Anche se esistono vari modi per ripristinare il database PostgreSQL, uno degli approcci più convenienti per ripristinare i dati da un backup logico. I backup logici svolgono un ruolo significativo per Disaster and Recovery Planning (DRP). I backup logici sono backup eseguiti, ad esempio utilizzando pg_dump o pg_dumpall, che generano istruzioni SQL per ottenere tutti i dati della tabella scritti in un file binario.
Si consiglia inoltre di eseguire backup logici periodici nel caso in cui i backup fisici abbiano esito negativo o non siano disponibili. Per PostgreSQL, il ripristino può essere problematico se non sei sicuro di quali strumenti utilizzare. Lo strumento di backup pg_dump è comunemente associato allo strumento di ripristino pg_restore.
pg_dump e pg_restore agiscono in tandem se si verifica un'emergenza ed è necessario ripristinare i dati. Sebbene servano allo scopo principale del dump e del ripristino, richiedono l'esecuzione di alcune attività aggiuntive quando è necessario ripristinare il cluster ed eseguire un failover (se il principale o il master attivo muore a causa di un guasto hardware o del danneggiamento del sistema VM). Finirai per trovare e utilizzare strumenti di terze parti in grado di gestire il failover o il ripristino automatico del cluster.
In questo blog, daremo un'occhiata a come funziona pg_restore e lo confronteremo con il modo in cui ClusterControl gestisce il backup e il ripristino dei tuoi dati in caso di disastro.
Meccanismi di pg_restore
pg_restore è utile quando si ottengono le seguenti attività:
- accoppiato con pg_dump per la generazione di file generati da SQL contenenti dati, ruoli di accesso, database e definizioni di tabelle
- ripristina un database PostgreSQL da un archivio creato da pg_dump in uno dei formati non di testo normale.
- Emetterà i comandi necessari per ricostruire il database allo stato in cui si trovava al momento del salvataggio.
- ha la capacità di essere selettivo o addirittura di riordinare gli elementi prima che vengano ripristinati in base al file di archivio
- I file di archivio sono progettati per essere portabili tra architetture.
- pg_restore può operare in due modalità.
- Se viene specificato un nome di database, pg_restore si connette a quel database e ripristina il contenuto dell'archivio direttamente nel database.
- oppure uno script contenente i comandi SQL necessari per ricostruire il database viene creato e scritto in un file o in un output standard. Il suo output di script è equivalente al formato generato da pg_dump
- Alcune delle opzioni che controllano l'uscita sono quindi analoghe alle opzioni pg_dump.
Una volta ripristinati i dati, è meglio e consigliabile eseguire ANALYZE su ogni tabella ripristinata in modo che l'ottimizzatore abbia statistiche utili. Sebbene acquisisca READ LOCK, potrebbe essere necessario eseguirlo durante un traffico ridotto o durante il periodo di manutenzione.
Vantaggi di pg_restore
pg_dump e pg_restore in tandem hanno funzionalità che sono convenienti da utilizzare per un DBA.
- pg_dump e pg_restore hanno la capacità di essere eseguiti in parallelo specificando l'opzione -j. L'uso di -j/--jobs
consente di specificare quanti lavori in esecuzione in parallelo possono essere eseguiti soprattutto per caricare dati, creare indici o creare vincoli utilizzando più lavori simultanei. - È comodo da usare, puoi scaricare o caricare selettivamente database o tabelle specifici
- Consente e fornisce all'utente una flessibilità su quale particolare database, schema o riordinare le procedure da eseguire in base all'elenco. Puoi persino generare e caricare la sequenza di SQL in modo approssimativo come prevenire acls o privilegiare in base alle tue esigenze. Ci sono molte opzioni per soddisfare le tue esigenze.
- Ti offre la possibilità di generare file SQL proprio come pg_dump da un archivio. Questo è molto comodo se desideri caricare su un altro database o host per eseguire il provisioning di un ambiente separato.
- È facile da capire in base alla sequenza generata di procedure SQL.
- È un modo conveniente per caricare i dati in un ambiente di replica. Non è necessario che la replica venga ristabilita poiché le istruzioni sono SQL che sono state replicate fino ai nodi di standby e ripristino.
Limitazioni di pg_restore
Per i backup logici, le ovvie limitazioni di pg_restore insieme a pg_dump sono le prestazioni e la velocità nell'utilizzo degli strumenti. Potrebbe essere utile quando si desidera eseguire il provisioning di un ambiente di database di test o sviluppo e caricare i dati, ma non è applicabile quando il set di dati è enorme. PostgreSQL deve scaricare i tuoi dati uno per uno o eseguire e applicare i tuoi dati in sequenza dal motore di database. Sebbene tu possa renderlo liberamente flessibile per accelerare come specificando -j o usando --single-transaction per evitare l'impatto sul tuo database, il caricamento tramite SQL deve comunque essere analizzato dal motore.
Inoltre, la documentazione di PostgreSQL afferma le seguenti limitazioni, con le nostre aggiunte mentre osservavamo questi strumenti (pg_dump e pg_restore):
- Quando si ripristinano i dati in una tabella preesistente e viene utilizzata l'opzione --disable-triggers, pg_restore emette comandi per disabilitare i trigger sulle tabelle utente prima di inserire i dati, quindi emette comandi per riattivarli dopo che i dati sono stati inseriti. Se il ripristino viene interrotto nel mezzo, i cataloghi di sistema potrebbero essere lasciati nello stato errato.
- pg_restore non può ripristinare oggetti di grandi dimensioni in modo selettivo; per esempio, solo quelli per una tabella specifica. Se un archivio contiene oggetti di grandi dimensioni, verranno ripristinati tutti gli oggetti di grandi dimensioni o nessuno di essi se sono esclusi tramite -L, -t o altre opzioni.
- Ci si aspetta che entrambi gli strumenti generino un'enorme quantità di dimensioni (file, directory o archivio tar) specialmente per un database enorme.
- Per pg_dump, quando si esegue il dump di una singola tabella o come testo normale, pg_dump non gestisce oggetti di grandi dimensioni. Gli oggetti di grandi dimensioni devono essere scaricati con l'intero database utilizzando uno dei formati di archivio non di testo.
- Se hai archivi tar generati da questi strumenti, tieni presente che gli archivi tar sono limitati a una dimensione inferiore a 8 GB. Questa è una limitazione intrinseca del formato del file tar. Pertanto questo formato non può essere utilizzato se la rappresentazione testuale di una tabella supera tale dimensione. La dimensione totale di un archivio tar e di qualsiasi altro formato di output non è limitata, salvo possibilmente dal sistema operativo.
Utilizzo di pg_restore
L'uso di pg_restore è abbastanza comodo e facile da usare. Dal momento che è accoppiato in tandem con pg_dump, entrambi questi strumenti funzionano sufficientemente bene fintanto che l'output di destinazione si adatta all'altro. Ad esempio, il seguente pg_dump non sarà utile per pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Questo risultato sarà compatibile con psql che si presenta come segue:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Ma questo fallirà per pg_restore poiché non esiste un formato semplice da seguire:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerOra, andiamo a termini più utili per pg_restore.
pg_restore:rilascia e ripristina
Considera un semplice utilizzo di pg_restore che hai, elimina un database, ad es.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Ripristinarlo con pg_restore è molto semplice,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump Il -C/--create qui afferma che crea il database una volta incontrato nell'intestazione. -d postgres punta al database postgres ma non significa che creerà le tabelle nel database postgres. Richiede che il database debba esistere. Se -C non è specificato, le tabelle e i record verranno archiviati nel database a cui si fa riferimento con l'argomento -d.
Ripristino selettivo per tabella
Ripristinare una tabella con pg_restore è facile e semplice. Ad esempio, hai due tabelle, ovvero le tabelle "b" e "d". Supponiamo che tu esegua il seguente comando pg_dump di seguito,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Dove il contenuto di questa directory apparirà come segue,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Se vuoi ripristinare una tabella (ovvero "d" in questo esempio),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Dovrò,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:copia delle tabelle del database in un database diverso
Puoi anche copiare il contenuto del tuo database esistente e averlo nel tuo database di destinazione. Ad esempio, ho i seguenti database,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Il database paultest è un database vuoto mentre copieremo ciò che è all'interno del database maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Per copiarlo, dobbiamo scaricare i dati dal database maxtest come segue,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Quindi caricalo o ripristinalo come segue,
Ora abbiamo i dati sul database paultest e le tabelle sono state archiviate di conseguenza.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Genera un file SQL con il riordino
Ho visto molto utilizzo con pg_restore ma sembra che questa funzione di solito non sia mostrata. Ho trovato questo approccio molto interessante in quanto ti consente di ordinare in base a ciò che non desideri includere e quindi di generare un file SQL dall'ordine in cui desideri procedere.
Ad esempio, useremo l'esempio pgdump_data.tar che abbiamo generato in precedenza e creeremo un elenco. Per fare ciò, esegui il seguente comando:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listQuesto genererà un file come mostrato di seguito:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresOra riordiniamolo o diciamo che ho rimosso la creazione di SEQUENCE e anche la creazione del vincolo. Questo sarebbe simile al seguente,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresPer generare il file in formato SQL, procedi come segue:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Ora, il file /tmp/selective_data.out sarà un file generato da SQL e questo è leggibile se usi psql, ma non pg_restore. La cosa fantastica di questo è che puoi generare un file SQL in base al tuo modello su cui solo i dati possono essere ripristinati da un archivio esistente o eseguito un backup utilizzando pg_dump con l'aiuto di pg_restore.
Ripristino PostgreSQL con ClusterControl
ClusterControl non utilizza pg_restore o pg_dump come parte del suo set di funzionalità. Usiamo pg_dumpall per generare backup logici e, sfortunatamente, l'output non è compatibile con pg_restore.
Ci sono molti altri modi per generare un backup in PostgreSQL, come mostrato di seguito.
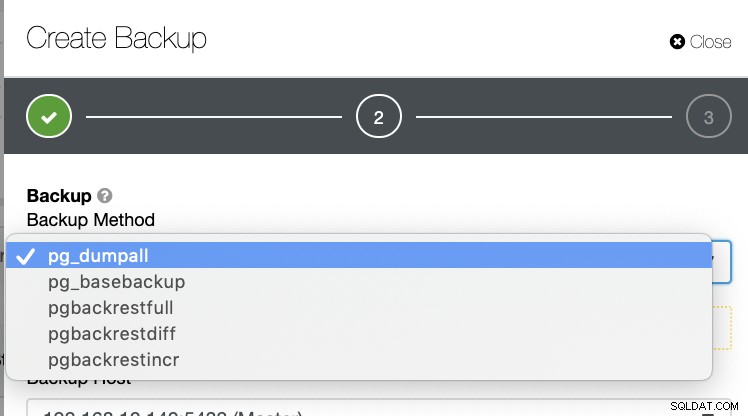
Non esiste un meccanismo del genere in cui è possibile memorizzare selettivamente una tabella, un database, o copia da un database a un altro database.
ClusterControl supporta il Point-in-Time Recovery (PITR), ma ciò non consente di gestire il ripristino dei dati in modo flessibile come con pg_restore. Per tutto l'elenco dei metodi di backup, solo pg_basebackup e pgbackrest sono compatibili con PITR.
Il modo in cui ClusterControl gestisce il ripristino è che ha la capacità di ripristinare un cluster guasto fintanto che il ripristino automatico è abilitato come mostrato di seguito.

Una volta che il master si guasta, lo slave può ripristinare automaticamente il cluster mentre ClusterControl esegue il failover (che viene eseguito automaticamente). Per la parte di ripristino dei dati, l'unica opzione è avere un ripristino a livello di cluster, il che significa che proviene da un backup completo. Non è possibile eseguire il ripristino selettivo sul database o sulla tabella di destinazione che si desiderava solo ripristinare. Se vuoi farlo, ripristina il backup completo, è facile farlo con ClusterControl. Puoi andare alle schede Backup proprio come mostrato di seguito,
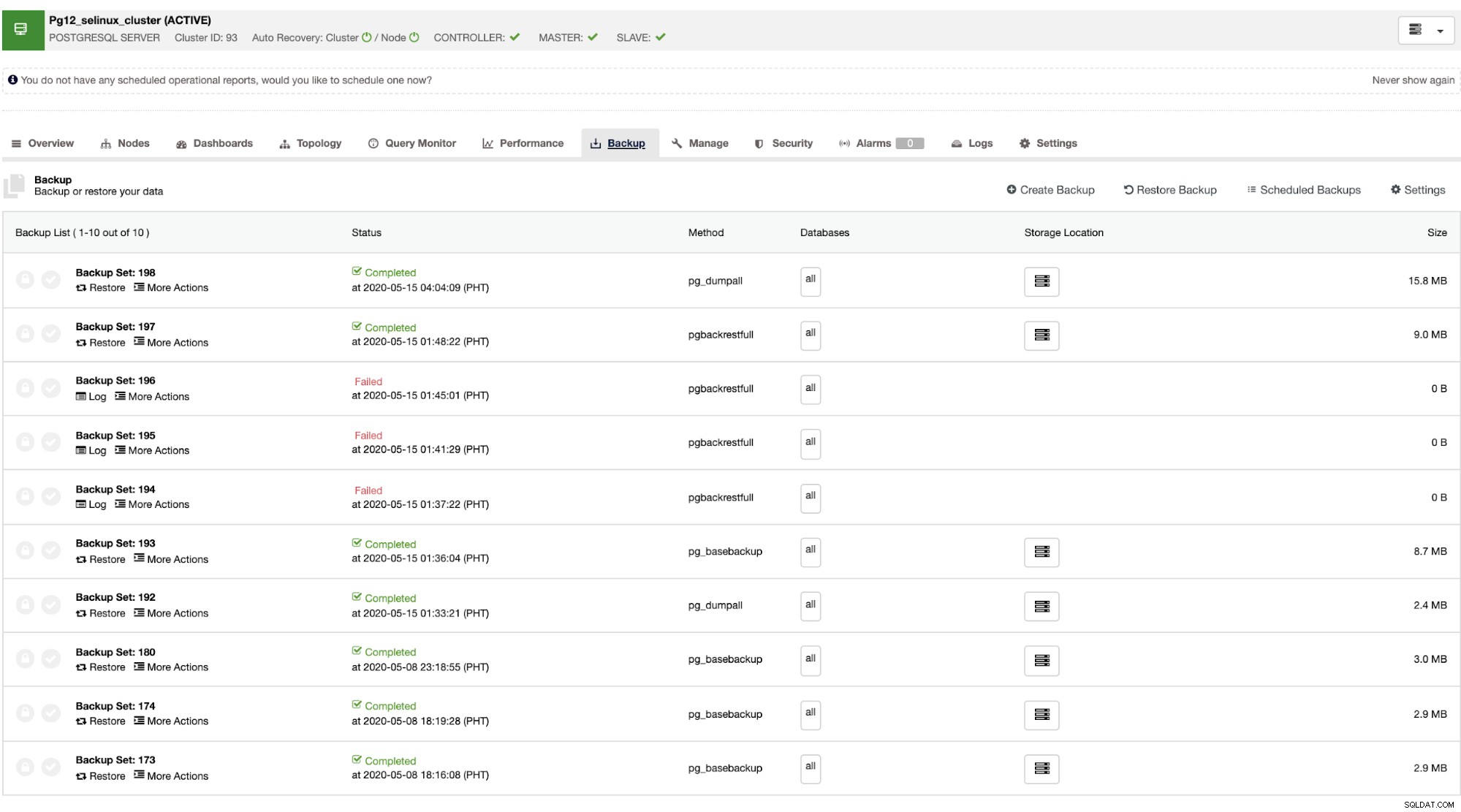
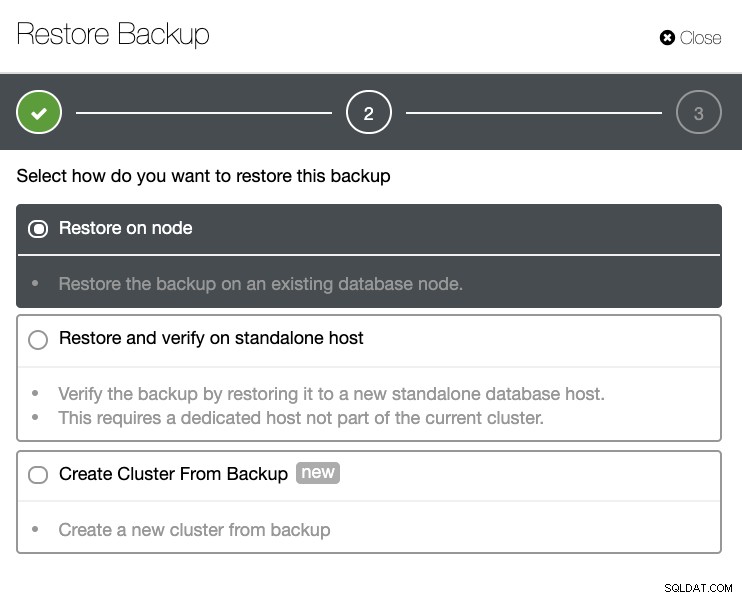
Avrai un elenco completo di backup riusciti e non riusciti. Quindi il ripristino può essere eseguito scegliendo il backup di destinazione e facendo clic sul pulsante "Ripristina". Ciò ti consentirà di eseguire il ripristino su un nodo esistente registrato in ClusterControl, di verificare su un nodo autonomo o di creare un cluster dal backup.
Conclusione
L'uso di pg_dump e pg_restore semplifica l'approccio di backup/dump e ripristino. Tuttavia, per un ambiente di database su larga scala, questo potrebbe non essere un componente ideale per il ripristino di emergenza. Per una procedura minima di selezione e ripristino, l'utilizzo della combinazione di pg_dump e pg_restore fornisce la possibilità di scaricare e caricare i dati in base alle proprie esigenze.
Per gli ambienti di produzione (soprattutto per le architetture aziendali) è possibile utilizzare l'approccio ClusterControl per creare un backup e un ripristino con ripristino automatico.
Anche una combinazione di approcci è un buon approccio. Questo ti aiuta a ridurre il tuo RTO e RPO e allo stesso tempo sfruttare il modo più flessibile per ripristinare i tuoi dati quando necessario.