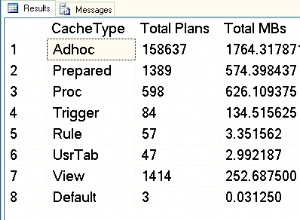
Per ottenere il risultato senza subquery , devi ricorrere all'inganno delle funzioni avanzate della finestra:
SELECT sum(count(*)) OVER () AS tickets_count
, sum(min(a.revenue)) OVER () AS atendees_revenue
FROM tickets t
JOIN attendees a ON a.id = t.attendee_id
GROUP BY t.attendee_id
LIMIT 1;
sqlfiddle
Come funziona?
La chiave per capirlo è la sequenza degli eventi nella query:
funzioni aggregate -> funzioni finestra -> DISTINCT -> LIMITE
Maggiori dettagli:
- Il modo migliore per ottenere il conteggio dei risultati prima dell'applicazione del LIMIT
Passo dopo passo:
-
I
GROUP BY t.attendee_id- che normalmente faresti in una sottoquery. -
Quindi somma i conteggi per ottenere il conteggio totale dei biglietti. Non molto efficiente, ma forzato dalle tue esigenze. La funzione aggregata
count(*)è racchiuso nella funzione della finestrasum( ... ) OVER ()per arrivare all'espressione non così comune:sum(count(*)) OVER ().E somma le entrate minime per partecipante per ottenere la somma senza duplicati.
Puoi anche usare
max()oavg()invece dimin()con lo stesso effetto direvenueè garantito che sia lo stesso per ogni riga per partecipante.Questo potrebbe essere più semplice se
DISTINCTera consentito nelle funzioni della finestra, ma PostgreSQL non ha (ancora) implementato questa funzionalità. Per documentazione:Le funzioni di aggregazione della finestra, a differenza delle normali funzioni di aggregazione, non consentono
DISTINCToORDER BYda utilizzare nell'elenco degli argomenti della funzione. -
Il passaggio finale è ottenere una singola riga. Questo può essere fatto con
DISTINCT(standard SQL) poiché tutte le righe sono uguali.LIMIT 1sarà più veloce, però. Oppure il modulo standard SQLFETCH FIRST 1 ROWS ONLY.