Benvenuti alla terza e ultima parte di questa serie di blog, che esplora l'evoluzione delle prestazioni di PostgreSQL nel corso degli anni. La prima parte ha esaminato i carichi di lavoro OLTP, rappresentati dai test pgbench. La seconda parte ha esaminato le query analitiche/BI, utilizzando un sottoinsieme del tradizionale benchmark TPC-H (essenzialmente una parte del test di potenza).
E questa parte finale esamina la ricerca full-text, ovvero la capacità di indicizzare e cercare in grandi quantità di dati di testo. La stessa infrastruttura (soprattutto gli indici) può essere utile per indicizzare dati semi-strutturati come documenti JSONB ecc. ma non è su questo che si concentra questo benchmark.
Ma prima, diamo un'occhiata alla cronologia della ricerca full-text in PostgreSQL, che può sembrare una strana funzionalità da aggiungere a un RDBMS, tradizionalmente inteso per l'archiviazione di dati strutturati in righe e colonne.
Cronologia della ricerca full-text
Quando Postgres è stato reso open source nel 1996, non aveva nulla che potessimo chiamare ricerca full-text. Ma le persone che hanno iniziato a utilizzare Postgres volevano effettuare ricerche intelligenti nei documenti di testo e le query LIKE non erano abbastanza buone. Volevano essere in grado di lemmatizzare i termini utilizzando dizionari, ignorare le parole chiave, ordinare i documenti corrispondenti per rilevanza, utilizzare indici per eseguire quelle query e molte altre cose. Cose che non puoi ragionevolmente fare con gli operatori SQL tradizionali.
Fortunatamente, alcune di queste persone erano anche sviluppatori, quindi hanno iniziato a lavorare su questo e hanno potuto, grazie al fatto che PostgreSQL è disponibile come open source in tutto il mondo. Ci sono stati molti contributori alla ricerca full-text nel corso degli anni, ma inizialmente questo sforzo è stato guidato da Oleg Bartunov e Teodor Sigaev, mostrati nella foto seguente. Entrambi sono ancora importanti contributori di PostgreSQL, lavorando su ricerca full-text, indicizzazione, supporto JSON e molte altre funzionalità.

Teodor Sigaev e Oleg Bartunov
Inizialmente, la funzionalità è stata sviluppata come un modulo "contrib" esterno (oggi diremmo che è un'estensione) chiamato "tsearch", rilasciato nel 2002. Successivamente questo è stato obsoleto da tsearch2, migliorando notevolmente la funzionalità in molti modi, e in PostgreSQL 8.3 (rilasciato nel 2008) questo era completamente integrato nel core di PostgreSQL (cioè senza la necessità di installare alcuna estensione, sebbene le estensioni fossero ancora fornite per la compatibilità con le versioni precedenti).
Da allora ci sono stati molti miglioramenti (e il lavoro continua, ad esempio per supportare tipi di dati come JSONB, eseguire query utilizzando jsonpath ecc.). ma questi plugin hanno introdotto la maggior parte delle funzionalità full-text che abbiamo ora in PostgreSQL:dizionari, funzionalità di indicizzazione e query full-text, ecc.
Il punto di riferimento
A differenza dei benchmark OLTP / TPC-H, non sono a conoscenza di alcun benchmark full-text che possa essere considerato "standard di settore" o progettato per più sistemi di database. La maggior parte dei benchmark che conosco sono pensati per essere utilizzati con un singolo database/prodotto ed è difficile portarli in modo significativo, quindi ho dovuto prendere una strada diversa e scrivere il mio benchmark full-text.
Anni fa ho scritto archie, un paio di script python che consentono il download di archivi di mailing list PostgreSQL e caricano i messaggi analizzati in un database PostgreSQL che quindi può essere indicizzato e cercato. L'istantanea corrente di tutti gli archivi ha circa 1 milione di righe e, dopo averlo caricato in un database, la tabella è di circa 9,5 GB (senza contare gli indici).
Per quanto riguarda le query, potrei probabilmente generarne alcune casuali, ma non sono sicuro di quanto sarebbe realistico. Fortunatamente, un paio di anni fa ho ottenuto un campione di 33.000 ricerche effettive dal sito Web di PostgreSQL (ovvero cose che le persone hanno effettivamente cercato negli archivi della comunità). È improbabile che io possa ottenere qualcosa di più realistico/rappresentativo.
La combinazione di queste due parti (set di dati + query) sembra un bel benchmark. Possiamo semplicemente caricare i dati ed eseguire le ricerche con diversi tipi di query full-text con diversi tipi di indici.
Query
Esistono varie forme di query full-text:la query può semplicemente selezionare tutte le righe corrispondenti, classificare i risultati (ordinarli per rilevanza), restituire solo un piccolo numero o i risultati più rilevanti, ecc. Ho eseguito benchmark con vari tipi di query, ma in questo post presenterò i risultati di due semplici query che penso rappresentino abbastanza bene il comportamento generale.
- SELECT id, oggetto DA messaggi WHERE body_tsvector @@ $1
- SELECT id, oggetto DA messaggi WHERE body_tsvector @@ $1
ORDINA PER ts_rank(body_tsvector, $1) DESC LIMIT 100
La prima query restituisce semplicemente tutte le righe corrispondenti, mentre la seconda restituisce i 100 risultati più rilevanti (questo è qualcosa che probabilmente useresti per le ricerche degli utenti).
Ho sperimentato vari altri tipi di query, ma alla fine tutti si sono comportati in modo simile a uno di questi due tipi di query.
Indici
Ogni messaggio ha due parti principali in cui possiamo cercare:oggetto e corpo. Ognuno di essi ha una colonna tsvector separata ed è indicizzato separatamente. Gli oggetti del messaggio sono molto più corti dei corpi, quindi gli indici sono naturalmente più piccoli.
PostgreSQL ha due tipi di indici utili per la ricerca full-text:GIN e GiST. Le principali differenze sono spiegate nei documenti, ma in breve:
- Gli indici GIN sono più veloci per le ricerche
- Gli indici GiST sono in perdita, ovvero richiedono un nuovo controllo durante le ricerche (e quindi sono più lenti)
Sostenevamo che gli indici GiST fossero più economici da aggiornare (soprattutto con molte sessioni simultanee), ma questo è stato rimosso dalla documentazione qualche tempo fa, a causa di miglioramenti nel codice di indicizzazione.
Questo benchmark non verifica il comportamento con gli aggiornamenti:carica semplicemente la tabella senza gli indici full-text, li crea in una volta sola e quindi esegue le 33.000 query sui dati. Ciò significa che non posso fare dichiarazioni su come questi tipi di indici gestiscono gli aggiornamenti simultanei basati su questo benchmark, ma credo che le modifiche alla documentazione riflettano vari recenti miglioramenti GIN.
Questo dovrebbe anche corrispondere abbastanza bene al caso d'uso dell'archivio della mailing list, in cui aggiungeremmo nuove e-mail solo una volta ogni tanto (pochi aggiornamenti, quasi nessuna simultaneità di scrittura). Ma se la tua applicazione esegue molti aggiornamenti simultanei, dovrai eseguirne il benchmark da solo.
L'hardware
Ho eseguito il benchmark sulle stesse due macchine di prima, ma i risultati/conclusioni sono quasi identici, quindi presenterò solo i numeri di quello più piccolo, ad es.
- CPU i5-2500K (4 core/thread)
- 8 GB di RAM
- 6 SSD RAID0 da 100 GB
- kernel 5.6.15, filesystem ext4
In precedenza ho menzionato che il set di dati ha quasi 10 GB quando caricato, quindi è più grande della RAM. Ma gli indici sono ancora più piccoli della RAM, che è ciò che conta per il benchmark.
Risultati
OK, ora per alcuni numeri e grafici. Presenterò i risultati sia per il caricamento dei dati che per le query, prima con GIN e poi con gli indici GiST.
GIN / caricamento dati
Il carico non è particolarmente interessante, credo. In primo luogo, la maggior parte di esso (la parte blu) non ha nulla a che fare con il full-text, perché accade prima che i due indici vengano creati. La maggior parte di questo tempo viene speso per analizzare i messaggi, ricostruire i thread di posta, mantenere l'elenco delle risposte e così via. Parte di questo codice è implementato nei trigger PL/pgSQL, parte è implementato all'esterno del database. L'unica parte potenzialmente rilevante per il full-text è la creazione di tsvector, ma è impossibile isolare il tempo speso per questo.
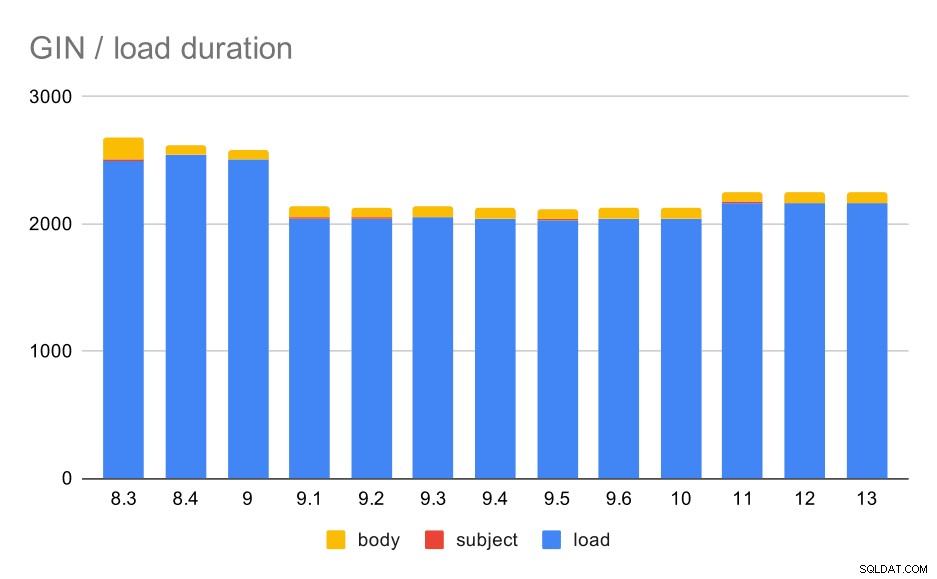
Operazioni di caricamento dati con una tabella e indici GIN.
La tabella seguente mostra i dati di origine per questo grafico:i valori sono la durata in secondi. LOAD include l'analisi degli archivi mbox (da uno script Python), l'inserimento in una tabella e varie attività aggiuntive (ricostruzione di thread di posta elettronica, ecc.). L'INDICE SUBJECT/BODY si riferisce alla creazione di un indice GIN full-text sulle colonne soggetto/corpo dopo il caricamento dei dati.
| LOAD | INDICE SOGGETTO | INDICE DEL CORPO | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Chiaramente, la performance è abbastanza stabile:c'è stato un miglioramento abbastanza significativo (circa il 20%) tra 9,0 e 9,1. Non sono sicuro di quale modifica potrebbe essere responsabile di questo miglioramento:nulla nelle note di rilascio 9.1 sembra chiaramente rilevante. C'è anche un chiaro miglioramento nella costruzione degli indici GIN in 8.4, che dimezza i tempi. Il che è bello, ovviamente. Abbastanza interessante, non vedo nessun elemento delle note di rilascio ovviamente correlato per questo.
Che dire delle dimensioni degli indici GIN, però? C'è molta più variabilità, almeno fino alla 9.4, a quel punto la dimensione degli indici scende da circa 1 GB a solo circa 670 MB (circa il 30%).
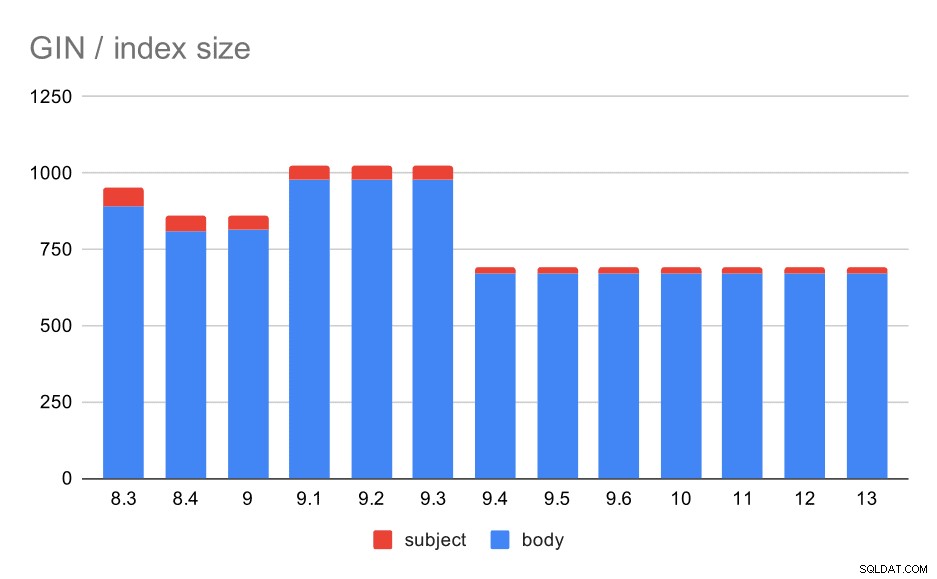
Dimensione degli indici GIN sull'oggetto/corpo del messaggio. I valori sono megabyte.
La tabella seguente mostra le dimensioni degli indici GIN sul corpo del messaggio e sull'oggetto. I valori sono in megabyte.
| BODY | SOGGETTO | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
In questo caso, penso che possiamo tranquillamente presumere che questo aumento di velocità sia correlato a questo elemento nelle note di rilascio 9.4:
- Riduci la dimensione dell'indice GIN (Alexander Korotkov, Heikki Linnakangas)
La variabilità dimensionale tra 8.3 e 9.1 sembra essere dovuta a cambiamenti nella lemmatizzazione (come le parole vengono trasformate nella forma "base"). A parte le differenze di dimensione, le query su queste versioni restituiscono numeri di risultati leggermente diversi, ad esempio.
GIN / query
Ora, la parte principale di questo benchmark:le prestazioni delle query. Tutti i numeri presentati qui sono per un singolo client:abbiamo già discusso della scalabilità del client nella parte relativa alle prestazioni OLTP, i risultati si applicano anche a queste query. (Inoltre, questa particolare macchina ha solo 4 core, quindi non andremmo comunque molto lontano in termini di test di scalabilità.)
SELECT id, oggetto DA messaggi WHERE tsvector @@ $1
Innanzitutto, la query che cerca tutti i documenti corrispondenti. Per le ricerche nella colonna "oggetto" possiamo fare circa 800 query al secondo (e in realtà scende un po' in 9.1), ma in 9.4 spara improvvisamente fino a 3000 query al secondo. Per la colonna "corpo" è fondamentalmente la stessa storia:inizialmente 160 query, un calo a circa 90 query in 9.1 e poi un aumento a 300 in 9.4.
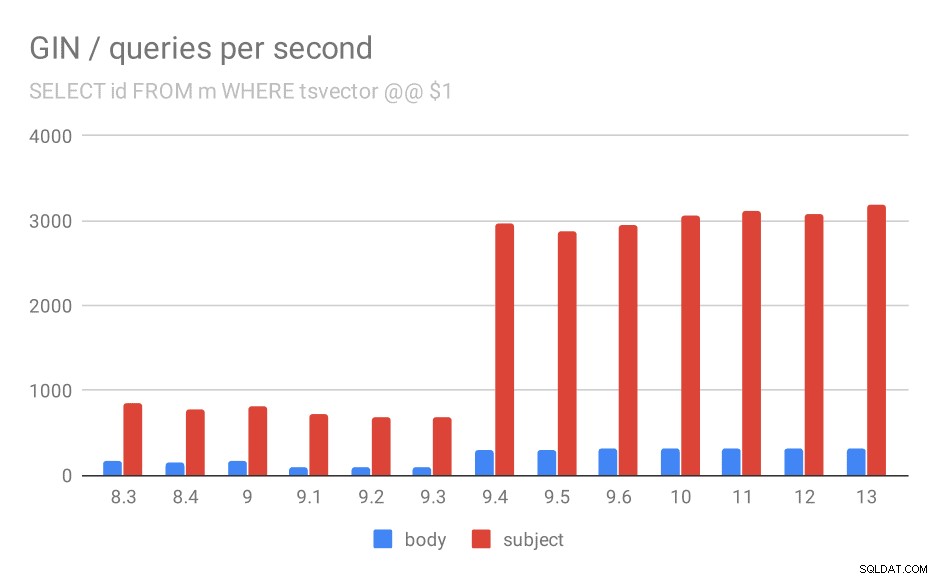
Numero di query al secondo per la prima query (recupero di tutte le righe corrispondenti).
E ancora, i dati di origine:i numeri sono il throughput (query al secondo).
| BODY | SOGGETTO | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Penso che possiamo tranquillamente presumere che il miglioramento in 9.4 sia correlato a questo elemento nelle note di rilascio:
- Migliora la velocità delle ricerche GIN multi-chiave (Alexander Korotkov, Heikki Linnakangas)
Quindi, un altro miglioramento 9.4 in GIN dagli stessi due sviluppatori:chiaramente, Alexander e Heikki hanno fatto un ottimo lavoro sugli indici GIN nella versione 9.4 😉
SELECT id, oggetto DA messaggi WHERE tsvector @@ $1
ORDINA PER ts_rank(tsvector, $2) DESC LIMIT 100
Per la query che classifica i risultati in base alla pertinenza utilizzando ts_rank e LIMIT, il comportamento generale è quasi esattamente lo stesso, non c'è bisogno di descrivere il grafico in dettaglio, credo.
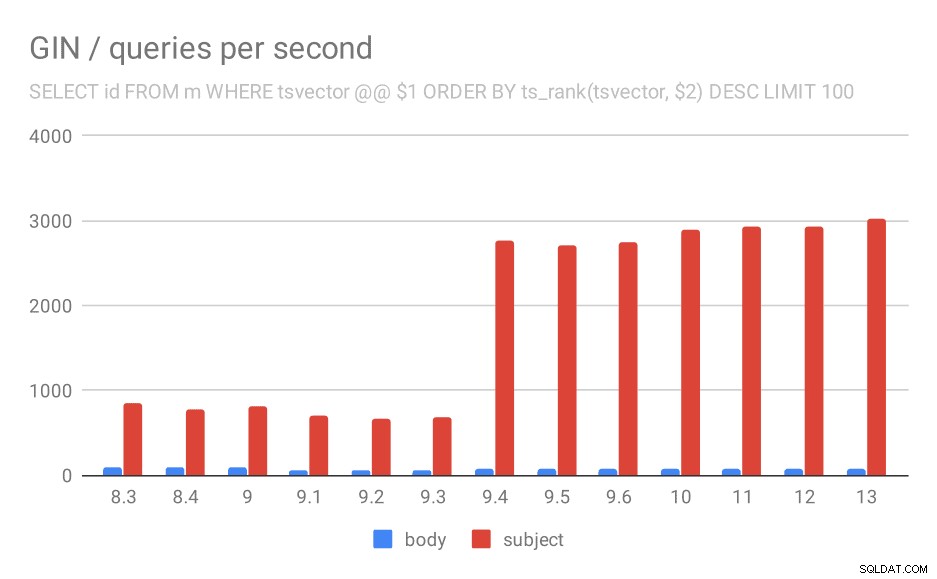
Numero di query al secondo per la seconda query (recupero delle righe più rilevanti).
| BODY | SOGGETTO | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
C'è una domanda, però:perché le prestazioni sono scese tra 9.0 e 9.1? Sembra esserci un calo piuttosto significativo del throughput, di circa il 50% per le ricerche nel corpo e del 20% per le ricerche negli oggetti dei messaggi. Non ho una spiegazione chiara di cosa sia successo, ma ho due osservazioni…
In primo luogo, la dimensione dell'indice è cambiata:se guardi il primo grafico "GIN / index size" e la tabella, vedrai che l'indice sui corpi dei messaggi è cresciuto da 813 MB a circa 977 MB. Si tratta di un aumento significativo e potrebbe spiegare parte del rallentamento. Il problema però è che l'indice sugli argomenti non è cresciuto affatto, ma anche le query sono diventate più lente.
In secondo luogo, possiamo guardare quanti risultati hanno restituito le query. Il set di dati indicizzato è esattamente lo stesso, quindi sembra ragionevole aspettarsi lo stesso numero di risultati in tutte le versioni di PostgreSQL, giusto? Bene, in pratica si presenta così:
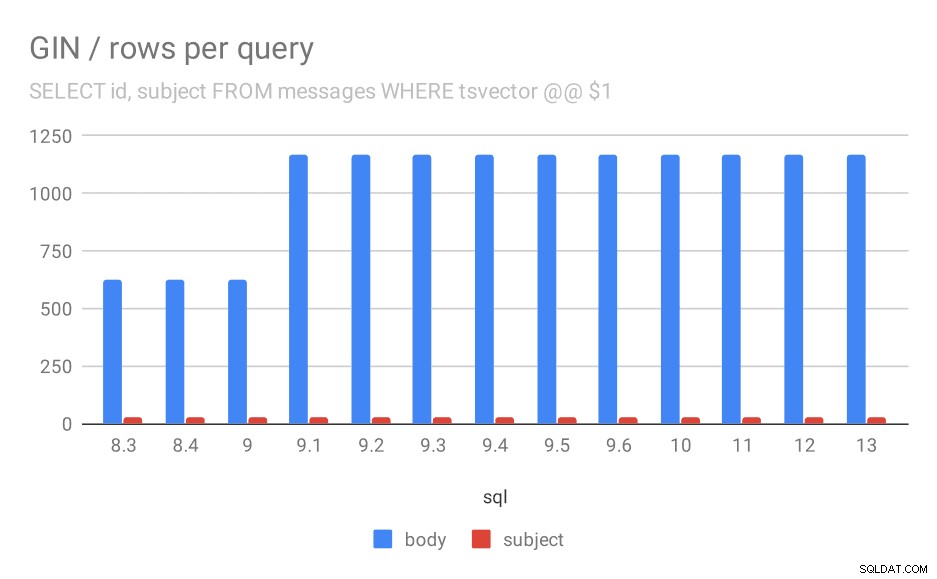
Numero medio di righe restituite per una query.
| BODY | SOGGETTO | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Chiaramente, in 9.1 il numero medio di risultati per le ricerche nei corpi dei messaggi raddoppia improvvisamente, il che è quasi perfettamente proporzionale al rallentamento. Tuttavia il numero di risultati per le ricerche per argomento rimane lo stesso. Non ho una buona spiegazione per questo, tranne per il fatto che l'indicizzazione è cambiata in un modo che consente di abbinare più messaggi, ma rendendolo un po' più lento. Se hai spiegazioni migliori, mi piacerebbe sentirle!
GiST / caricamento dati
Ora, l'altro tipo di indici full-text:GiST. Questi indici sono con perdita, ovvero richiedono un nuovo controllo dei risultati utilizzando i valori della tabella. Quindi possiamo aspettarci un throughput inferiore rispetto agli indici GIN, ma per il resto è ragionevole aspettarsi più o meno lo stesso schema.
I tempi di caricamento corrispondono in effetti al GIN quasi perfettamente:i tempi di creazione dell'indice sono diversi, ma lo schema generale è lo stesso. Accelerazione in 9.1, piccolo rallentamento in 11.
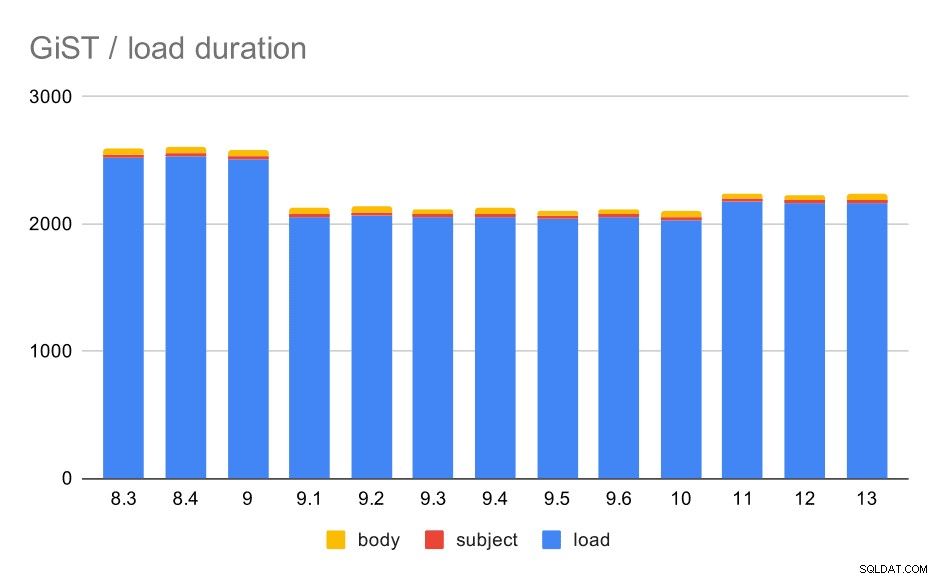
Operazioni di caricamento dati con una tabella e indici GiST.
| LOAD | SOGGETTO | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
La dimensione dell'indice, tuttavia, è rimasta quasi costante:non ci sono stati miglioramenti GiST simili a GIN in 9.4, il che ha ridotto la dimensione di circa il 30%. C'è un aumento in 9.1, che è un altro segno che l'indicizzazione full-text è cambiata in quella versione per indicizzare più parole.
Ciò è ulteriormente supportato dal numero medio di risultati con GiST esattamente lo stesso di GIN (con un aumento di 9.1).
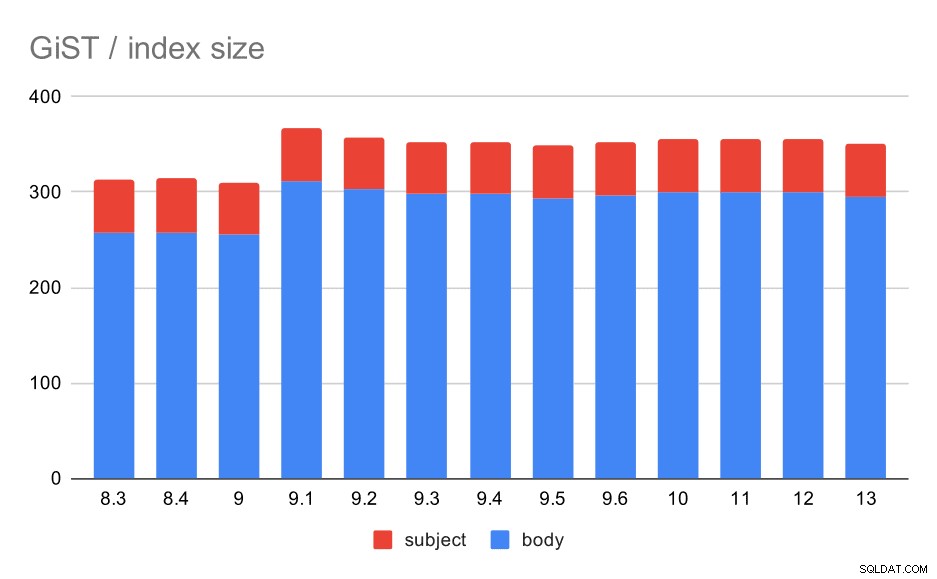
Dimensione degli indici GiST sull'oggetto/corpo del messaggio. I valori sono megabyte.
| BODY | SOGGETTO | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
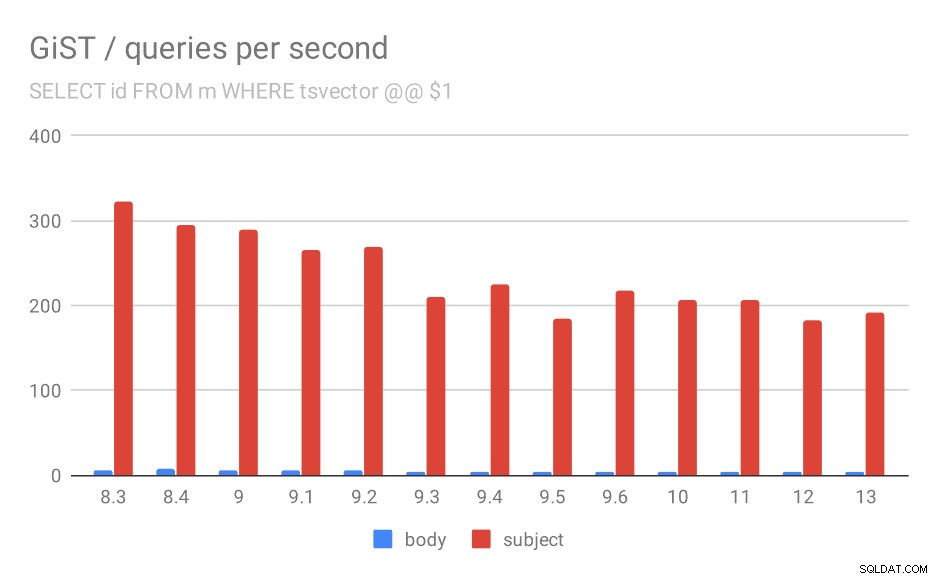
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
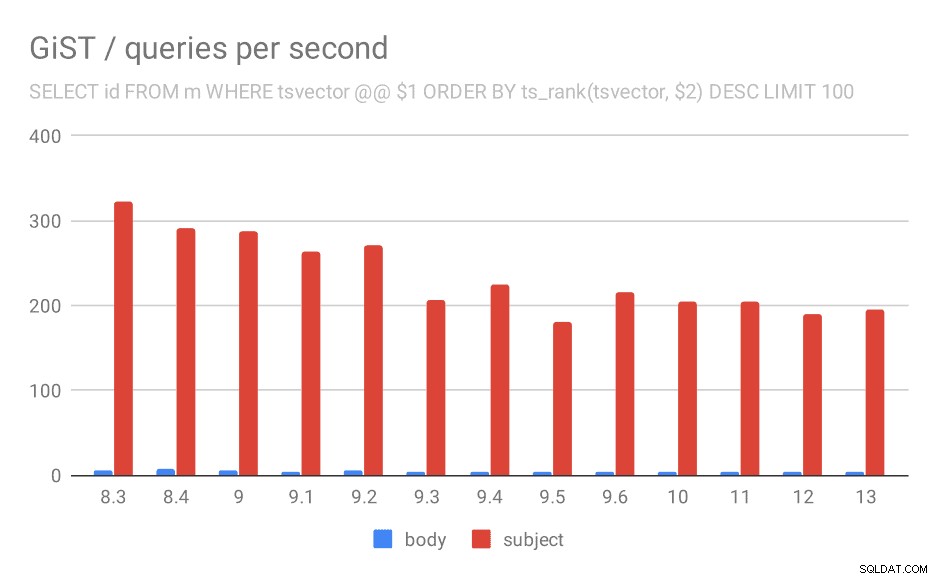
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).