scrittura su set di dati medio (scala 1000, ovvero 16 GB)
Per il set di dati più ampio, vediamo un miglioramento complessivo simile, ma sembra esserci una regressione tra 9,5 e 11.
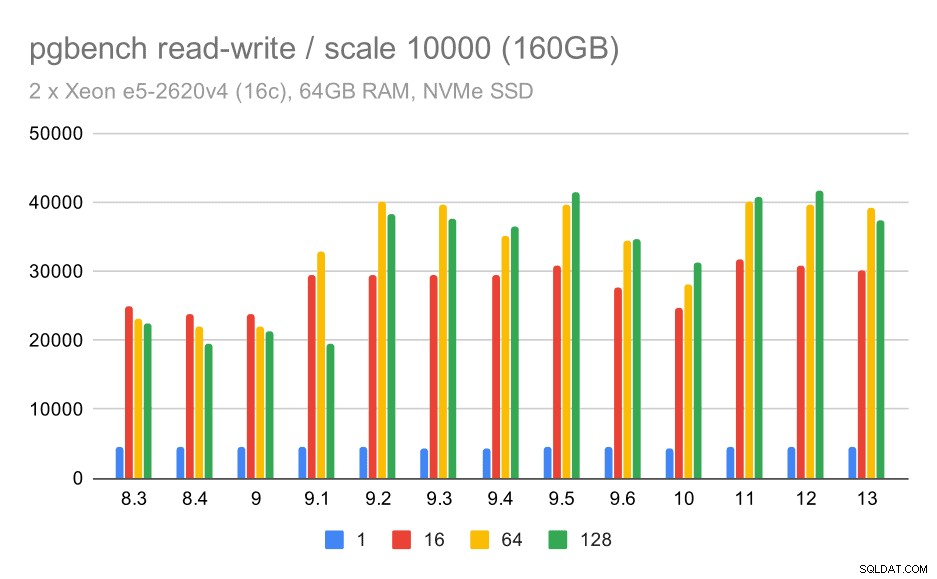
risultati pgbench / lettura-scrittura su set di dati di grandi dimensioni (scala 10000, ovvero 160 GB)
SATA RAID / sola lettura
Per l'archiviazione SATA RAID, i risultati di sola lettura non sono così belli. Possiamo ignorare i piccoli e medi set di dati, per i quali il sistema di archiviazione è irrilevante. Per l'ampio set di dati, il throughput è piuttosto rumoroso ma sembra effettivamente diminuire nel tempo, in particolare da PostgreSQL 9.6. Non so quale sia la ragione di ciò (nulla nelle note di rilascio 9.6 spicca come un candidato chiaro), ma sembra una sorta di regressione.
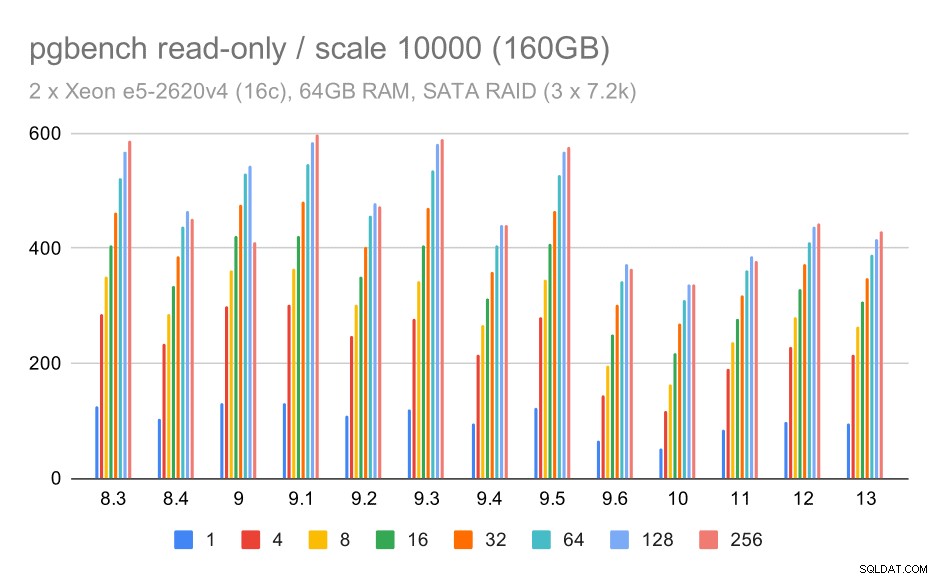
risultati pgbench su SATA RAID / sola lettura su set di dati di grandi dimensioni (scala 10000, ovvero 160 GB)
SATA RAID/lettura-scrittura
Tuttavia, il comportamento di lettura-scrittura sembra molto più piacevole. Sul piccolo set di dati, il throughput aumenta da circa 600 tps a oltre 6000 tps. Scommetto che questo è dovuto ai miglioramenti apportati al commit di gruppo in 9.1 e 9.2.
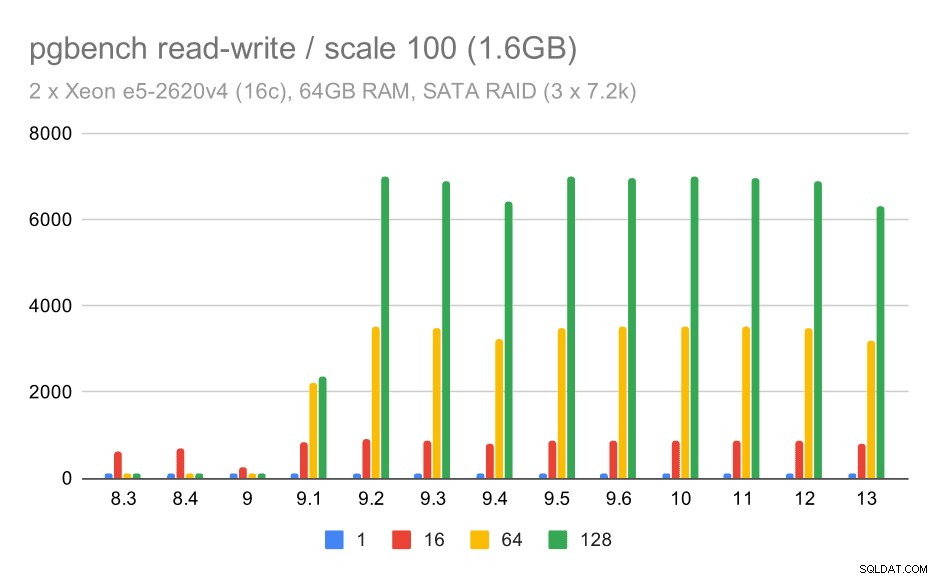
risultati di pgbench su RAID SATA / lettura-scrittura su set di dati di piccole dimensioni (scala 100, ovvero 1,6 GB)
Per le scale medie e grandi possiamo vedere miglioramenti simili, ma minori, perché lo storage deve anche gestire le richieste di I/O per leggere e scrivere i blocchi di dati. Per la scala media dobbiamo solo eseguire le scritture (poiché i dati entrano nella RAM), per la scala grande dobbiamo anche eseguire le letture, quindi il throughput massimo è ancora più basso.
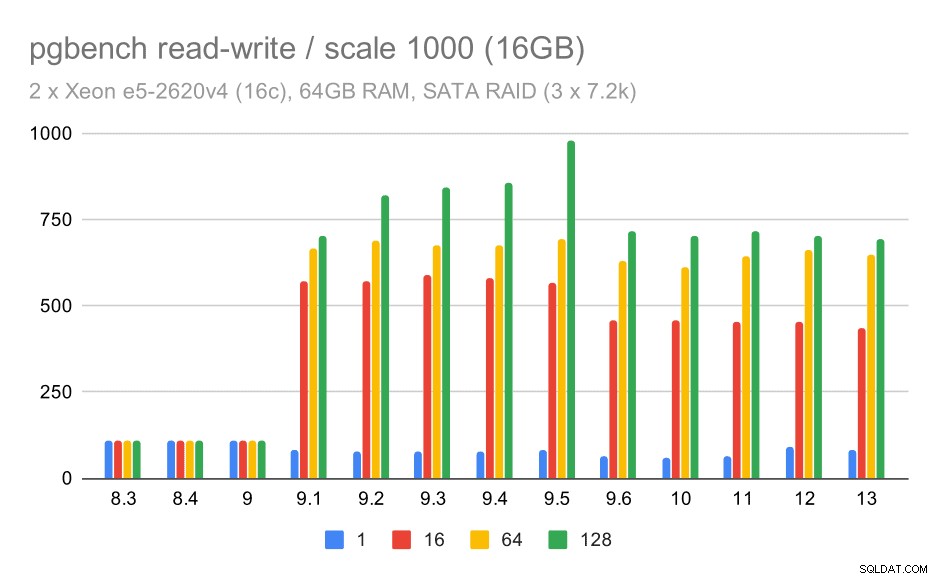
risultati pgbench su SATA RAID / lettura-scrittura su set di dati medio (scala 1000, ovvero 16 GB)
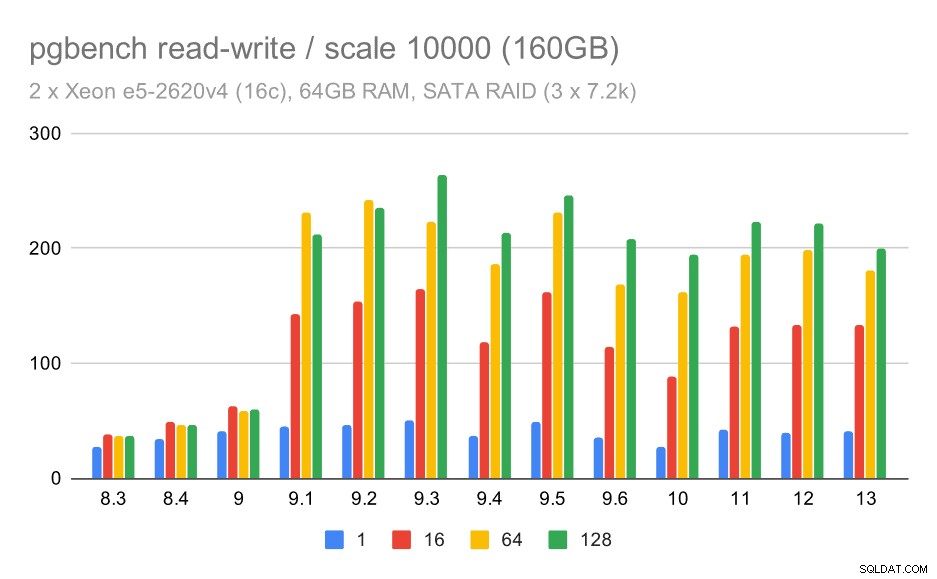
risultati pgbench su RAID SATA / lettura-scrittura su set di dati di grandi dimensioni (scala 10000, ovvero 160 GB)
Riepilogo e futuro
Per riassumere, per la configurazione NVMe le conclusioni sembrano essere piuttosto positive. Per il carico di lavoro di sola lettura c'è un moderato aumento della velocità nella 9.2 e un significativo aumento della velocità nella 9.5, grazie alle ottimizzazioni della scalabilità, mentre per il carico di lettura e scrittura le prestazioni sono migliorate di circa 2 volte nel tempo, in più versioni/passi.
Tuttavia, con la configurazione SATA RAID le conclusioni sono alquanto contrastanti. Nel caso del carico di lavoro di sola lettura c'è molta variabilità/rumore e possibile regressione in 9.6. Per il carico di lavoro di lettura e scrittura, c'è un enorme aumento di velocità in 9.1 in cui il throughput è aumentato improvvisamente da 100 tps a circa 600 tps.
Che dire dei miglioramenti nelle future versioni di PostgreSQL? Non ho un'idea molto chiara di quale sarà il prossimo grande miglioramento:sono tuttavia sicuro che altri hacker di PostgreSQL avranno idee brillanti che renderanno le cose più efficienti o consentiranno di sfruttare le risorse hardware disponibili. La patch per migliorare la scalabilità con molte connessioni o la patch per aggiungere il supporto per i buffer WAL non volatili sono esempi di tali miglioramenti. Potremmo vedere alcuni miglioramenti radicali all'archiviazione PostgreSQL (formato su disco più efficiente, utilizzo di I/O diretto ecc.), Indicizzazione, ecc.