Un livello proxy può essere molto utile per aumentare la disponibilità del livello del database. Può ridurre la quantità di codice lato applicazione per gestire gli errori del database e le modifiche alla topologia di replica. In questo post del blog discuteremo come configurare un HAProxy per funzionare su PostgreSQL.
Per prima cosa:HAProxy funziona con i database come proxy a livello di rete. Non vi è alcuna comprensione della topologia sottostante, a volte complessa. Tutto ciò che HAProxy fa è inviare pacchetti in modalità round robin a backend definiti. Non ispeziona i pacchetti né comprende il protocollo in cui le applicazioni parlano con PostgreSQL. Di conseguenza, non c'è modo per HAProxy di implementare la suddivisione in lettura/scrittura su una singola porta:richiederebbe l'analisi delle query. Finché la tua applicazione può dividere le letture dalle scritture e inviarle a IP o porte diversi, puoi implementare la divisione R/W utilizzando due backend. Diamo un'occhiata a come si può fare.
Configurazione HAProxy
Di seguito puoi trovare un esempio di due backend PostgreSQL configurati in HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkCome possiamo vedere, usano le porte 3307 per le scritture e 3308 per le letture. In questa configurazione sono presenti tre server:una replica attiva e due in standby. Ciò che è importante, tcp-check viene utilizzato per tenere traccia dello stato di salute dei nodi. HAProxy si connetterà alla porta 9201 e si aspetta di vedere una stringa restituita. I membri sani del backend restituiranno il contenuto previsto, quelli che non restituiranno la stringa verranno contrassegnati come non disponibili.
Impostazione Xinetd
Poiché HAProxy controlla la porta 9201, qualcosa deve rimanere in ascolto su di essa. Possiamo usare xinetd per ascoltare lì ed eseguire alcuni script per noi. La configurazione di esempio di tale servizio potrebbe essere simile a:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Devi assicurarti di aggiungere la riga:
postgreschk 9201/tcpa /etc/services.
Xinetd avvia uno script postgreschk, che ha contenuti come di seguito:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";La logica della sceneggiatura è la seguente. Ci sono due query che vengono utilizzate per rilevare lo stato del nodo.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Il primo controlla se PostgreSQL è in fase di ripristino:sarà "falso" per il server attivo e "vero" per i server in standby. Il secondo controlla se PostgreSQL è in modalità di sola lettura. Il server attivo tornerà "off" mentre i server in standby torneranno "on". Sulla base dei risultati, lo script chiama la funzione return_ok() con un parametro corretto ("master" o "slave", a seconda di ciò che è stato rilevato). Se le query hanno esito negativo, verrà eseguita una funzione "return_fail".
La funzione Return_ok restituisce una stringa basata sull'argomento che le è stato passato. Se l'host è un server attivo, lo script restituirà "PostgreSQL master is running". Se è uno standby, la stringa restituita sarà:"PostgreSQL slave è in esecuzione". Se lo stato non è chiaro, restituirà:"PostgreSQL è in esecuzione". Qui è dove il ciclo finisce. HAProxy controlla lo stato collegandosi a xinetd. Quest'ultimo avvia uno script, che restituisce una stringa che HAProxy analizza.
Come forse ricorderai, HAProxy si aspetta le seguenti stringhe:
tcp-check expect string master\ is\ runningper il backend di scrittura e
tcp-check expect string is\ running.per il back-end di sola lettura. Ciò rende il server attivo l'unico host disponibile nel backend di scrittura mentre sul backend di lettura possono essere utilizzati sia i server attivi che quelli in standby.
PostgreSQL e HAProxy in ClusterControl
La configurazione di cui sopra non è complessa, ma richiede del tempo per configurarla. ClusterControl può essere utilizzato per configurare tutto questo per te.
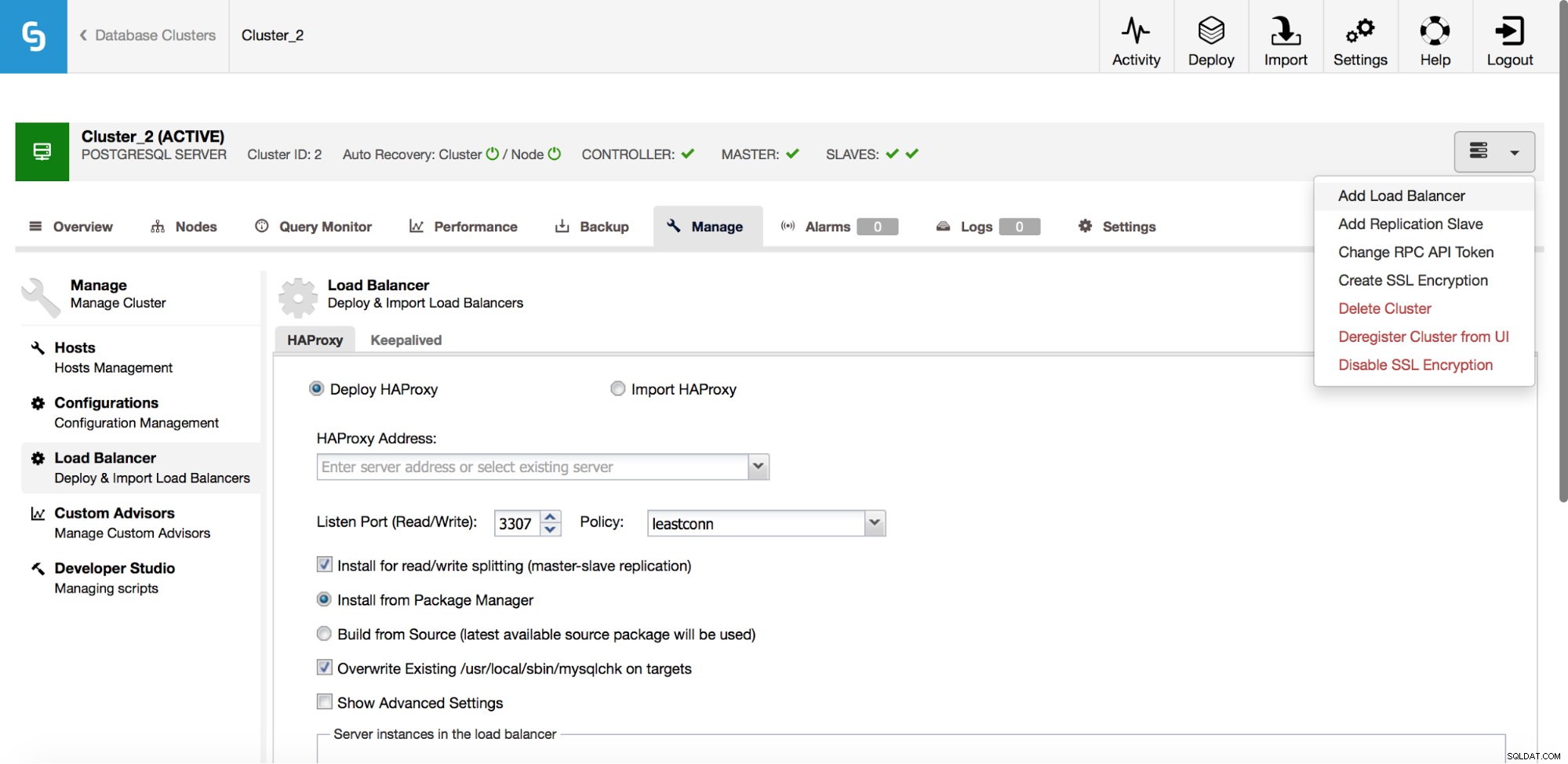
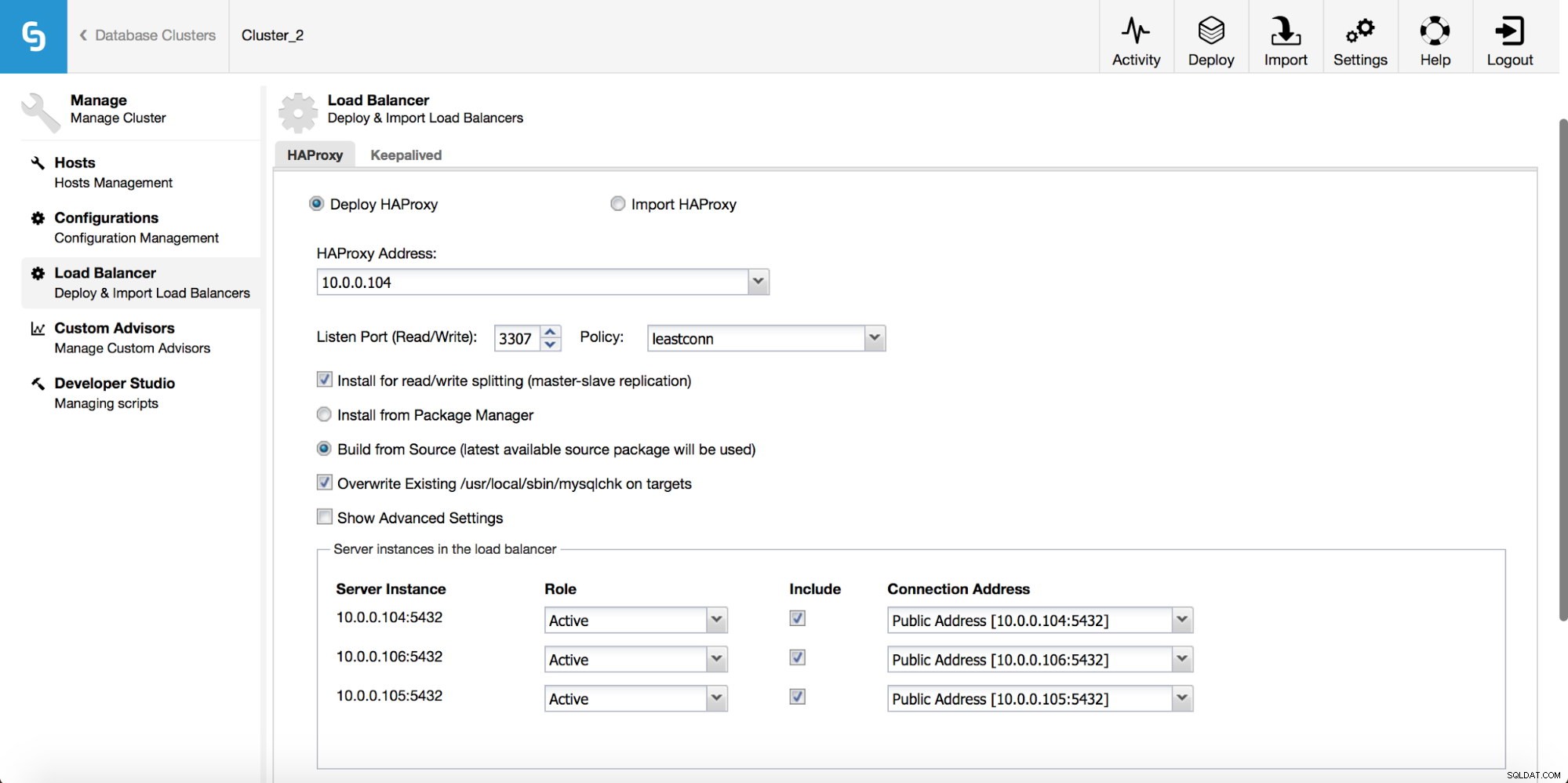
Nel menu a discesa del lavoro del cluster, hai la possibilità di aggiungere un servizio di bilanciamento del carico. Quindi viene visualizzata un'opzione per distribuire HAProxy. Devi inserire dove desideri installarlo e prendere alcune decisioni:dai repository che hai configurato sull'host o dall'ultima versione, compilata dal codice sorgente. Dovrai anche configurare quali nodi nel cluster desideri aggiungere ad HAProxy.
Una volta distribuita l'istanza HAProxy, puoi accedere ad alcune statistiche nella scheda "Nodi":
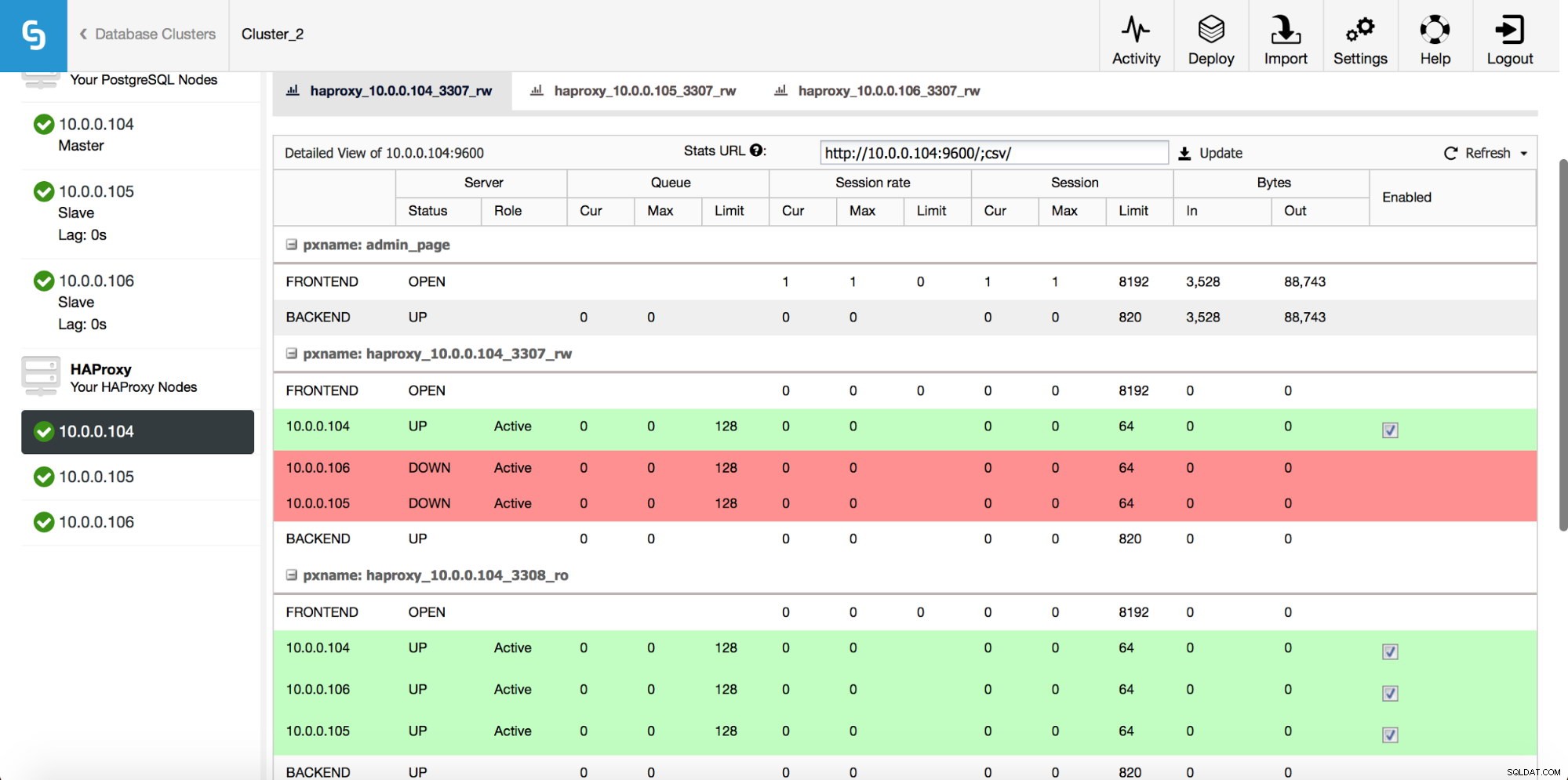
Come possiamo vedere, per il backend R/W, solo un host (server attivo) è contrassegnato come attivo. Per il backend di sola lettura, tutti i nodi sono attivi.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperMantenuto in vita
HAProxy si posizionerà tra le tue applicazioni e le istanze del database, quindi svolgerà un ruolo centrale. Sfortunatamente può anche diventare un singolo punto di errore, in caso contrario, non ci sarà alcun percorso verso i database. Per evitare una situazione del genere, è possibile distribuire più istanze HAProxy. Ma poi la domanda è:come decidere a quale host proxy connettersi. Se hai distribuito HAProxy da ClusterControl, è semplice come eseguire un altro lavoro "Aggiungi Load Balancer", questa volta implementando Keepalived.
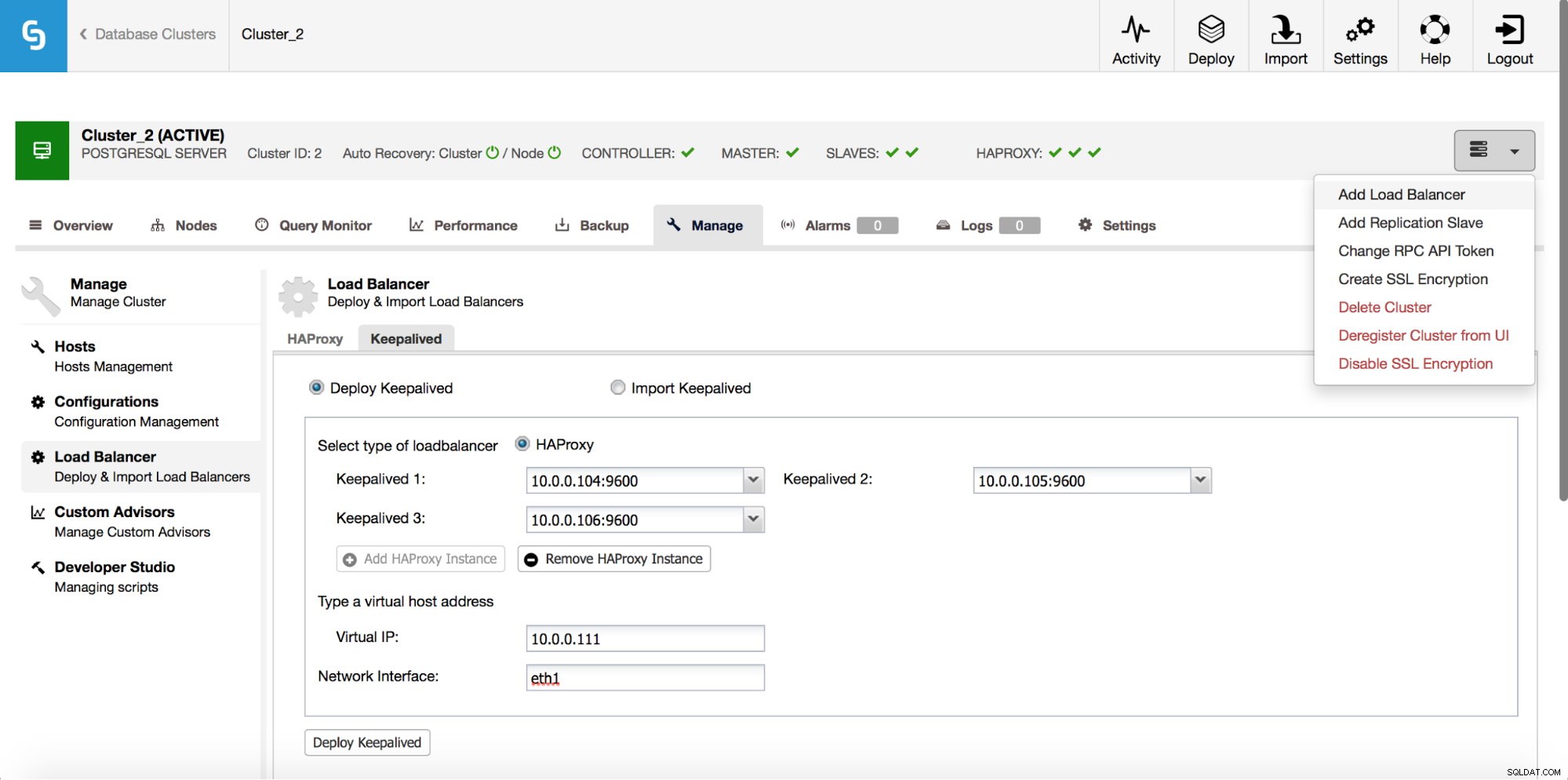
Come possiamo vedere nello screenshot qui sopra, puoi raccogliere fino a tre host HAProxy e Keepalived verrà distribuito su di essi, monitorando il loro stato. Ad uno di essi verrà assegnato un IP virtuale (VIP). La tua applicazione dovrebbe utilizzare questo VIP per connettersi al database. Se l'HAProxy "attivo" non sarà più disponibile, il VIP verrà spostato su un altro host.
Come abbiamo visto, è abbastanza facile distribuire uno stack completo ad alta disponibilità per PostgreSQL. Fai un tentativo e facci sapere se hai qualche feedback.