Cos'è Slony?
Slony-I (indicato come "Slony" da qui in poi) è un sistema di replica di terze parti per PostgreSQL che risale a prima della versione 8.0, il che lo rende una delle opzioni più vecchie per la replica disponibili. Funziona come un metodo di replica basato su trigger che è una soluzione "da master a più slave".
Slony opera installando trigger su ogni tabella da replicare, sia su master che su slave, e ogni volta che la tabella riceve un INSERT, UPDATE o DELETE, registra quale record viene modificato e qual è la modifica. I processi esterni, chiamati "daemon slon", si connettono ai database come qualsiasi altro client e recuperano le modifiche dal master, quindi le riproducono su tutti i nodi slave sottoscritti al master. In una configurazione di replica con buone prestazioni, questo è asincrono ci si può aspettare che la replica sia in ritardo da 1 a 20 secondi rispetto al master.
Al momento della stesura di questo articolo, l'ultima versione di Slony è alla versione 2.2.6 e supporta PostgreSQL 8.3 e versioni successive. Il supporto continua ancora oggi con aggiornamenti minori, tuttavia se una versione futura di PostgreSQL cambia funzionalità fondamentali di transazioni, funzioni, trigger o altre funzionalità principali, il progetto Slony potrebbe decidere di interrompere gli aggiornamenti di grandi dimensioni per supportare nuovi approcci così drastici.
La mascotte di PostgreSQL è un elefante noto come "Slonik", che in russo significa "piccolo elefante". Poiché questo progetto di replica riguarda molti database PostgreSQL che si replicano tra loro, viene utilizzata la parola russa per elefanti (plurale):Slony.
Concetti
- Cluster:un'istanza di replica Slony.
- Nodo:un database PostgreSQL specifico come nodo di replica Slony, che opera come master o slave per un set di replica.
- Set di repliche:un gruppo di tabelle e/o sequenze da replicare.
- Abbonati:un abbonato è un nodo che è iscritto a un set di replica e riceve eventi di replica per tutte le tabelle e le sequenze all'interno di quel set dal nodo master.
- Daemon Slony:i principali worker che eseguono la replica, un demone Slony viene avviato per ogni nodo nel set di replica e stabilisce varie connessioni al nodo che gestisce, nonché al nodo master.
Come viene utilizzato
Slony viene installato dal sorgente o tramite i repository PGDG (PostgreSQL Global Development Group), disponibili per le distribuzioni Linux basate su Red Hat e Debian. Questi binari devono essere installati su tutti gli host che conterranno un nodo master o slave nel sistema di replica.
Dopo l'installazione, viene configurato un cluster di replica Slony emettendo alcuni comandi utilizzando il binario "slonik". 'slonik' è un comando con una sintassi semplice ma unica per inizializzare e mantenere un cluster slony. È l'interfaccia principale per l'invio di comandi al cluster Slony in esecuzione che è responsabile della replica.
L'interfaccia con Slony può essere eseguita scrivendo comandi slonik personalizzati o compilando slony con il flag --with-perltools, che fornisce gli script "altperl" che aiutano a generare questi script slonik necessari.
Creazione di un cluster di replica Slony
Un "Cluster di replica" è una raccolta di database che fanno parte della replica. Quando si crea un cluster di replica, è necessario scrivere uno script init che definisca quanto segue:
- Il nome del cluster Slony desiderato
- Le informazioni di connessione per ciascuna parte del nodo della replica, ciascuna con un numero di nodo immutabile.
- Elencare tutte le tabelle e le sequenze da replicare come parte di un "set di repliche".
Uno script di esempio può essere trovato nella documentazione ufficiale di Slony.
Una volta eseguito, slonik si collegherà a tutti i nodi definiti e creerà lo schema Slony su ciascuno. Quando i demoni Slony vengono avviati, cancelleranno tutti i dati nelle tabelle replicate sullo slave (se ce ne sono) e copieranno tutti i dati dal master agli slave. Da quel momento in poi, i demoni replicheranno continuamente le modifiche registrate sul master a tutti gli slave sottoscritti.
Configurazioni intelligenti
Sebbene Slony sia inizialmente un sistema di replica Master-to-Multiple-Slave e sia stato utilizzato principalmente in questo modo, ci sono molte altre funzionalità e usi intelligenti che rendono Slony più utile di una semplice soluzione di replica. La natura altamente personalizzabile di Slony lo mantiene rilevante per una varietà di situazioni per gli amministratori che possono pensare fuori dagli schemi.
Replica a cascata
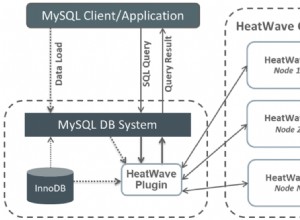
I nodi Slony possono essere impostati per la replica a cascata lungo una catena di nodi diversi. Se è noto che il nodo master sopporta un carico estremamente pesante, ogni slave aggiuntivo aumenterà leggermente tale carico. Con la replica in cascata, un singolo nodo slave collegato al master può essere configurato come un "nodo di inoltro", che sarà quindi responsabile dell'invio di eventi di replica a più slave, mantenendo al minimo il carico sul nodo master.
 Replica a cascata con Slony
Replica a cascata con Slony Elaborazione dati su un nodo slave
A differenza della replica incorporata di PostgreSQL, i nodi slave non sono in realtà "di sola lettura", solo le tabelle che vengono replicate sono bloccate come "sola lettura". Ciò significa che su un nodo slave, l'elaborazione dei dati può avvenire creando nuove tabelle che non fanno parte della replica per ospitare i dati elaborati. Le tabelle che fanno parte della replica possono anche avere indici personalizzati creati a seconda dei modelli di accesso che possono differire dallo slave e dal master.
Le tabelle di sola lettura sugli slave possono ancora avere funzioni personalizzate basate su trigger eseguite sulle modifiche ai dati, consentendo una maggiore personalizzazione con i dati.
 Elaborazione dei dati su un nodo slave Slony
Elaborazione dei dati su un nodo slave Slony Aggiornamenti minimi dei tempi di inattività
L'aggiornamento delle versioni principali di PostgreSQL può richiedere molto tempo. A seconda della dimensione dei dati e del conteggio delle tabelle, un aggiornamento che includa il processo di "analisi" successivo all'aggiornamento potrebbe richiedere anche diversi giorni. Poiché Slony può replicare i dati tra cluster PostgreSQL di versioni diverse, può essere utilizzato per impostare la replica tra una versione precedente come master e una versione più recente come slave. Quando l'aggiornamento deve avvenire, è sufficiente eseguire un "passaggio", rendendo lo slave il nuovo master e il vecchio master diventa lo slave. Quando l'aggiornamento viene contrassegnato come un successo, disattiva il cluster di replica Slony e chiudi il vecchio database.
 Aggiorna PostgreSQL con tempi di inattività minimi utilizzando Slony
Aggiorna PostgreSQL con tempi di inattività minimi utilizzando Slony Elevata disponibilità con manutenzione frequente del server
Come il tempo di inattività minimo per gli aggiornamenti, la manutenzione del server può essere eseguita facilmente senza tempi di inattività eseguendo un "passaggio" tra due o più nodi, consentendo il riavvio di uno slave con aggiornamenti / altra manutenzione. Quando lo slave torna in linea, si riconnetterà al cluster di replica e recupererà tutti i dati replicati. Gli utenti finali che si connettono al database potrebbero avere lunghe transazioni interrotte, ma il tempo di inattività stesso sarebbe di pochi secondi quando si verifica il passaggio, piuttosto che il tempo necessario per riavviare/aggiornare l'host.
Spedizione log
Sebbene non sia probabilmente una soluzione popolare, uno slave Slony può essere impostato come nodo di "trasmissione di log", in cui tutti i dati che riceve tramite la replica possono essere scritti su file SQL e spediti. Questo può essere utilizzato per una serie di motivi, come la scrittura su un'unità esterna e il trasporto su un database slave manualmente, e non su una rete, compresso e mantenuto archiviato per backup futuri, o anche fare in modo che un programma esterno analizzi i file SQL e modificare i contenuti.
Condivisione di più dati di database
Poiché qualsiasi numero di tabelle può essere replicato a piacimento, i set di replica Slony possono essere impostati per condividere tabelle specifiche tra database. Sebbene un accesso simile possa essere ottenuto tramite i wrapper di dati esterni (che sono stati migliorati nelle recenti versioni di PostgreSQL), potrebbe essere una soluzione migliore utilizzare Slony a seconda dell'utilizzo. Se è necessaria una grande quantità di dati da recuperare da un host all'altro, fare in modo che Slony replichi quei dati significa che i dati necessari saranno già presenti sul nodo richiedente, eliminando i lunghi tempi di trasferimento.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri ciò che devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperReplica ritardata
Solitamente si desidera che la replica sia il più rapida possibile, ma ci possono essere alcuni scenari in cui si desidera un ritardo. Il demone slon per un nodo slave può essere configurato con un lag_interval, il che significa che non riceverà alcun dato di replica finché i dati non saranno vecchi come specificato. Questo può essere utile per un rapido accesso ai dati persi se qualcosa va storto, ad esempio se una riga viene eliminata, esisterà sullo slave per 1 ora per un rapido recupero.
Cose da sapere:
- Eventuali modifiche DDL alle tabelle che fanno parte della replica devono essere eseguite utilizzando il comando slonik execute.
- Ogni tabella da replicare deve avere una chiave primaria o un indice UNIQUE senza colonne annullabili.
- I dati replicati dal nodo master vengono replicati dopo che i dati potrebbero essere stati generati funzionalmente. Ciò significa che se i dati sono stati generati utilizzando qualcosa come 'random()', il numero risultante viene memorizzato e replicato sugli slave, invece di 'random()' essere eseguito nuovamente sullo slave restituendo un risultato diverso.
- L'aggiunta della replica Slony aumenterà leggermente il carico del server. Sebbene sia scritta in modo efficiente, ogni tabella avrà un trigger che registra ogni INSERT, UPDATE ed DELETE su una tabella Slony, prevedendo un aumento del carico del server di circa il 2-10%, a seconda delle dimensioni del database e del carico di lavoro.
Suggerimenti e trucchi:
- I demoni Slony possono essere eseguiti su qualsiasi host che abbia accesso a tutti gli altri host, tuttavia la configurazione con le prestazioni più elevate prevede che i demoni vengano eseguiti sui nodi che stanno gestendo. Ad esempio, il demone master in esecuzione sul nodo master, il demone slave in esecuzione sul nodo slave.
- Se si configura un cluster di replica con una quantità molto grande di dati, la copia iniziale può richiedere molto tempo, il che significa che tutte le modifiche che si verificano dall'inizio fino al completamento della copia potrebbero richiedere ancora più tempo per recuperare il ritardo ed essere sincronizzati . Questo può essere risolto aggiungendo poche tabelle alla volta alla replica (che richiede molto tempo) o creando una copia della directory dei dati del database master sullo slave, quindi eseguendo un "set di sottoscrizione" con l'opzione OMIT COPY impostata su VERO. Con questa opzione, Slony presumerà che la tabella slave sia identica al 100% al master e non la cancellerà e copierà i dati.
- Lo scenario migliore per questo è creare un Hot Standby utilizzando gli strumenti integrati per PostgreSQL e, durante una finestra di manutenzione con zero connessioni, modificare i dati, portare lo standby online come master, convalidare le corrispondenze dei dati tra i due, avviare il cluster di replica slony con OMIT COPY =true e infine riattivare le connessioni client. Questa operazione potrebbe richiedere del tempo per eseguire la configurazione per Hot Standby, ma il processo non avrà un enorme impatto negativo sui clienti.
Community e documentazione
La community per Slony può essere trovata nelle mailing list, che si trovano su https://lists.slony.info/mailman/listinfo/slony1-general, che include anche gli archivi.
La documentazione è disponibile sul sito Web ufficiale, https://slony.info/documentation/, e fornisce assistenza per l'analisi dei log e le specifiche della sintassi per l'interfaccia con slony.