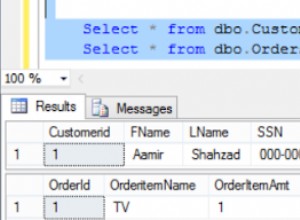
L'idea di base sarà l'utilizzo di una query nidificata con aggregazione del conteggio:
select * from yourTable ou
where (select count(*) from yourTable inr
where inr.sid = ou.sid) > 1
Puoi modificare la clausola where nella query interna per restringere la ricerca.
C'è un'altra buona soluzione per quella citata nei commenti, (ma non tutti le leggono):
select Column1, Column2, count(*)
from yourTable
group by Column1, Column2
HAVING count(*) > 1
O più breve:
SELECT (yourTable.*)::text, count(*)
FROM yourTable
GROUP BY yourTable.*
HAVING count(*) > 1