La replica svolge un ruolo cruciale nel mantenimento dell'elevata disponibilità. I server possono guastarsi, potrebbe essere necessario aggiornare il sistema operativo o il software del database. Ciò significa rimescolare i ruoli del server e spostare i collegamenti di replica, mantenendo la coerenza dei dati in tutti i database. Saranno necessarie modifiche alla topologia e sono disponibili diversi modi per eseguirle.
Promozione di un server in standby
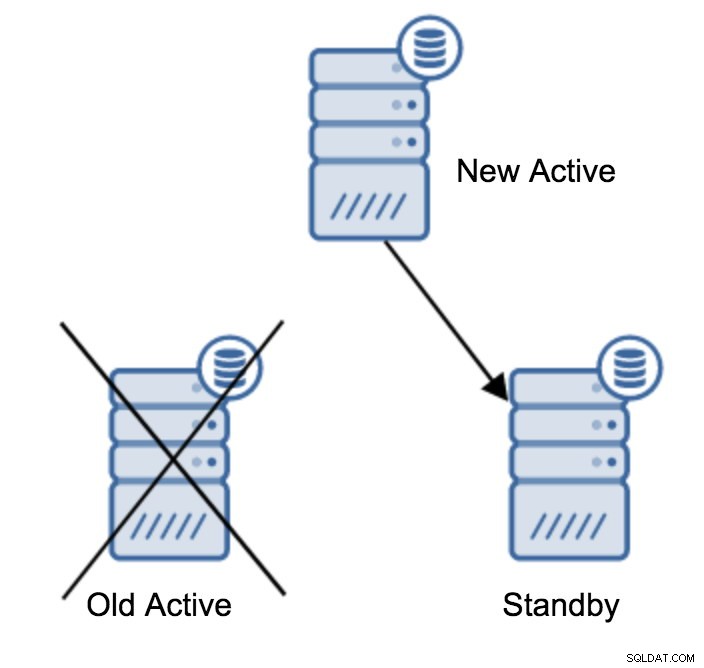
Probabilmente, questa è l'operazione più comune che dovrai eseguire. I motivi sono molteplici, ad esempio la manutenzione del database sul server primario che avrebbe un impatto inaccettabile sul carico di lavoro. Potrebbero essere previsti tempi di inattività a causa di alcune operazioni hardware. Il crash del server primario che lo rende inaccessibile all'applicazione. Questi sono tutti motivi per eseguire un failover, pianificato o meno. In tutti i casi dovrai promuovere uno dei server di standby per diventare un nuovo server primario.
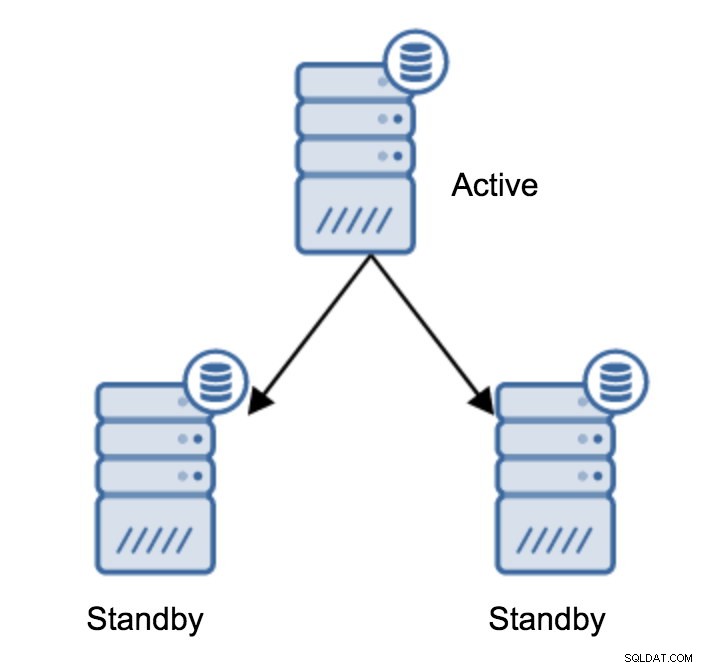
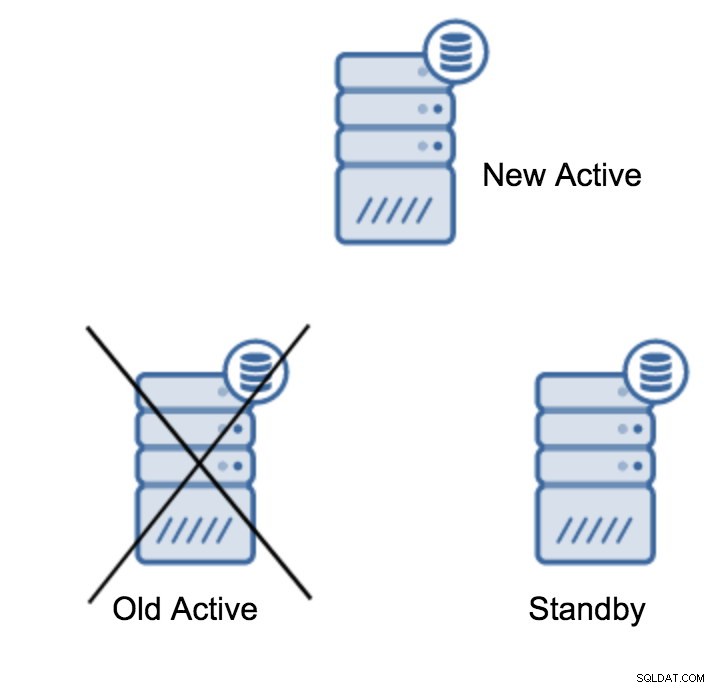
Per promuovere un server di standby, devi eseguire:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
server promotedÈ facile eseguire questo comando, ma prima assicurati di evitare qualsiasi perdita di dati. Se stiamo parlando di uno scenario di "server primario inattivo", potresti non avere troppe opzioni. Se si tratta di una manutenzione programmata, è possibile prepararla. È necessario interrompere il traffico sul server primario, quindi verificare che il server di standby abbia ricevuto e applicato tutti i dati. Questo può essere fatto sul server di standby, utilizzando la query come di seguito:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Quando tutto è a posto, puoi fermare il vecchio server primario e promuovere il server di standby.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri ciò che devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperReslave di un server di standby da un nuovo server primario
È possibile che più di un server di standby assorba il server primario. Dopotutto, i server in standby sono utili per scaricare il traffico di sola lettura. Dopo aver promosso un server di standby a un nuovo server primario, è necessario fare qualcosa per i restanti server di standby che sono ancora connessi (o che stanno tentando di connettersi) al vecchio server primario. Sfortunatamente, non puoi semplicemente modificare recovery.conf e collegarli al nuovo server primario. Per collegarli, devi prima ricostruirli. Ci sono due metodi che puoi provare qui:backup di base standard o pg_rewind.
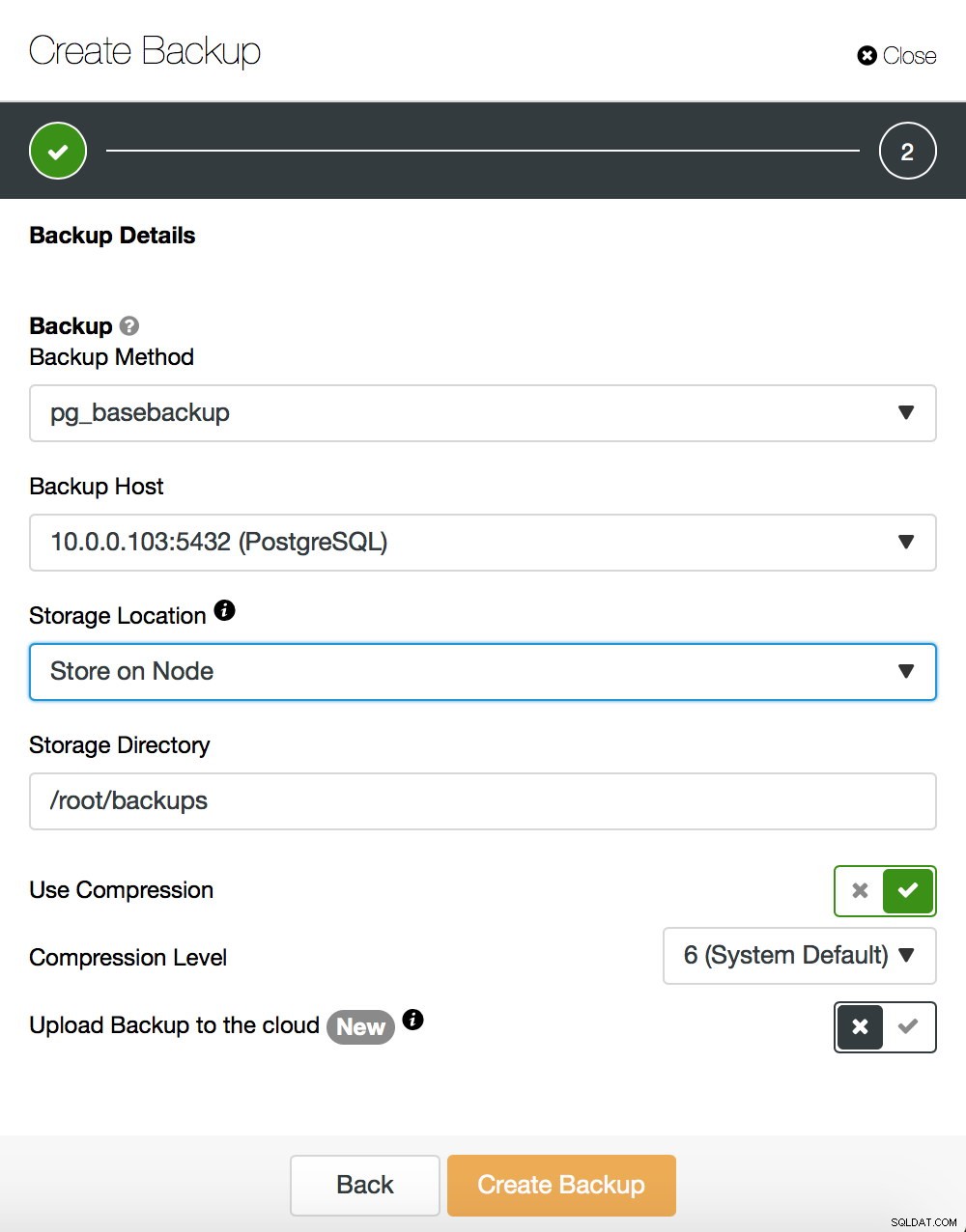
Non entreremo nei dettagli su come eseguire un backup di base:ne abbiamo parlato nel nostro precedente post sul blog, incentrato sull'esecuzione di backup e sul ripristino su PostgreSQL. Se ti capita di utilizzare ClusterControl, puoi anche usarlo per creare un backup di base:
D'altra parte, diciamo un paio di parole su pg_rewind. La principale differenza tra entrambi i metodi è che il backup di base crea una copia completa del set di dati. Se stiamo parlando di piccoli set di dati, può andare bene, ma per set di dati con dimensioni di centinaia di gigabyte (o anche più grandi), può diventare rapidamente un problema. Alla fine, vuoi avere i tuoi server di standby rapidamente attivi e operativi, per scaricare il tuo server attivo e avere un altro standby su cui eseguire il failover, in caso di necessità. Pg_rewind funziona in modo diverso:copia solo i blocchi che sono stati modificati. Invece di copiare tutto, copia solo le modifiche, accelerando notevolmente il processo. Supponiamo che il tuo nuovo master abbia un IP di 10.0.0.103. Ecco come eseguire pg_rewind. Tieni presente che devi fermare il server di destinazione - PostgreSQL non può essere eseguito lì.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Questo farà una corsa a secco , testando il processo ma senza apportare modifiche. Se tutto va bene, tutto ciò che dovrai fare sarà eseguirlo di nuovo, questa volta senza il parametro '--dry-run'. Una volta terminato, l'ultimo passaggio rimanente sarà creare un file recovery.conf, che punterà al nuovo master. Potrebbe assomigliare a questo:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Ora sei pronto per avviare il tuo server di standby e verrà replicato dal nuovo server attivo.
Replica concatenata
Esistono numerosi motivi per cui potresti voler creare una replica concatenata, sebbene in genere venga fatto per ridurre il carico sul server primario. Servire il WAL ai server in standby aggiunge un po' di sovraccarico. Non è un grosso problema se hai uno o due standby, ma se stiamo parlando di un gran numero di server standby, questo può diventare un problema. Ad esempio, possiamo ridurre al minimo il numero di server in standby che si replicano direttamente da quelli attivi creando una topologia come di seguito:
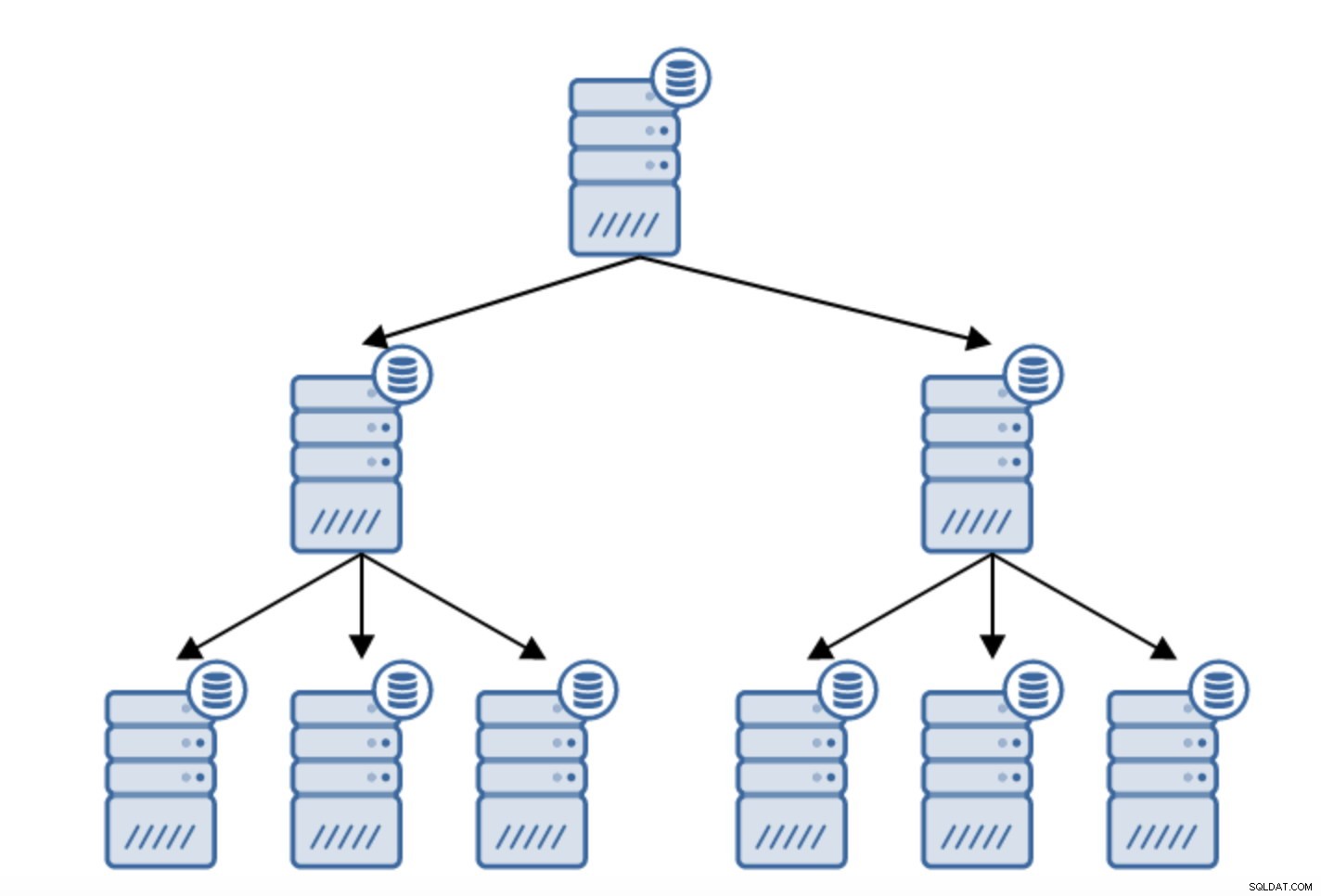
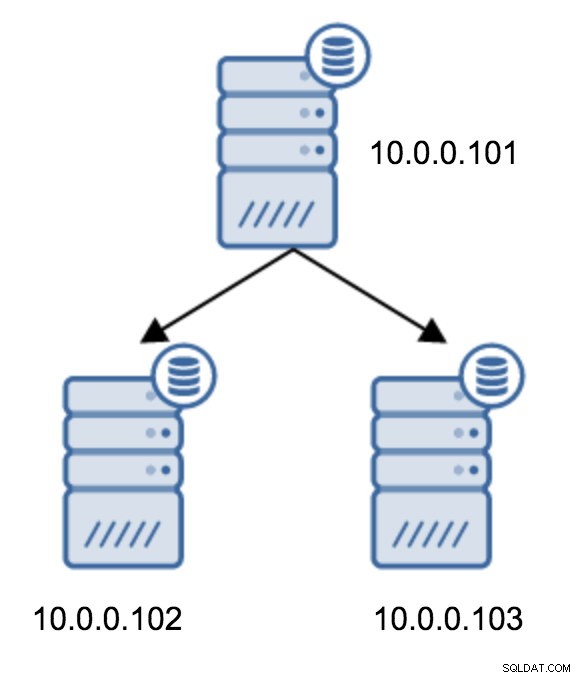
Il passaggio da una topologia di due server in standby a una replica concatenata è abbastanza semplice.
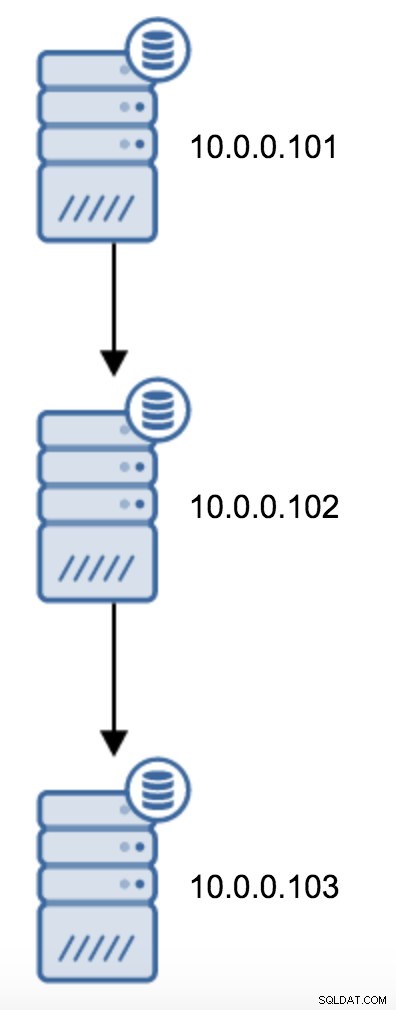
Dovresti modificare recovery.conf su 10.0.0.103, puntarlo verso 10.0.0.102 e quindi riavviare PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Dopo il riavvio, 10.0.0.103 dovrebbe iniziare ad applicare gli aggiornamenti WAL.
Questi sono alcuni casi comuni di modifiche alla topologia. Un argomento che non è stato discusso, ma che è comunque importante, è l'impatto di queste modifiche sulle applicazioni. Lo tratteremo in un post separato, oltre a come rendere queste modifiche alla topologia trasparenti alle applicazioni.