Nella prima parte di questa serie di blog, ho presentato un paio di risultati di benchmark che mostrano come sono cambiate le prestazioni di PostgreSQL OLTP dalla versione 8.3, rilasciata nel 2008. In questa parte ho intenzione di fare la stessa cosa ma per query analitiche/BI, elaborando grandi quantità di dati.
Esistono numerosi benchmark del settore per testare questo carico di lavoro, ma probabilmente il più comunemente usato è TPC-H, quindi è quello che userò per questo post sul blog. C'è anche TPC-DS, un altro benchmark TPC per testare i sistemi di supporto alle decisioni, che può essere visto come un'evoluzione o una sostituzione di TPC-H. Ho deciso di attenermi a TPC-H per un paio di motivi.
In primo luogo, TPC-DS è molto più complesso, sia in termini di schema (più tabelle) che di numero di query (22 contro 99). Regolarlo correttamente, in particolare quando si ha a che fare con più versioni di PostgreSQL, sarebbe molto più difficile. In secondo luogo, alcune delle query TPC-DS utilizzano funzionalità che non sono supportate dalle versioni precedenti di PostgreSQL (ad es. set di raggruppamento), rendendo tali query irrilevanti per alcune versioni. E infine, direi che le persone hanno molta più familiarità con TPC-H rispetto a TPC-DS.
L'obiettivo di questo non è quello di consentire il confronto con altri prodotti di database, ma solo di fornire una ragionevole caratterizzazione a lungo termine su come si sono evolute le prestazioni di PostgreSQL da PostgreSQL 8.3.
Nota :Per un'analisi molto interessante del benchmark TPC-H, consiglio vivamente il documento "TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark" di Boncz, Neumann ed Erling.
L'hardware
La maggior parte dei risultati in questo post del blog proviene dalla "scatola più grande" che ho nel nostro ufficio, che ha questi parametri:
- 2x E5-2620 v4 (16 core, 32 thread)
- 64 GB di RAM
- SSD Intel Optane 900P 280 GB NVMe (dati)
- 3 x 7.2k SATA RAID0 (tablespace temporaneo)
- kernel 5.6.15, filesystem ext4
Sono sicuro che puoi acquistare macchine significativamente più robuste, ma credo che questo sia abbastanza buono da fornirci dati rilevanti. C'erano due varianti di configurazione:una con parallelismo disabilitato, una con parallelismo abilitato. La maggior parte dei valori dei parametri sono gli stessi in entrambi i casi, sintonizzati sulle risorse hardware disponibili (CPU, RAM, storage). Puoi trovare informazioni più dettagliate sulla configurazione alla fine di questo post.
Il punto di riferimento
Voglio chiarire che non è mio obiettivo implementare un benchmark TPC-H valido che possa superare tutti i criteri richiesti dal TPC. Il mio obiettivo è valutare come le prestazioni di diverse query analitiche sono cambiate nel tempo, non inseguire una misura astratta delle prestazioni per dollaro o qualcosa del genere.
Quindi ho deciso di utilizzare solo un sottoinsieme di TPC-H, essenzialmente basta caricare i dati ed eseguire le 22 query (stessi parametri su tutte le versioni). Non ci sono aggiornamenti dei dati, il set di dati è statico dopo il caricamento iniziale. Ho selezionato un certo numero di fattori di scala, 1, 10 e 75, in modo da avere risultati per i buffer fit-in-shared (1), fit-in-memory (10) e more-than-memory (75) . Sceglierei 100 per renderlo una "bella sequenza", che in alcuni casi non si adatterebbe allo spazio di archiviazione da 280 GB (grazie a indici, file temporanei, ecc.). Si noti che il fattore di scala 75 non è nemmeno riconosciuto da TPC-H come fattore di scala valido.
Ma ha senso confrontare set di dati da 1 GB o 10 GB? Le persone tendono a concentrarsi su database molto più grandi, quindi potrebbe sembrare un po' sciocco preoccuparsi di testarli. Ma non credo che sarebbe utile:la stragrande maggioranza dei database in circolazione è piuttosto piccola, secondo la mia esperienza. E anche quando l'intero database è grande, le persone di solito lavorano solo con un piccolo sottoinsieme di esso:dati recenti, ordini irrisolti, ecc. Quindi credo che abbia senso testare anche con quei piccoli set di dati.
Caricamenti dati
Per prima cosa, vediamo quanto tempo ci vuole per caricare i dati nel database, senza e con parallelismo. Mostrerò solo i risultati del set di dati da 75 GB, perché il comportamento generale è quasi lo stesso per i casi più piccoli.
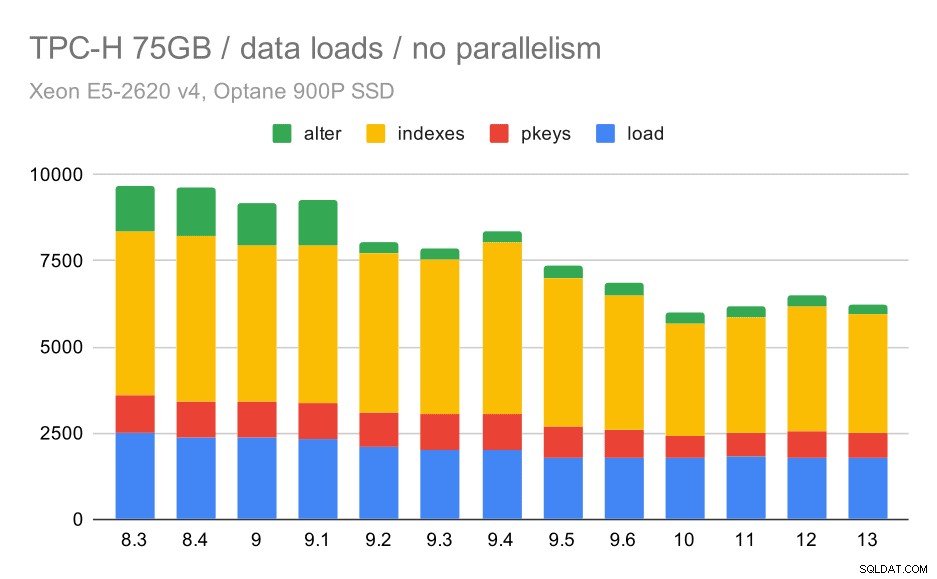
Durata del caricamento dei dati TPC-H:scalabilità di 75 GB, nessun parallelismo
Puoi vedere chiaramente che c'è una tendenza costante di miglioramenti, riducendo circa il 30% della durata semplicemente migliorando l'efficienza in tutti e quattro i passaggi:COPIA, creazione di chiavi primarie e indici e (soprattutto) configurazione di chiavi esterne. Il miglioramento "alter" in 9.2 è particolarmente evidente.
| COPIA | PKEYS | INDICI | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Ora, vediamo come l'abilitazione del parallelismo cambia il comportamento. Il grafico seguente confronta i risultati con il parallelismo abilitato, contrassegnati da "(p)" - con i risultati con il parallelismo disabilitato.
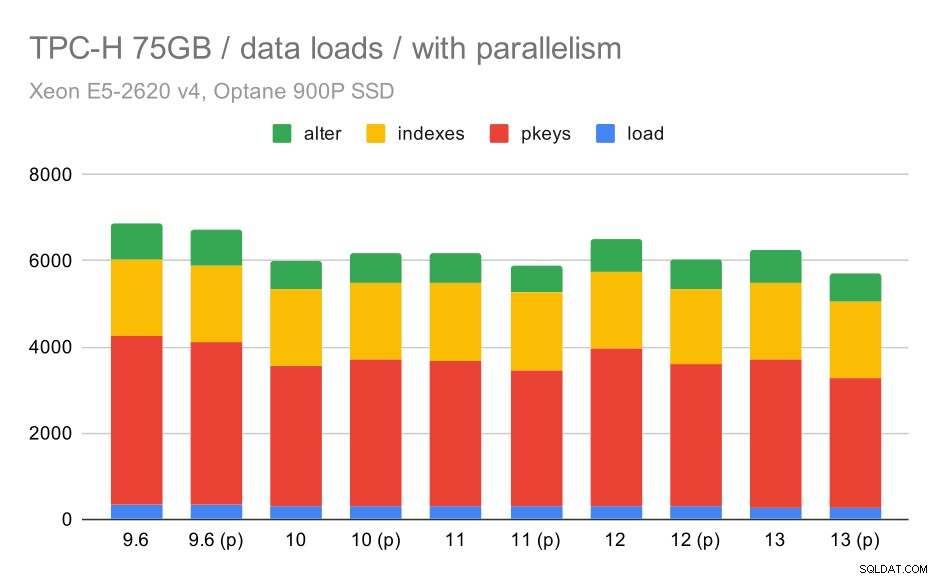
Durata del caricamento dei dati TPC-H:scalabilità di 75 GB, parallelismo abilitato.
Sfortunatamente, sembra che l'effetto del parallelismo sia molto limitato in questo test:aiuta un po', ma le differenze sono piuttosto piccole. Quindi il miglioramento complessivo rimane di circa il 30%.
| COPIA | PKEYS | INDICI | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Query
Ora possiamo dare un'occhiata alle query. TPC-H ha 22 modelli di query:ho generato un set di query effettive e le ho eseguite due volte su tutte le versioni, prima dopo aver eliminato tutte le cache e riavviato l'istanza, quindi con la cache riscaldata. Tutti i numeri presentati nelle classifiche sono i migliori di queste due serie (nella maggior parte dei casi è la seconda, ovviamente).
Nessun parallelismo
Senza parallelismo, i risultati sul set di dati più piccolo sono abbastanza chiari:ogni barra è divisa in più parti con colori diversi per ciascuna delle 22 query. È difficile dire quale parte corrisponda a quale query esatta, ma è sufficiente per identificare i casi in cui una query migliora o peggiora notevolmente tra due esecuzioni. Ad esempio nel primo grafico è molto chiaro che il Q21 è diventato molto più veloce tra 8,3 e 8,4.
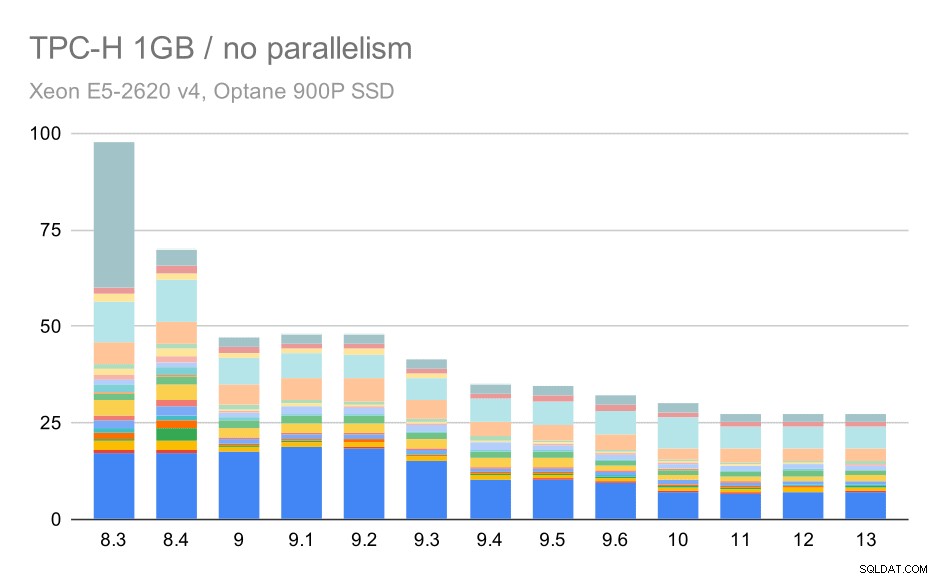
Query TPC-H su set di dati di piccole dimensioni (1 GB) – parallelismo disabilitato
Per la scala da 10 GB, i risultati sono piuttosto difficili da interpretare, perché su 8.3 una delle query (Q21) impiega così tanto tempo per essere eseguita che sminuisce tutto il resto.
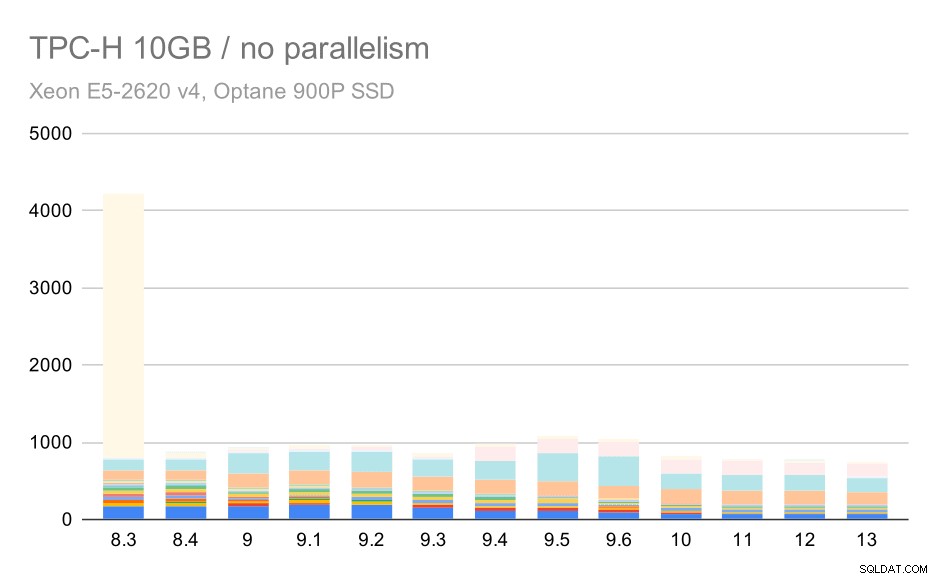
Query TPC-H su set di dati medi (10 GB) – parallelismo disabilitato
Quindi vediamo come sarebbe il grafico senza Q21:
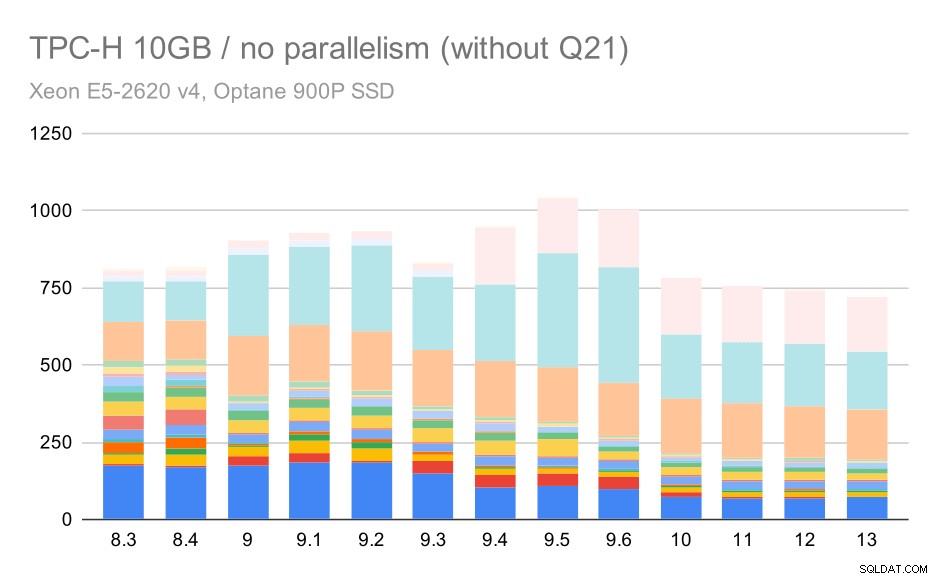
Query TPC-H su set di dati medi (10 GB):parallelismo disabilitato, senza problemi nel secondo trimestre
OK, è più facile da leggere. Possiamo vedere chiaramente che la maggior parte delle query (fino a Q17) è diventata più veloce, ma poi due delle query (Q18 e Q20) sono diventate leggermente più lente. Vedremo un problema simile sul set di dati più grande, quindi discuterò quale potrebbe essere la causa principale.
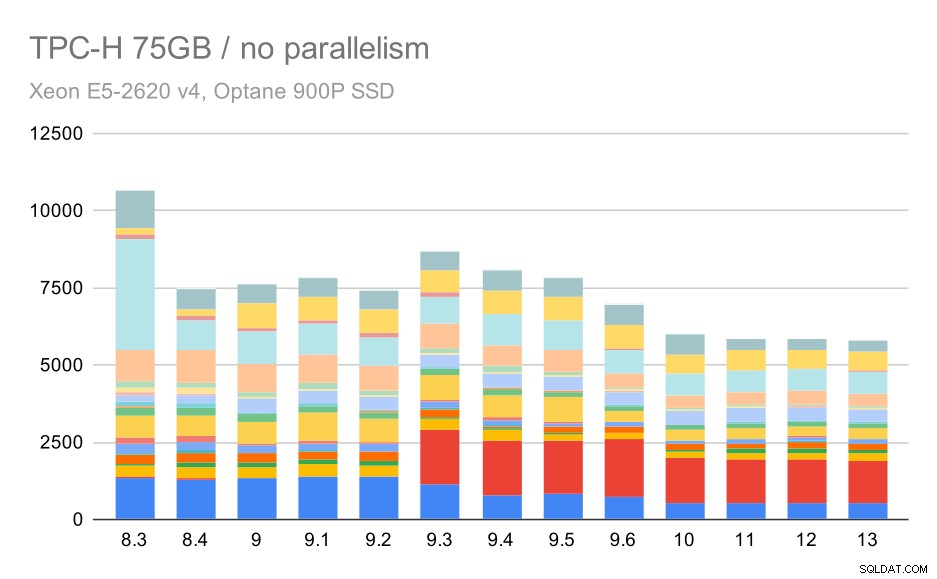
Query TPC-H su set di dati di grandi dimensioni (75 GB) – parallelismo disabilitato
Ancora una volta, vediamo un improvviso aumento per una delle query in 9.3 – questa volta è il secondo trimestre, senza il quale il grafico appare così:
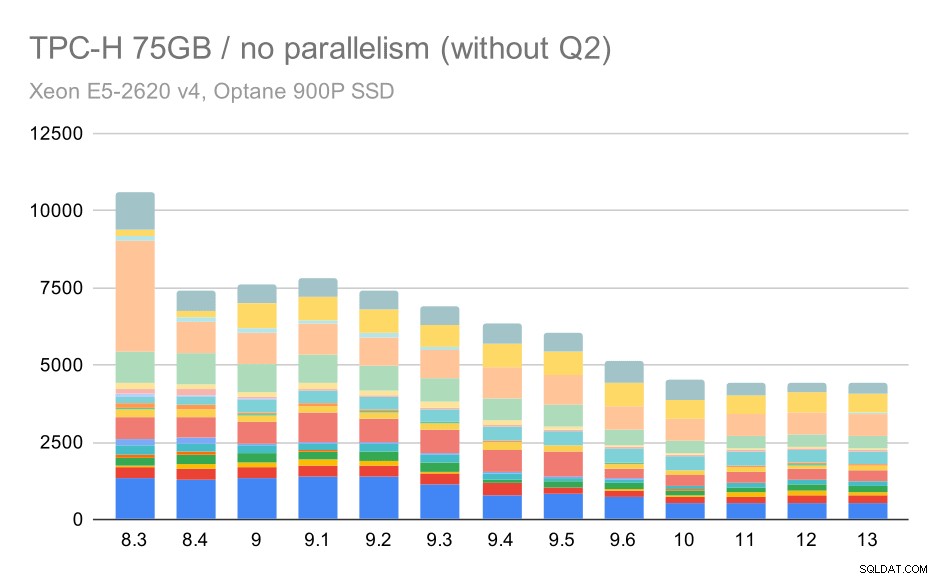
Query TPC-H su set di dati di grandi dimensioni (75 GB):parallelismo disabilitato, senza problemi nel secondo trimestre
Questo è un bel miglioramento in generale, velocizzando l'intera esecuzione da ~2,7 ore a solo ~1,2 ore, semplicemente rendendo il pianificatore e l'ottimizzatore più intelligenti e rendendo l'esecutore più efficiente (ricorda, il parallelismo è stato disabilitato in queste esecuzioni) .
Quindi, quale potrebbe essere il problema con Q2, rendendolo più lento in 9.3? La semplice risposta è che ogni volta che rendi il pianificatore e l'ottimizzatore più intelligenti, sia costruendo nuovi tipi di percorsi/piani, sia rendendolo dipendente da alcune statistiche, significa anche che possono essere commessi nuovi errori quando le statistiche o le stime sono sbagliate. Nel secondo trimestre, la clausola WHERE fa riferimento a una sottoquery aggregata:una versione semplificata della query potrebbe essere simile a questa:
select 1 from partsupp where ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AMERICA' );;
Il problema è che non conosciamo il valore medio al momento della pianificazione, rendendo impossibile calcolare stime sufficientemente buone per la condizione WHERE. L'attuale Q2 contiene join aggiuntivi e la pianificazione di quelli dipende fondamentalmente da buone stime delle relazioni unite. Nelle versioni precedenti l'ottimizzatore sembra aver fatto la cosa giusta, ma poi nella 9.3 lo abbiamo reso in qualche modo più intelligente, ma con la scarsa stima non riesce a prendere la decisione giusta. In altre parole, i buoni piani nelle versioni precedenti erano solo fortuna, grazie alle limitazioni del pianificatore.
Scommetto che anche le regressioni di Q18 e Q20 sul set di dati più piccolo sono causate da qualcosa di simile, anche se non le ho studiate in dettaglio.
Credo che alcuni di questi problemi di ottimizzazione potrebbero essere risolti ottimizzando i parametri di costo (ad es. random_page_cost ecc.) Ma non l'ho provato a causa di vincoli di tempo. Tuttavia, mostra che gli aggiornamenti non migliorano automaticamente tutte le query:a volte un aggiornamento può innescare una regressione, quindi è una buona idea eseguire un test appropriato dell'applicazione.
Parallelismo
Vediamo quindi quanto il parallelismo delle query modifica i risultati. Anche in questo caso, esamineremo solo i risultati delle versioni dalla 9.6 etichettando i risultati con "(p)" in cui è abilitata la query parallela.
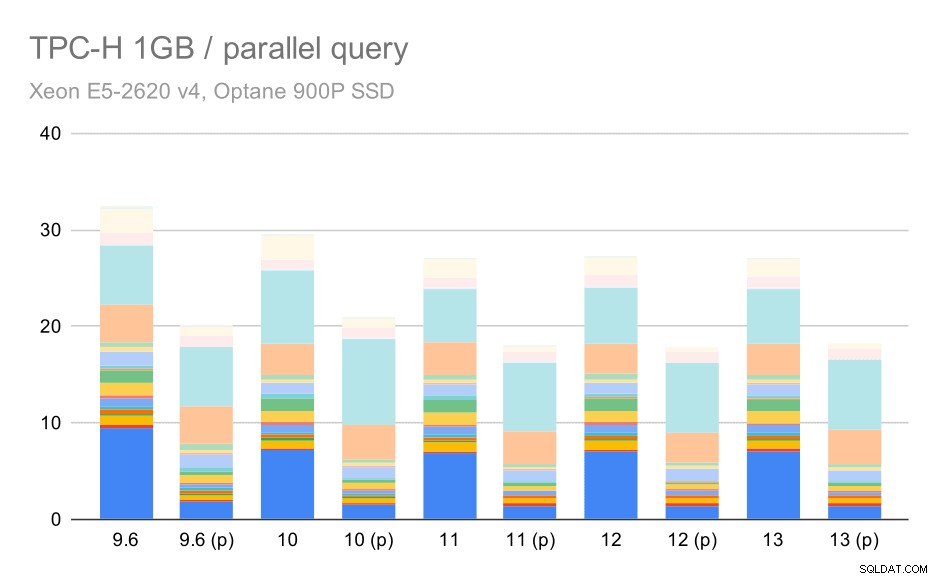
Query TPC-H su set di dati di piccole dimensioni (1 GB) – parallelismo abilitato
Chiaramente, il parallelismo aiuta parecchio:si riduce di circa il 30% anche su questo piccolo set di dati. Sul set di dati medio, non c'è molta differenza tra esecuzioni regolari e parallele:
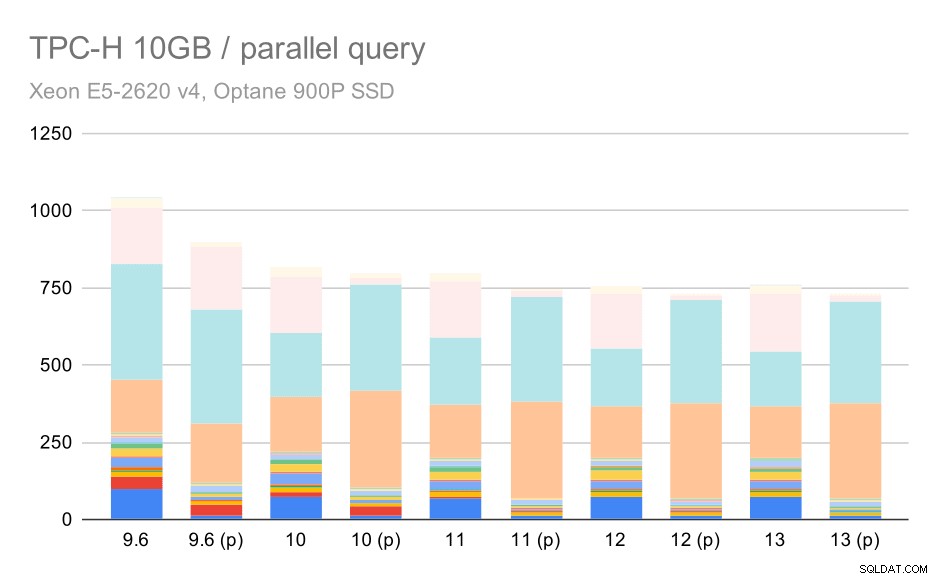
Query TPC-H su set di dati medi (10 GB) – parallelismo abilitato
Questa è un'altra dimostrazione del problema già discusso:abilitare il parallelismo consente di prendere in considerazione piani di query aggiuntivi e chiaramente le stime o i costi non corrispondono alla realtà, con conseguenti scelte di piano scadenti.
E infine l'ampio set di dati, in cui i risultati completi si presentano così:
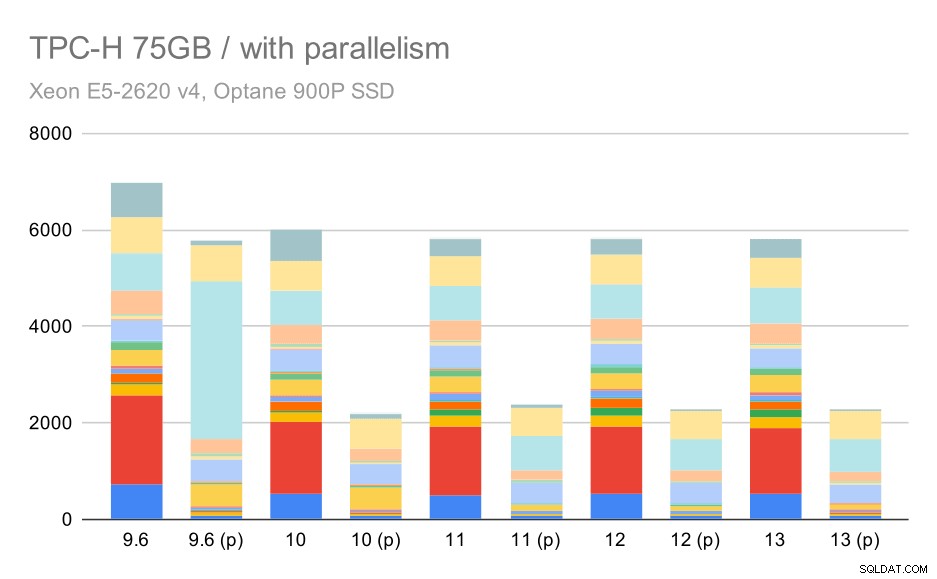
Query TPC-H su set di dati di grandi dimensioni (75 GB) – parallelismo abilitato
In questo caso, l'abilitazione del parallelismo funziona a nostro vantaggio:l'ottimizzatore riesce a costruire un piano parallelo più economico per il secondo trimestre, annullando la scelta del piano scadente introdotta in 9.3. Ma solo per completezza, ecco i risultati senza Q2.
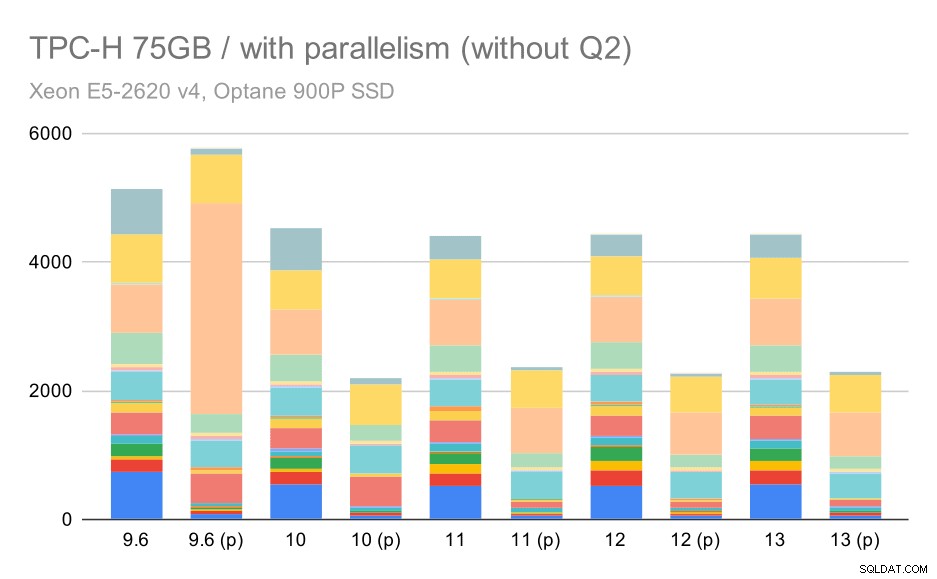
Query TPC-H su set di dati di grandi dimensioni (75 GB):parallelismo abilitato, senza problemi nel secondo trimestre
Anche qui puoi individuare alcune scelte sbagliate del piano parallelo, ad esempio il piano parallelo per Q9 è peggiore fino a 11 dove diventa più veloce, probabilmente grazie a 11 che supportano nodi esecutori paralleli aggiuntivi. D'altra parte, alcune query parallele (Q18, Q20) diventano più lente su 11, quindi non si tratta solo di arcobaleni e unicorni.
Riepilogo e futuro
Penso che questi risultati dimostrino bene le ottimizzazioni implementate da PostgreSQL 8.3. I test con il parallelismo disabilitato illustrano miglioramenti nell'efficienza (ovvero facendo di più con la stessa quantità di risorse):i carichi di dati sono diventati circa il 30% più veloci e le query sono diventate circa 2 volte più veloci. È vero che ho riscontrato alcuni problemi con piani di query inefficienti, ma questo è un rischio intrinseco quando si rende più intelligente il pianificatore di query. Lavoriamo continuamente per rendere i risultati più affidabili e sono sicuro di poter mitigare la maggior parte di questi problemi ottimizzando un po' la configurazione.
I risultati con il parallelismo abilitato mostrano che possiamo utilizzare in modo efficace risorse extra (core CPU in particolare). I carichi di dati non sembrano trarne molto vantaggio, almeno non in questo benchmark, ma l'impatto sull'esecuzione delle query è significativo, con un conseguente aumento della velocità di circa 2 volte (sebbene query diverse siano interessate in modo diverso, ovviamente).
Ci sono molte opportunità per migliorare questo nelle future versioni di PostgreSQL. Ad esempio, c'è una serie di patch che implementa il parallelismo per COPY, accelerando il caricamento dei dati. Esistono varie patch che migliorano l'esecuzione delle query analitiche, dalle piccole ottimizzazioni localizzate ai grandi progetti come l'archiviazione e l'esecuzione delle colonne, il push-down aggregato, ecc. Si può ottenere molto anche utilizzando il partizionamento dichiarativo, una funzionalità che ho per lo più ignorato mentre lavoravo su questo benchmark, semplicemente perché aumenterebbe troppo il campo di applicazione. E sono sicuro che ci sono molte altre opportunità che non riesco nemmeno a immaginare, ma le persone più intelligenti nella comunità di PostgreSQL ci stanno già lavorando.
Appendice:configurazione di PostgreSQL
Parallelismo disabilitato
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 0 max_parallel_maintenance_workers = 0 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB
Parallelismo abilitato
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 16 max_parallel_maintenance_workers = 16 max_worker_processes = 32 max_parallel_workers = 32 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB



