Un po' di cura e pulizia della distribuzione di PostgreSQL contribuisce notevolmente a garantire le prestazioni, evitare scoperte spiacevoli e stabilire una prevedibilità sicura. Ecco 7 cose da tenere d'occhio.
Bloat da tavolo
PostgreSQL implementa le transazioni utilizzando una tecnica chiamata MVCC. MVCC è troppo lungo e implica un argomento per essere discusso in dettaglio, ma ce ne sono tre cose che devi conoscerlo:
- L'eliminazione di una riga la contrassegna solo come "invisibile" per le transazioni future.
- L'aggiornamento di una riga crea una nuova versione della riga. La vecchia versione è contrassegnata come invisibile alle transazioni future e la nuova versione è contrassegnata come visibile.
- Periodicamente, qualcuno deve guardare tutte le transazioni attualmente in esecuzione e dire:OK, la transazione più vecchia qui è la n. 42, quindi ogni versione di riga invisibile alla n. 42 può essere eliminata fisicamente senza compromettere la coerenza dei dati.
È così che funziona MVCC (essenzialmente) e l'implicazione è che gli aggiornamenti saranno aumentare il footprint di archiviazione del database fisico e le eliminazioni non riduci. MVCC suona come un modo pigro di fare le cose, ma è popolare perché fornisce sia coerenza che prestazioni.
Le versioni di riga indesiderate e obsolete in una tabella sono chiamate bloat (o deadrows ). Il processo che può eliminare il rigonfiamento è chiamato vuoto . PostgreSQL ha un processo di vuoto attivato automaticamente con soglie regolabili chiamato autovacuum e, naturalmente, il comando VACUUM.
In generale, bloat può anche rallentare le query a causa di mappe di visibilità imprecise e I/O del disco sprecato.
Per questo motivo, dovresti regolarmente:
- monitora la quantità di rigonfiamento in un database
- funziona regolarmente con l'aspirapolvere
- controlla se il vuoto viene eseguito regolarmente per tutte le tabelle
Sono disponibili alcune query SQL per fornire stime di bloat per tabella. Il toolpgmetrics open source fornisce stime gonfiate e ultimi tempi di esecuzione del vuoto manuale e automatico.
Rigonfiamento dell'indice
Anche gli indici possono gonfiarsi. Sebbene la struttura interna degli indici sia opaca all'utente SQL e vari in base al tipo di indice (BTree, hash, GIN, GIST, ecc.), l'idea generale rimane che quando le righe a cui fa riferimento l'indice vengono eliminate, lo spazio occupato dalle relative informazioni all'interno dell'indice viene solo cancellato logicamente e non rilasciato nel filesystem. Lo spazio cancellato logicamente può essere riutilizzato dall'indice in seguito.
Esistono due modi per convincere Postgres a ridurre le dimensioni fisiche di un indice:
- la versione COMPLETA del comando VACUUM
- REINDICE
Il rigonfiamento dell'indice deve essere monitorato, in modo da essere almeno consapevole della quantità di spazio rimanente inutilizzato. Nelle tabelle con elevato abbandono delle righe non è raro impostare normali processi di ricostruzione dell'indice.
Index bloat può anche essere ottenuto con le stesse query di prima e anche tramite pgmetrics.
Transazioni di lunga durata
Le transazioni dovrebbero essere quanto più brevi possibile, specialmente in un sistema MVCC.
Immagina che una transazione sia iniziata ieri e che ci sia stato un vuoto subito dopo. Ora, finché questa transazione è aperta, ulteriori vuoti sono inutili, poiché per definizione la nostra transazione dovrà vedere tutte le righe di tutte le tabelle come erano quando la nostra transazione è iniziata ieri. Anche se la nostra transazione è di sola lettura, è ancora così.
Di conseguenza, le transazioni di lunga durata creano rigonfiamenti. Si aggrappano anche alle risorse di sistema, mantengono i blocchi non ceduti e aumentano le possibilità di deadlock.
Il modo migliore per tenere d'occhio le transazioni di lunga durata è impostare un avviso per il numero di transazioni in esecuzione da più di una certa durata. Puoi ottenerlo dalla visualizzazione delle statistichepg_stat_activity , in questo modo:
-- number of transactions that have been open for
-- more than 1 hour
SELECT count(*) FROM pg_stat_activity WHERE xact_start < now()-'1 hour'::interval;Ritardo di replica
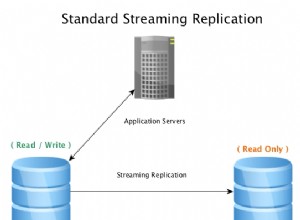
Quando la replica in streaming viene utilizzata per replicare tutte le modifiche da un server PostgreSQL primario a un hot standby (noto anche come replica di lettura), di solito c'è un leggero ritardo tra il momento in cui si verificano gli aggiornamenti di riga sul server primario e quando le modifiche sono visibili alle applicazioni connesse allo standby .
Ci sono tuttavia casi in cui questo ritardo può aumentare:
- il sistema di standby non è in grado di ricevere e applicare le modifiche dal sistema primario abbastanza velocemente da tenersi al passo, di solito a causa di un carico elevato o di un provisioning insufficiente
- una rete o un disco danneggiato
- conflitti di query
Uno standby con un ritardo di replica elevato o addirittura peggiore, in aumento, può comportare query sullo standby che restituiscono dati obsoleti e uno standby non idoneo al failover.
Se disponi di una configurazione di replica in streaming, il monitoraggio dei ritardi di replica tra ciascuna coppia primaria-standby è molto importante e ti consigliamo di impostare avvisi per verificare se i ritardi di replica superano un minuto o qualsiasi soglia abbia senso per la tua configurazione.
Questo post contiene molto di più su come misurare e monitorare il ritardo di replica sia dall'estremità primaria che da quella di standby.
Slot di replica inattivi
L'uso degli slot di replica, introdotto in PostgreSQL 9.4, rende la replica in streaming più robusta ed efficiente. In sostanza, lo standby segnala l'avanzamento della replica al primario, che memorizza queste informazioni nello "slot di replica".
Per questo motivo, il primario ora sa in ogni momento quanto è indietro rispetto allo standby. Ciò consente al primario di conservare un backlog sufficiente di file WAL (necessari per riprendere la replica) quando lo standby va offline. Così quando torna lo standby, anche dopo molto tempo, il primario può comunque garantire che la replica possa essere ripresa.
Prima degli slot di replica, il primario potrebbe ripulire i vecchi file WAL, poiché non aveva modo di sapere se gli standby ne avevano bisogno o meno. Se viene eliminato un file WAL necessario per asstandby, non è possibile riprendere la replica; deve essere riconfigurato da zero.
Tuttavia, il comportamento del primario di conservare i file WAL a tempo indeterminato porta a un altro problema. Se uno standby è stato ritirato e lo slot di replica associato non è stato eliminato, i file WAL verranno conservati per sempre. I file WAL conservati per questo motivo non sono soggetti ai limiti stabiliti da max_wal_size e altre opzioni di configurazione.
Questa situazione persisterà fino a quando i file WAL non esauriranno l'intero spazio su disco, senza nemmeno un avviso nei file di registro di PostgreSQL.
Inutile dire che gli slot di replica inattivi devono essere gestiti quando vengono rilevati. Trova i tuoi slot di replica inattivi utilizzando:
SELECT slot_name FROM pg_replication_slots WHERE NOT active;Analizza lo stato
ANALYZE viene eseguito sulle tabelle per raccogliere e aggiornare le informazioni statistiche sul contenuto della tabella. Queste informazioni vengono utilizzate dal pianificatore di query per preparare il piano di esecuzione per ogni query SQL. Statistiche aggiornate sui contenuti della tabella si traducono in un piano di esecuzione migliore, che a sua volta si traduce in una query più rapida.
Il demone autovacuum di solito esegue ANALYZE dopo VACUUM. Tuttavia, ciò potrebbe non essere abbastanza frequente per ANALIZZARE. Se la distribuzione dei dati in una tabella cambia spesso, dovresti eseguire ANALYZE più frequentemente.
In genere ANALYZE si comporta abbastanza bene:necessita solo di blocchi di lettura, non consuma troppe risorse e si completa in tempi ragionevoli. È sicuro evitare di eseguirlo il più delle volte.
Tenere d'occhio i tavoli che non vengono ANALIZZATI da un po' è una buona idea. Scopri l'ultima volta che le tue tabelle sono state (auto)analizzate con la query:
SELECT schemaname || '.' || relname, last_analyze, last_autoanalyze
FROM pg_stat_user_tables;Utilizzo delle risorse
Il monitoraggio del carico della CPU, della memoria e dell'utilizzo del disco contribuisce notevolmente a garantire una capacità sufficiente per soddisfare le crescenti esigenze delle applicazioni che utilizzano il database.
PostgreSQL genera un processo per gestire una connessione. Anche se questa potrebbe non essere l'architettura più scalabile al giorno d'oggi, contribuisce molto sul fronte della stabilità. Inoltre, rende più significativa la media del carico del sistema operativo. Poiché di solito PostgreSQLbox esegue solo PostgreSQL, una media di carico di 3 significa in genere che ci sono 3 connessioni in attesa che i core della CPU diventino disponibili per poter essere programmati. Il monitoraggio della media del carico massimo durante un giorno o una settimana tipo può fornire una stima di quanto il tuo box sia sovraccarico o insufficiente sul fronte della CPU.
La memoria e lo spazio libero su disco sono ovviamente cose standard da monitorare. Più connessioni e transazioni più lunghe richiedono una maggiore quantità di memoria. E durante il monitoraggio dello spazio libero su disco, ricorda di tenerne traccia per tablespace.