Il monitoraggio di PostgreSQL, a volte, può essere come cercare di litigare con il bestiame durante un temporale. Le applicazioni si connettono ed emettono query così rapidamente che è difficile vedere cosa sta succedendo o anche avere una buona panoramica delle prestazioni del sistema a parte il tipico sviluppatore che si lamenta di "le cose vanno lentamente, aiuto!".
In articoli precedenti, abbiamo discusso di come arrivare all'origine quando PostgreSQL agisce lentamente, ma quando l'origine è costituita da query specifiche, il monitoraggio di livello di base potrebbe non essere sufficiente per valutare cosa sta succedendo in un ambiente live attivo.
Immettere pg_top, un programma specifico di PostgreSQL per monitorare l'attività in tempo reale in un database, oltre a visualizzare le informazioni di base per l'host del database stesso. Proprio come il comando linux "top", l'esecuzione porta l'utente in una visualizzazione interattiva dal vivo dell'attività del database sull'host, aggiornandosi automaticamente a intervalli.
Installazione
L'installazione di pg_top può essere eseguita nei modi generalmente previsti:gestori di pacchetti e installazione del codice sorgente. La versione più recente di questo articolo è la 3.7.0.
Gestori di pacchetti
In base alla distribuzione di Linux in questione, cerca pgtop o pg_top nel gestore di pacchetti, è probabile che sia disponibile in qualche aspetto per la versione installata di PostgreSQL sul sistema.
Distribuzioni basate su Red Hat:
# sudo yum install pg_topDistribuzioni basate su Gentoo:
# sudo apt-get install pgtopFonte
Se lo si desidera, pg_top può essere installato tramite il sorgente dal repository git di PostgreSQL. Ciò fornirà qualsiasi versione desiderata, anche build più recenti che non sono ancora nelle versioni ufficiali.
Caratteristiche
Una volta installato, pg_top funziona come una visualizzazione in tempo reale molto accurata nel database che sta monitorando e utilizzando la riga di comando per eseguire "pg_top" verrà avviato lo strumento di monitoraggio interattivo PostgreSQL.
Lo strumento stesso può aiutare a far luce su tutti i processi attualmente connessi al database.
In esecuzione pg_top
L'avvio di pg_top è lo stesso del comando 'top' in stile unix / linux, insieme alle informazioni di connessione al database.
Per eseguire pg_top su un host di database locale:
pg_top -h localhost -p 5432 -d severalnines -U postgresPer eseguire pg_top su un host remoto, è richiesto il flag -r o --remote-mode e l'estensione pg_proctab installata sull'host stesso:
pg_top -r -h 192.168.1.20 -p 5432 -d severalnines -U postgresCosa c'è sullo schermo
All'avvio di pg_top, vediamo un display con un bel po' di informazioni.
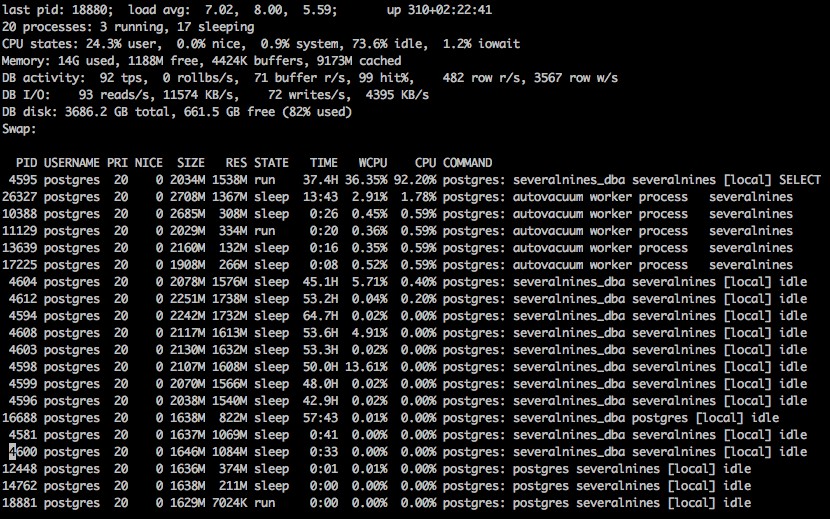 Output standard da pg_top su Linux
Output standard da pg_top su Linux
Carico medio:
Come il comando top standard, questo carico è in media per intervalli di 1, 5 e 15 minuti.
Tempo di attività:
Il tempo totale in cui il sistema è rimasto online dall'ultimo riavvio.
Processi:
Il numero totale di processi di database connessi, con un numero di quanti sono in esecuzione e quanti sono inattivi.
Statistiche CPU:
Le statistiche della CPU, che mostrano la percentuale di carico per utente, sistema e inattività, informazioni utili e percentuali di iowait.
Memoria:
La quantità totale di memoria utilizzata, libera, nei buffer e nella cache.
Attività del database:
Le statistiche per l'attività del database come le transazioni al secondo, il numero di rollback al secondo, i buffer letti al secondo, i buffer colpiti al secondo, il numero di righe lette al secondo e le righe scritte al secondo.
Attività I/O DB:
L'attività per Input Output sul sistema, che mostra quante letture e scritture al secondo, nonché la quantità letta e scritta al secondo.
Statistiche disco DB:
La dimensione totale del disco del database, nonché la quantità di spazio libero.
Scambia:
Le informazioni sullo spazio di scambio utilizzato, se presente.
Processi:
Un elenco di processi collegati al database, incluso qualsiasi tipo di autovacuum dei processi interni. L'elenco include il pid, la priorità, la bella quantità, la memoria residente utilizzata, lo stato della connessione, il numero di secondi di CPU utilizzati, la percentuale di CPU e il comando corrente che il processo sta eseguendo.
Utili funzioni interattive
Ci sono una manciata di funzioni interattive in pg_top a cui è possibile accedere mentre è in esecuzione. È possibile trovare un elenco completo inserendo un ?, che farà apparire una schermata di aiuto con tutte le diverse opzioni disponibili.
Informazioni sul pianificatore
E - Piano di esecuzione
Immettendo E verrà richiesto un ID processo per il quale mostrare un piano esplicativo. Ciò equivale a eseguire “EXPLAIN
A - EXPLAIN ANALYZE (UPDATE/DELETE sicuro)
L'inserimento di A fornirà un prompt per un ID processo per il quale mostrare un piano EXPLAIN ANALYZE. Ciò equivale a eseguire "EXPLAIN ANALYZE
Informazioni sul processo
Q - Mostra la query corrente di un processo
Immettendo Q verrà richiesto un ID processo per il quale mostrare la query completa.
I - Mostra le statistiche di I/O per processo (solo Linux)
Inserendo I commuta l'elenco dei processi in un display I/O, mostrando ogni processo di lettura, scrittura, ecc. su disco.
L - Mostra i blocchi mantenuti da un processo
Immettendo L verrà richiesto un ID processo per il quale mostrare i blocchi mantenuti. Ciò includerà il database, la tabella, il tipo di blocco e se il blocco è stato concesso o meno. Utile per esplorare processi di lunga durata o in attesa.
Informazioni sulla relazione
R - Mostra le statistiche della tabella utente.
L'immissione di R mostra le statistiche della tabella incluse scansioni sequenziali, scansioni dell'indice, INSERT, UPDATE ed DELETE, tutti rilevanti per l'attività recente.
X - Mostra le statistiche dell'indice utente
Immettendo X vengono visualizzate le statistiche dell'indice, comprese le scansioni dell'indice, le letture degli indici e i recuperi degli indici, tutti rilevanti per l'attività recente.
Ordinamento
L'ordinamento del display può essere eseguito tramite uno dei seguenti caratteri.
M - Ordina per utilizzo memoria
N - Ordina per pid
P - Ordina per utilizzo CPU
T - Ordina per tempo
Di seguito sono riportate le voci specificate dopo aver premuto o, consentendo anche l'ordinamento dell'indice, della tabella e delle pagine delle statistiche i/o.
o - Specifica l'ordinamento (cpu, dimensione, res, ora, comando)
index stats (idx_scan, idx_tup_fetch, idx_tup_read)
table stats (seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins, n_tup_upd, n_tup_del)
s cr i/o stats (pid, rchar, wchar, wchar, wchar, wchar, , scrive, scrive, comando)
Connessione / Manipolazione query
k - kill process specificati
L'inserimento di k fornirà un prompt per un processo o un elenco di processi di database da terminare.
r - renice a process (solo database locale, solo root)
L'immissione di r fornirà un prompt per un valore piacevole, seguito da un elenco di processi da impostare su quel nuovo valore piacevole. Questo cambia la priorità dei processi importanti nel sistema.
Esempio:“renice 1 7004”
Usi diversi di pg_top
Utilizzo reattivo di pg_top
L'uso generale di pg_top è la modalità interattiva, che ci consente di vedere quali query sono in esecuzione su un sistema che sta riscontrando problemi di lentezza, eseguire piani di spiegazione su tali query, rielaborare query importanti per farle completare più rapidamente o eliminare tutte le query che causano gravi rallentamenti . In genere, consente all'amministratore del database di fare molte delle stesse cose che possono essere fatte manualmente sul sistema, ma in un modo più rapido e tutto in un'unica opzione.
Utilizzo proattivo di pg_top
Anche se non è troppo comune, pg_top può essere eseguito in "modalità batch", che visualizzerà le informazioni principali discusse per standard out, quindi esce. Questo può essere programmato per l'esecuzione a determinati intervalli, quindi inviato a qualsiasi processo personalizzato desiderato, analizzato e avvisi generati in base a ciò su cui l'amministratore potrebbe voler essere avvisato. Ad esempio, se il carico del sistema diventa troppo elevato, se c'è un valore di transazioni al secondo superiore al previsto, qualsiasi cosa un programma creativo possa capire.
In genere, ci sono altri strumenti per raccogliere e segnalare queste informazioni, ma avere più opzioni è sempre una buona cosa e, avendo più strumenti disponibili, è possibile trovare le opzioni migliori.
Uso storico di pg_top
Proprio come l'utilizzo precedente, l'utilizzo proattivo, possiamo eseguire lo script di pg_top in modalità batch per registrare istantanee di come appare il database nel tempo. Questo può essere semplice come scriverlo in un file di testo con un timestamp o analizzarlo e archiviare la data in un database relazionale per generare report. Ciò consentirebbe di trovare più informazioni dopo un incidente grave, come un arresto anomalo del database alle 4 del mattino. Più dati sono disponibili, più è probabile che si verifichino problemi.
Maggiori informazioni
La documentazione per il progetto è piuttosto limitata e la maggior parte delle informazioni è disponibile nella pagina man di linux, trovata eseguendo "man pg_top". La community di PostgreSQL può aiutare con domande o problemi tramite le mailing list di PostgreSQL o la chat room ufficiale di IRC che si trova su freenode, nome del canale #postgresql.