È buono, ma a volte può essere cattivo.
Lo sniffing dei parametri riguarda Query Optimizer che utilizza il valore del parametro fornito per determinare il miglior piano di query possibile. Una delle tante scelte e una che è abbastanza facile da capire è se l'intera tabella deve essere scansionata per ottenere i valori o se sarà più veloce usando le ricerche di indice. Se il valore nel tuo parametro è altamente selettivo, l'ottimizzatore creerà probabilmente un piano di query con ricerche e, in caso contrario, la query eseguirà una scansione della tua tabella.
Il piano di query viene quindi memorizzato nella cache e riutilizzato per query consecutive con valori diversi. La parte negativa dello sniffing dei parametri è quando il piano memorizzato nella cache non è la scelta migliore per uno di quei valori.
Dati di esempio:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
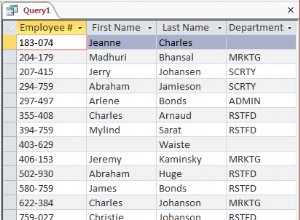
T è una tabella con un paio di migliaia di righe con un indice non cluster su Value. C'è una riga in cui il valore è 1 e il resto ha il valore 2 .
Esempio di query:
select *
from T
where Value = @Value;
Le scelte che Query Optimizer ha qui è eseguire una scansione dell'indice cluster e controllare la clausola where su ogni riga o utilizzare una ricerca dell'indice per trovare le righe che corrispondono e quindi eseguire una ricerca chiave per ottenere i valori dalle colonne richieste in l'elenco delle colonne.
Quando il valore sniffato è 1 il piano di query sarà simile al seguente:

E quando il valore annusato è 2 sarà simile a questo:
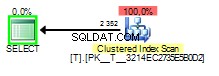
La parte negativa dello sniffing dei parametri in questo caso si verifica quando il piano di query viene creato annusando un 1 ma eseguito successivamente con il valore di 2 .
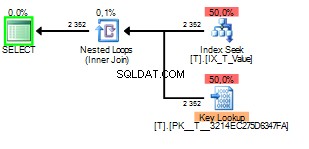
Puoi vedere che la ricerca chiave è stata eseguita 2352 volte. Una scansione sarebbe chiaramente la scelta migliore.
Per riassumere, direi che lo sniffing dei parametri è una buona cosa che dovresti provare a realizzare il più possibile utilizzando i parametri per le tue query. A volte può andare storto e in questi casi è molto probabilmente dovuto a dati distorti che alterano le tue statistiche.
Aggiornamento:
Ecco una query su un paio di dmv che puoi usare per trovare quali query sono più costose sul tuo sistema. Passa all'ordine per clausola per utilizzare criteri diversi su ciò che stai cercando. Penso che TotalDuration è un buon punto di partenza.
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;