Il monitoraggio è uno dei compiti fondamentali in qualsiasi sistema. Può aiutarci a rilevare problemi e ad agire, o semplicemente a conoscere lo stato attuale dei nostri sistemi. L'uso di display visivi può renderci più efficaci poiché possiamo rilevare più facilmente i problemi di prestazioni.
In questo blog vedremo come utilizzare SCUMM per monitorare i nostri database PostgreSQL e quali metriche possiamo utilizzare per questa attività. Esamineremo anche le dashboard disponibili, così potrai facilmente capire cosa sta realmente accadendo con le tue istanze PostgreSQL.
Cos'è SCUMM?
Prima di tutto, vediamo cos'è SCUMM (Severalnines ClusterControl Unified Monitoring and Management).
È una nuova soluzione basata su agenti con agenti installati sui nodi del database.
Gli agenti SCUMM sono esportatori Prometheus che esportano metriche da servizi come PostgreSQL come metriche Prometheus.
Un server Prometheus viene utilizzato per acquisire e archiviare i dati delle serie temporali dagli agenti SCUMM.
Prometheus è un toolkit di monitoraggio e avviso di sistema open source originariamente creato su SoundCloud. Ora è un progetto open source autonomo e gestito in modo indipendente.
Prometheus è progettato per l'affidabilità, per essere il sistema a cui ti rivolgi durante un'interruzione per consentirti di diagnosticare rapidamente i problemi.
Come si usa SCUMM?
Quando si utilizza ClusterControl, quando selezioniamo un cluster, possiamo vedere una panoramica dei nostri database, nonché alcune metriche di base che possono essere utilizzate per identificare un problema. Nella dashboard sottostante, possiamo vedere una configurazione master-slave con un master e 2 slave, con HAProxy e Keepalived.
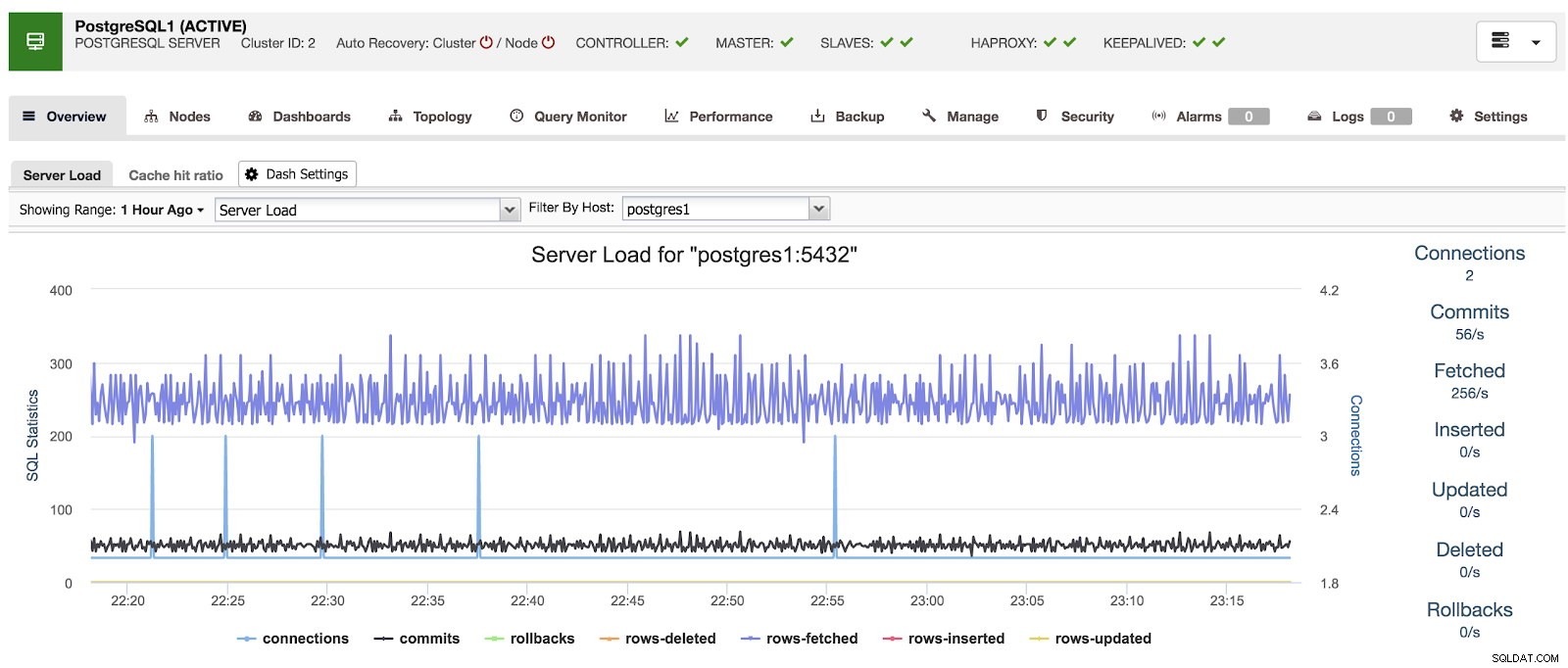 Panoramica di ClusterControl
Panoramica di ClusterControl Se andiamo all'opzione "Dashboard", possiamo vedere un messaggio come il seguente.
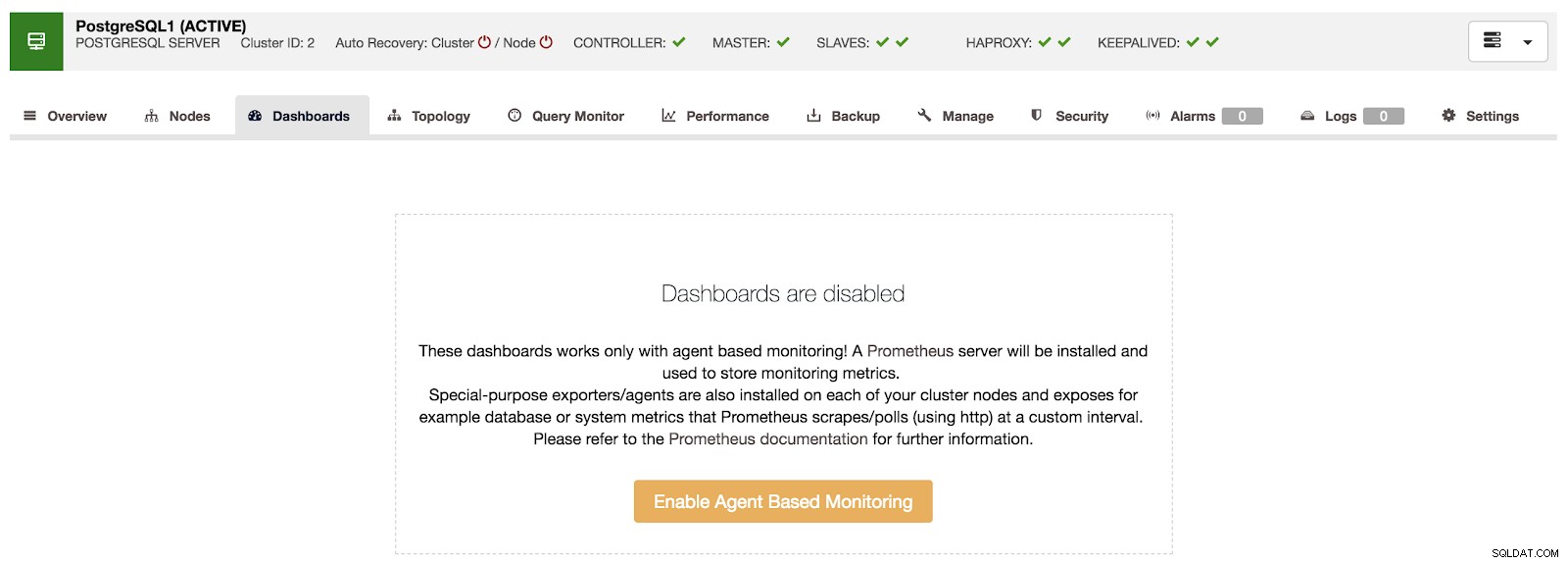 Dashboard ClusterControl disabilitato
Dashboard ClusterControl disabilitato Per utilizzare questa funzione, dobbiamo abilitare l'agente sopra menzionato. Per questo, dobbiamo solo premere il pulsante "Abilita monitoraggio basato sugli agenti" in questa sezione.
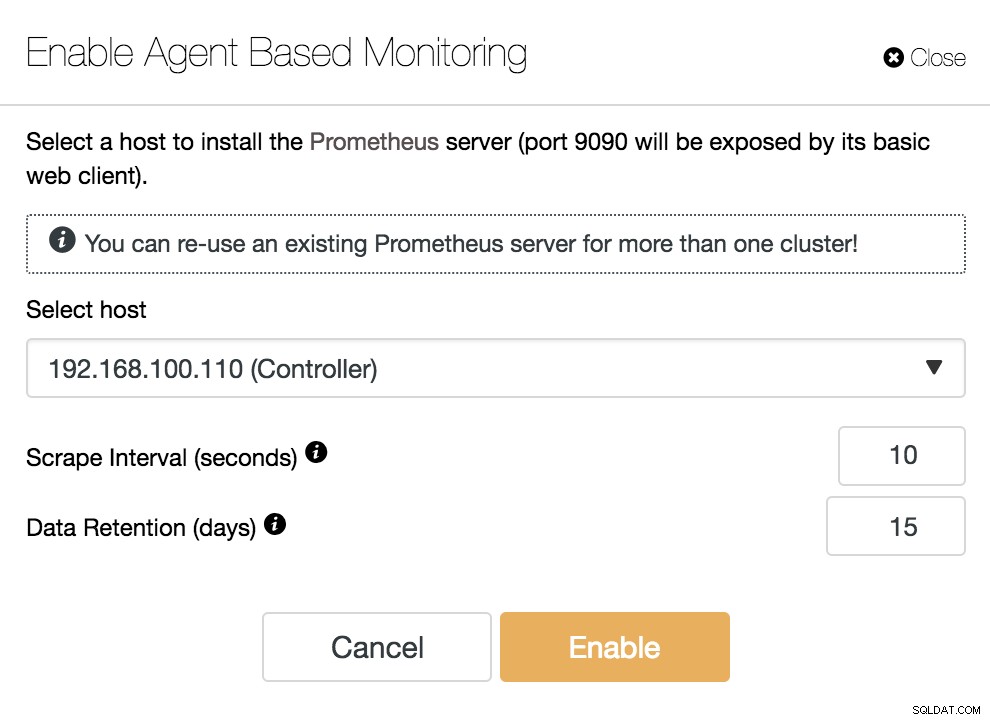 ClusterControl Abilita monitoraggio basato su agente
ClusterControl Abilita monitoraggio basato su agente Per abilitare il nostro agent, dobbiamo specificare l'host dove installeremo il nostro server Prometheus, che, come possiamo vedere nell'esempio, può essere il nostro server ClusterControl.
Dobbiamo anche specificare:
- Intervallo di raschiamento (secondi):imposta la frequenza con cui i nodi vengono raschiati per le metriche. L'impostazione predefinita è 10 secondi.
- Conservazione dei dati (giorni):imposta per quanto tempo le metriche vengono conservate prima di essere rimosse. L'impostazione predefinita è 15 giorni.
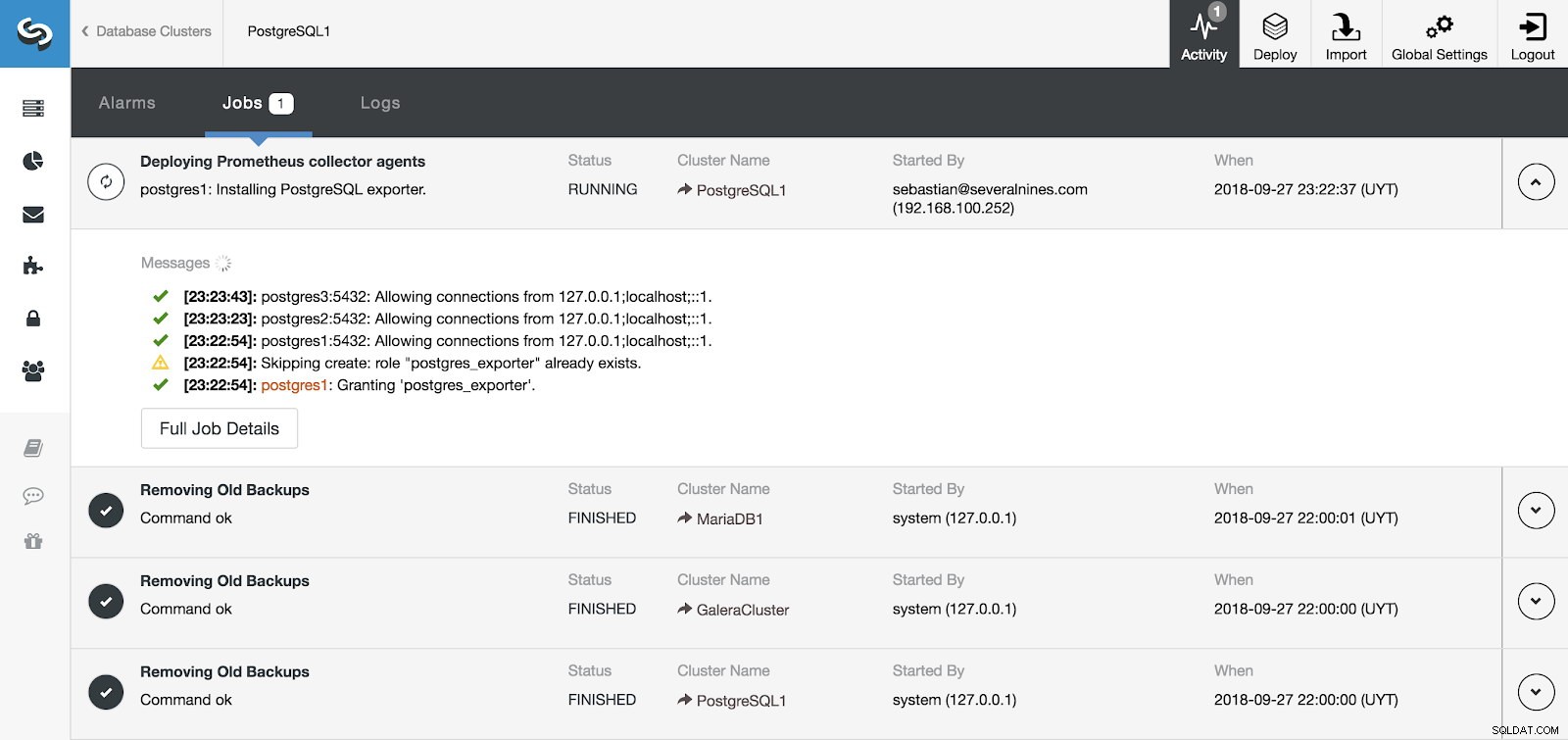 Sezione attività ClusterControl
Sezione attività ClusterControl Possiamo monitorare l'installazione del nostro server e degli agenti dalla sezione Attività in ClusterControl e, una volta terminato, possiamo vedere il nostro cluster con gli agenti abilitati dalla schermata principale di ClusterControl.
 Agenti ClusterControl abilitati
Agenti ClusterControl abilitati Dashboard
Avendo i nostri agenti abilitati, se andiamo nella sezione Dashboard, vedremmo qualcosa del genere:
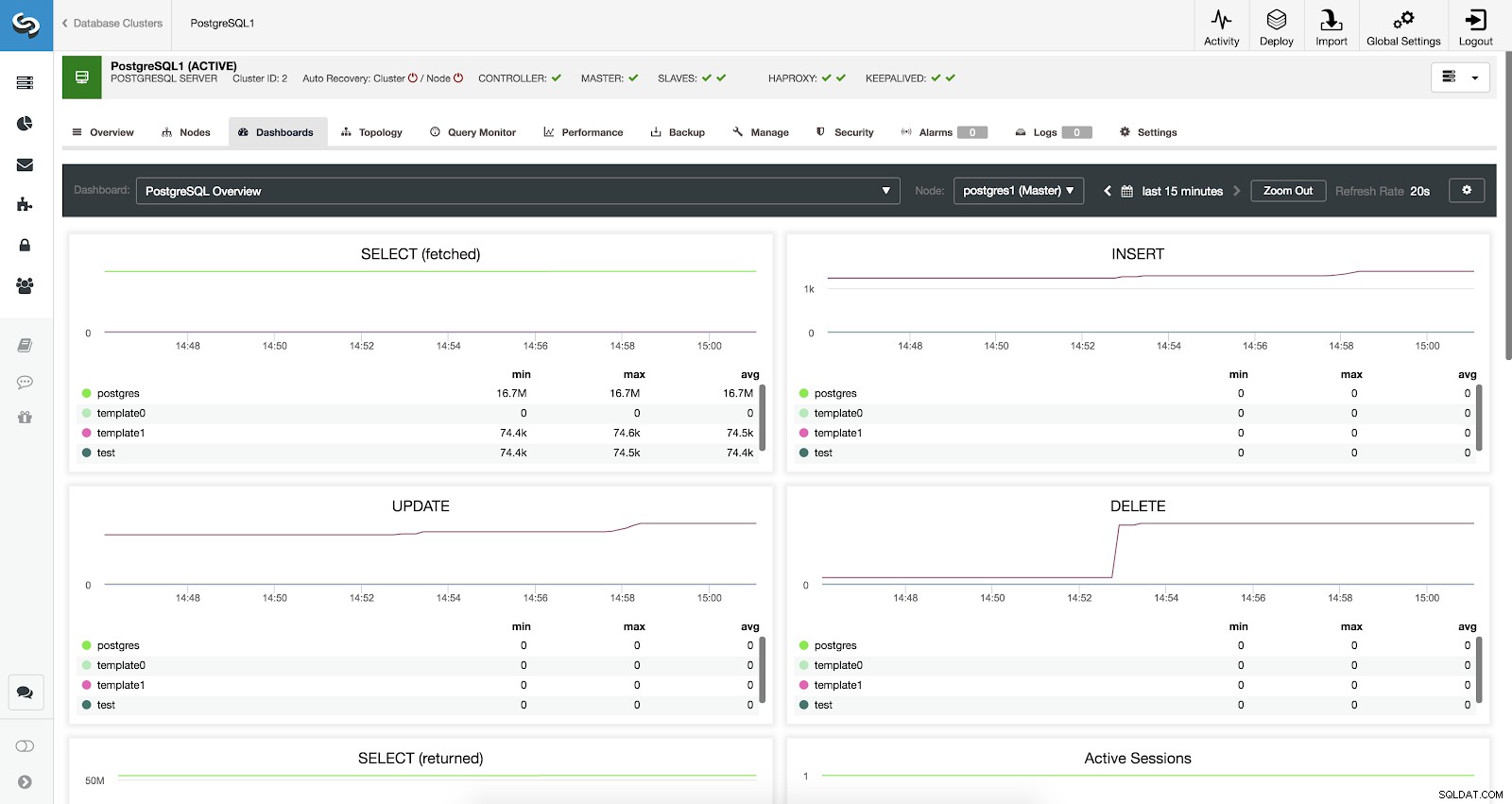 Dashboard ClusterControl abilitati
Dashboard ClusterControl abilitati Sono disponibili tre diversi tipi di dashboard, Panoramica del sistema, Grafici tra server e Panoramica di PostgreSQL. L'ultimo è quello che vediamo per impostazione predefinita quando entriamo in questa sezione.
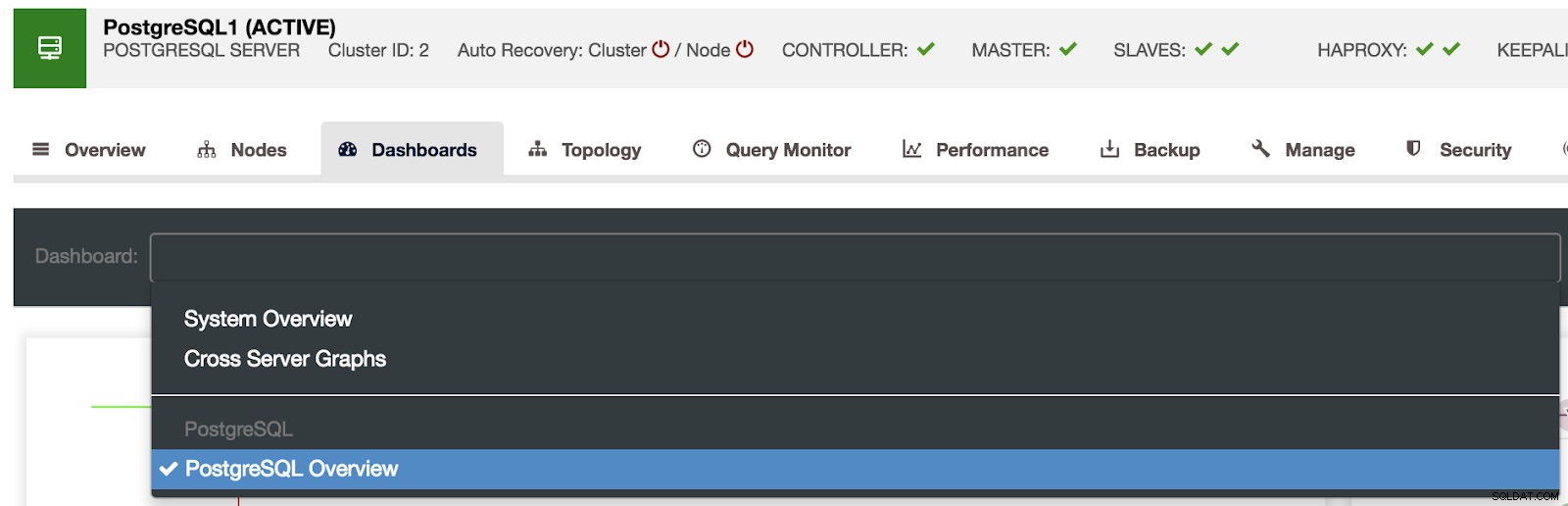 Selezione dashboard di ClusterControl
Selezione dashboard di ClusterControl Qui possiamo anche specificare quale nodo monitorare, l'intervallo di tempo e la frequenza di aggiornamento.
 Opzioni dashboard di ClusterControl
Opzioni dashboard di ClusterControl Nella sezione di configurazione, possiamo abilitare o disabilitare i nostri agenti (Esportatori), controllare lo stato degli agenti e verificare la versione del nostro server Prometheus.
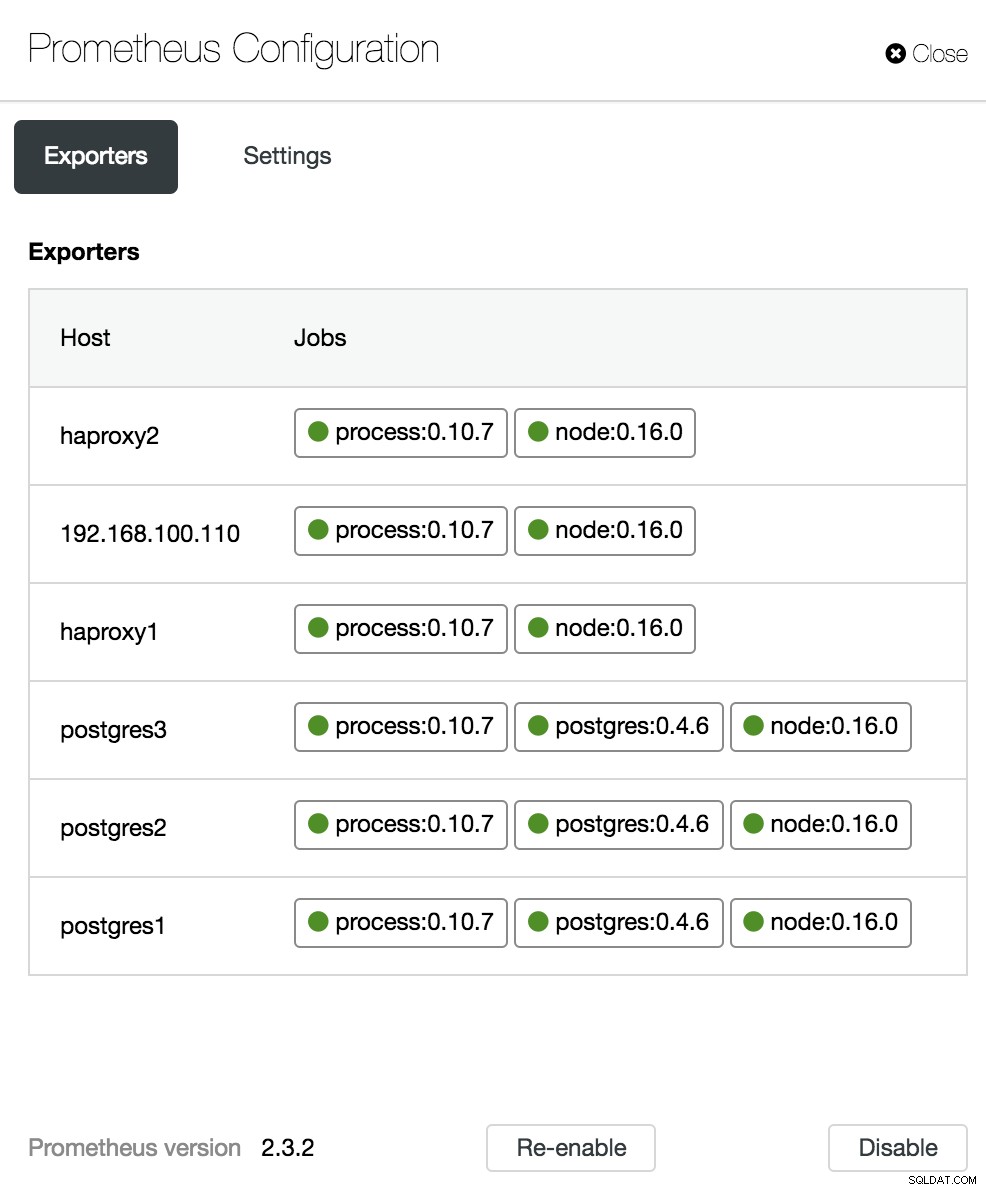 Configurazione dashboard ClusterControl
Configurazione dashboard ClusterControl Metriche di panoramica di PostgreSQL
Vediamo ora quali metriche abbiamo a disposizione per ciascuno dei nostri database PostgreSQL (tutti per il nodo selezionato).
- SELECT (prelevati):quantità di righe selezionate (prelevate) per ciascun database. Le righe recuperate si riferiscono a righe live recuperate dalla tabella.
- SELECT (restituito):quantità di righe selezionate (restituite) per ciascun database. Le righe restituite si riferiscono a tutte le righe lette dalla tabella, che include righe morte e righe non ancora impegnate (in contrasto con le righe recuperate che contano solo le tuple attive).
- INSERT:quantità di righe inserite per ogni database.
- UPDATE:quantità di righe aggiornate per ogni database.
- DELETE:quantità di righe eliminate per ogni database.
- Sessioni attive:quantità di sessioni attive (minima, massima e media) per ciascun database.
- Sessioni inattive:quantità di sessioni inattive (min, max e media) per ciascun database.
- Tabelle dei blocchi:quantità di blocchi (minimo, massimo e medio) separati per tipo per ciascun database.
- Utilizzo IO disco:utilizzo IO disco del server.
- Utilizzo del disco:percentuale di utilizzo del disco del server (minimo, massimo e medio).
- Latenza del disco:latenza del disco del server.
Metriche di panoramica di ClusterControl PostgreSQL Metriche della panoramica del sistema
Per monitorare il nostro sistema, abbiamo a disposizione per ogni server le seguenti metriche (tutte per il nodo selezionato):
- Tempo di attività del sistema:tempo trascorso dall'attivazione del server.
- CPU:quantità di CPU.
- RAM:quantità di memoria RAM.
- Memoria disponibile:percentuale di memoria RAM disponibile.
- Carico medio:carico del server minimo, massimo e medio.
- Memoria:memoria del server disponibile, totale e utilizzata.
- Utilizzo CPU:informazioni sull'utilizzo minimo, massimo e medio della CPU del server.
- Distribuzione della memoria:distribuzione della memoria (buffer, cache, disponibile e utilizzata) sul nodo selezionato.
- Metriche di saturazione:min, max e media del carico IO e CPU sul nodo selezionato.
- Dettagli avanzati della memoria:dettagli sull'utilizzo della memoria come pagine, buffer e altro, sul nodo selezionato.
- Forks:quantità di processi di fork. Il fork è un'operazione in base alla quale un processo crea una copia di se stesso. Di solito è una chiamata di sistema, implementata nel kernel.
- Processi:quantità di processi in esecuzione o in attesa sul sistema operativo.
- Cambi di contesto:un cambio di contesto è l'azione di memorizzazione dello stato di un processo o di un thread.
- Interrupt:quantità di interrupt. Un interrupt è un evento che altera il normale flusso di esecuzione di un programma e può essere generato da dispositivi hardware o anche dalla stessa CPU.
- Traffico di rete:traffico di rete in entrata e in uscita in KByte al secondo sul nodo selezionato.
- Utilizzo della rete ogni ora:traffico inviato e ricevuto nell'ultimo giorno.
- Scambia:scambia l'utilizzo (gratuito e usato) sul nodo selezionato.
- Attività di scambio:legge e scrive i dati durante lo scambio.
- Attività I/O:pagina dentro e fuori pagina su IO.
- Descrittori di file:descrittori di file allocati e limitati.
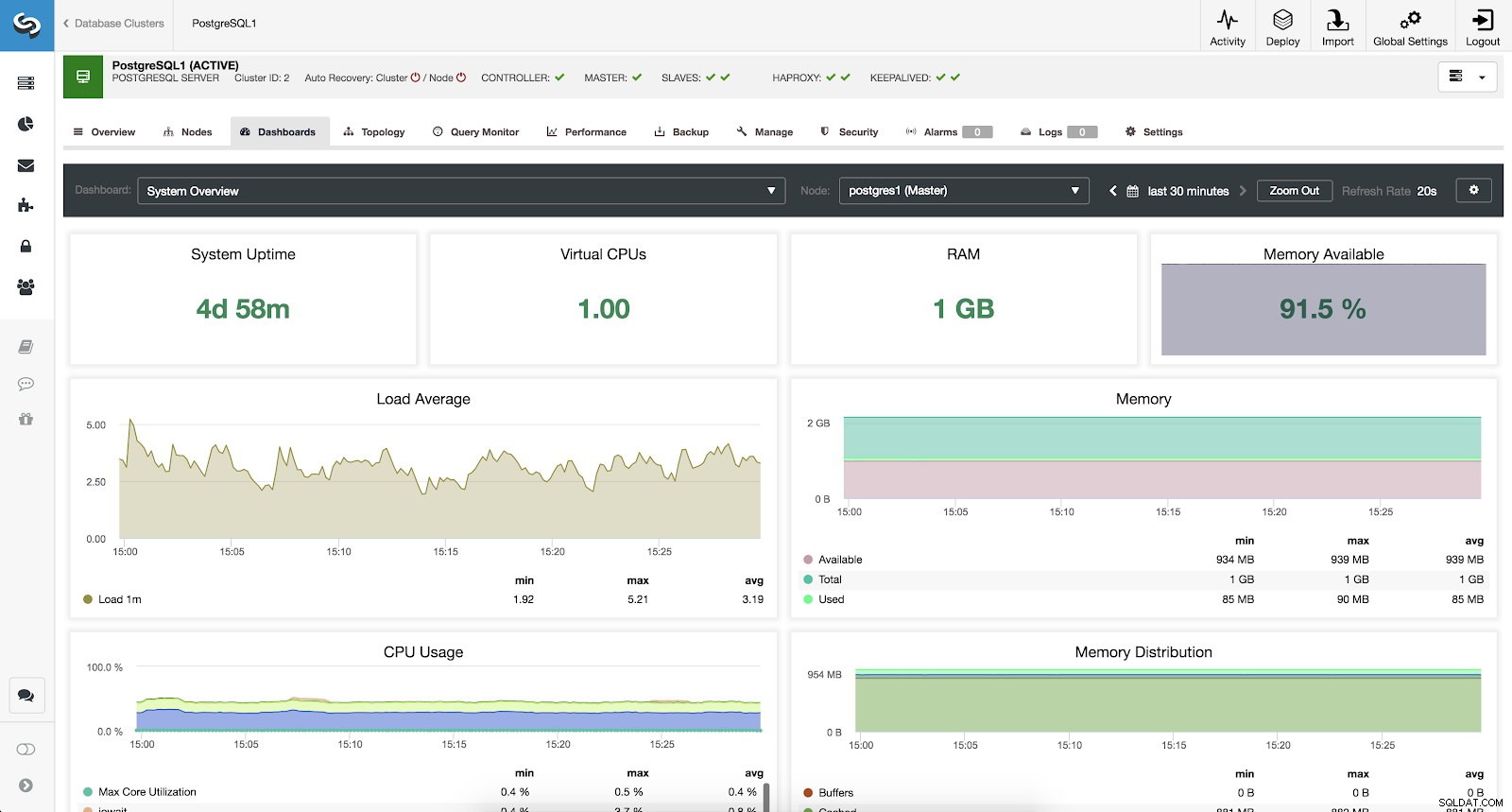 Panoramica del sistema ClusterControl Metriche
Panoramica del sistema ClusterControl Metriche Metriche di grafici cross server
Se vogliamo vedere lo stato generale di tutti i nostri server possiamo utilizzare questa dashboard con le seguenti metriche:
- Carico medio:i server caricano in media per ciascun server.
- Utilizzo della memoria:percentuale di utilizzo della memoria per ciascun server.
- Traffico di rete:kByte minimo, massimo e medio di traffico di rete al secondo.
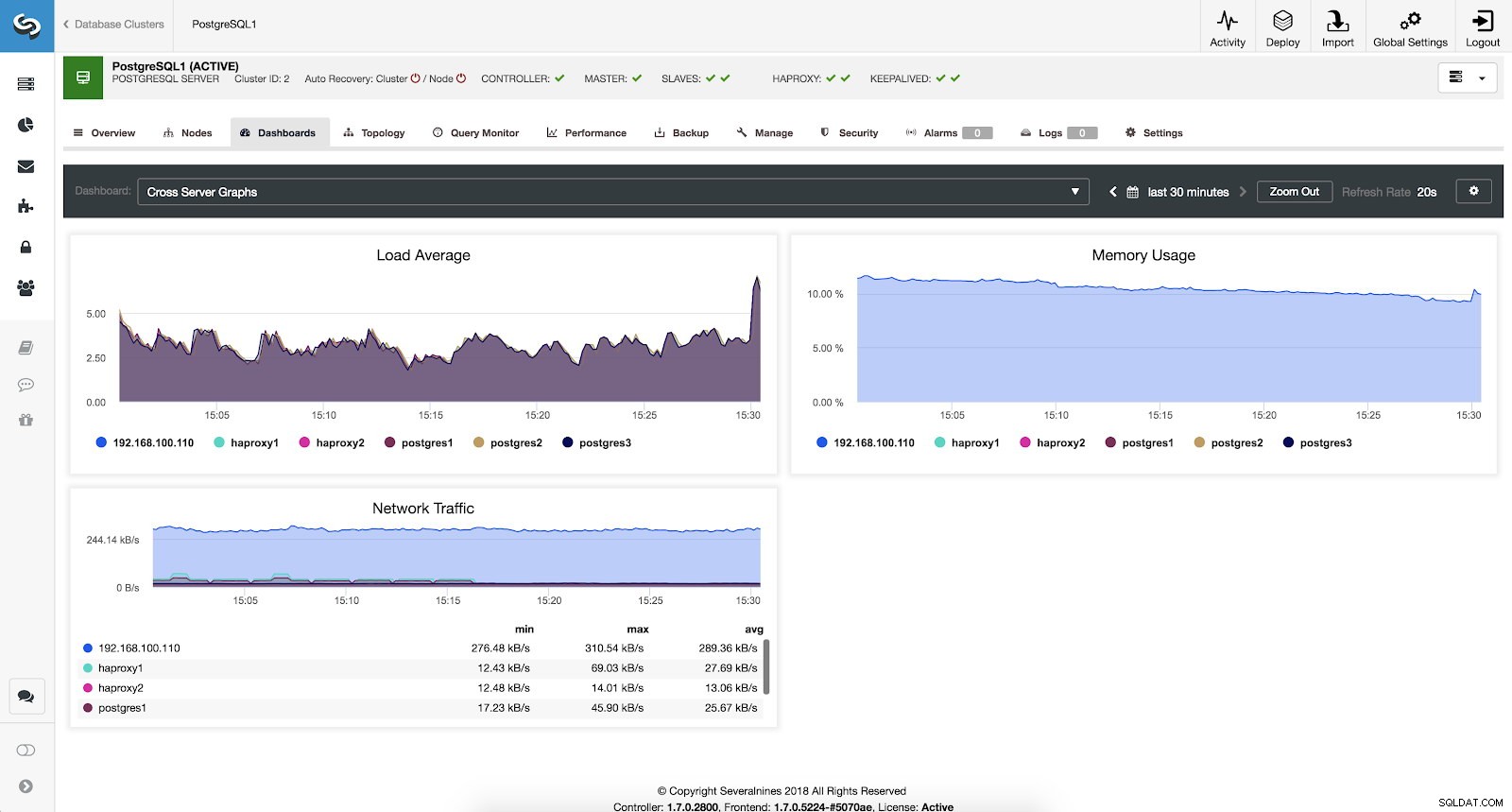 Metriche di ClusterControl Cross Server Graphs
Metriche di ClusterControl Cross Server Graphs Conclusione
Esistono diversi modi per monitorare PostgreSQL. ClusterControl fornisce monitoraggio sia senza agente che ora basato su agente tramite Prometheus. Fornisce dati di monitoraggio a risoluzione più elevata, nonché dashboard diversi per comprendere le prestazioni del database. ClusterControl può anche integrarsi con strumenti esterni come Slack o PagerDuty per gli avvisi.