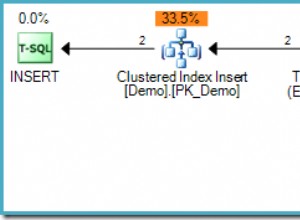
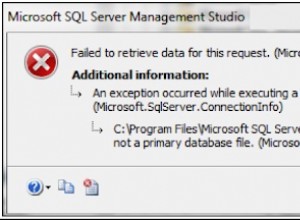
In tutti i principali prodotti RDBMS, Chiave primaria nei vincoli SQL ha un ruolo fondamentale. Identificano in modo univoco i record presenti in una tabella. Pertanto, dovremmo scegliere con attenzione il server delle chiavi primarie durante la progettazione della tabella per migliorare le prestazioni.
In questo articolo impareremo cos'è un vincolo di chiave primaria. Inoltre, vedremo come creare, modificare o eliminare i vincoli delle chiavi primarie.
Vincoli di SQL Server
In SQL Server, Vincoli sono regole che regolano l'inserimento dei dati nelle colonne necessarie. I vincoli impongono l'accuratezza dei dati e il modo in cui tali dati soddisfano i requisiti aziendali. Inoltre, rendono i dati affidabili per gli utenti finali. Ecco perché è fondamentale identificare i vincoli corretti durante la fase di progettazione del database o dello schema della tabella.
SQL Server supporta i seguenti Tipi di vincoli per rafforzare l'integrità dei dati:
Vincoli chiave primaria vengono creati su una singola colonna o una combinazione di colonne per rafforzare l'unicità dei record e identificare i record più velocemente. Le colonne coinvolte non devono contenere valori NULL. Quindi, la proprietà NOT NULL dovrebbe essere definita sulle colonne.
Vincoli delle chiavi straniere vengono creati su una singola colonna o una combinazione di colonne per creare una relazione tra due tabelle e imporre i dati presenti in una tabella all'altra. Idealmente, le colonne della tabella in cui è necessario applicare i dati con vincoli di chiave esterna fanno riferimento alla tabella di origine con un vincolo di chiave primaria in SQL o chiave univoca. In altre parole, possono essere inseriti o aggiornati nella tabella Destinazione solo i record disponibili nei vincoli Chiave primaria o unica della tabella Origine.
Vincoli chiave univoci vengono creati su una singola colonna o una combinazione di colonne per imporre l'univocità ai dati della colonna. Sono simili ai vincoli della chiave primaria con una singola modifica. La differenza tra la chiave primaria e i vincoli di chiave univoca è che questi ultimi possono essere creati su Nullable colonne e consenti un record di valore NULL nella relativa colonna.
Verifica vincoli vengono creati su una singola colonna o combinazione di colonne limitando i valori dei dati accettati per le colonne interessate tramite un'espressione logica. C'è una differenza tra chiave esterna e vincoli di controllo. La chiave esterna rafforza l'integrità dei dati controllando i dati dalla chiave primaria o univoca di un'altra tabella. Tuttavia, il Check Constraint esegue questa operazione utilizzando un'espressione logica.
Ora, esaminiamo i vincoli della chiave primaria.
Vincolo della chiave primaria
Il vincolo della chiave primaria applica l'univocità a una singola colonna o combinazione di colonne senza alcun valore NULL all'interno delle colonne coinvolte.
Per imporre l'univocità, SQL Server crea un indice cluster univoco nelle colonne in cui sono state create le chiavi primarie. Se sono presenti indici cluster esistenti, SQL Server crea un indice non cluster univoco nella tabella per la chiave primaria.
Vediamo come creiamo, modifichiamo, eliminiamo, disabilitiamo o abilitiamo le chiavi primarie su una tabella utilizzando gli script T-SQL.
Crea una chiave primaria
Possiamo creare chiavi primarie su una tabella durante la creazione della tabella o dopo. La sintassi varia leggermente per questi scenari.
Creazione della chiave primaria durante la creazione della tabella
La sintassi è la seguente:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Creiamo una tabella denominata Impiegati nelle Risorse Umane schema a scopo di test con lo script seguente:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
Abbiamo creato con successo HumanResources.Employees tabella su AdventureWorks banca dati:
Possiamo vedere che l'indice cluster è stato creato sulla tabella corrispondente al nome della chiave primaria come evidenziato sopra.
Rimuoviamo la tabella utilizzando lo script seguente e riproviamo con la nuova sintassi.
DROP TABLE HumanResources.EmployeesPer creare la chiave primaria in SQL su una tabella con il nome della chiave primaria definito dall'utente PK_Employees , usa la sintassi seguente:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Abbiamo creato HumanResources.Employees tabella con il nome della chiave primaria PK_Employees :
Creazione della chiave primaria dopo la creazione della tabella
A volte, gli sviluppatori o i DBA dimenticano le chiavi primarie e creano tabelle senza di esse. Ma è possibile creare una chiave primaria su tabelle esistenti.
Lasciamo perdere HumanResources.Employees tabella e ricrearla utilizzando lo script seguente:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Quando esegui correttamente questo script, possiamo vedere HumanResources.Employees tabella creata senza chiavi primarie o indici:

Per creare una chiave primaria denominata PK_Employees su questa tabella, usa la sintassi seguente:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
L'esecuzione di questo script crea la chiave primaria sulla nostra tabella:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Creazione della chiave primaria su più colonne
Nei nostri esempi, abbiamo creato chiavi primarie su singole colonne. Se vogliamo creare chiavi primarie su più colonne, abbiamo bisogno di una sintassi diversa.
Per aggiungere più colonne come parte della chiave primaria, dobbiamo semplicemente aggiungere valori separati da virgole dei nomi delle colonne che dovrebbero far parte della chiave primaria.
Chiave primaria durante la creazione della tabella
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Chiave primaria dopo la creazione della tabella
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Rilascia la chiave primaria
Per eliminare la chiave primaria, utilizziamo la sintassi seguente. Non importa se la chiave primaria era su una o più colonne.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
Per eliminare il vincolo della chiave primaria su HumanResources.Employees tabella, utilizzare lo script seguente:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
L'eliminazione della chiave primaria rimuove sia le chiavi primarie che gli indici cluster o non cluster creati insieme alla creazione della chiave primaria:
Modifica la chiave primaria
In SQL Server non sono disponibili comandi diretti per modificare le chiavi primarie. Dobbiamo eliminare una chiave primaria esistente e ricrearla con le modifiche necessarie. Quindi, i passaggi per modificare la chiave primaria sono:
- Rilascia una chiave primaria esistente.
- Crea nuove chiavi primarie con le modifiche necessarie.
Disabilita/Abilita chiave primaria
Durante l'esecuzione del caricamento in blocco su una tabella con molti record, disabilitare la chiave primaria e riabilitarla per prestazioni migliori. I passaggi sono di seguito:
Disabilita la chiave primaria esistente con la sintassi seguente:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;Per disabilitare la chiave primaria su HumanResources.Employees tabella, lo script è:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Abilita le chiavi primarie esistenti che si trovano nello stato disabilitato. Dobbiamo RICOSTRUIRE l'indice usando la sintassi seguente:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;Per abilitare la chiave primaria su HumanResources.Employees tabella, utilizzare il seguente script:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
I miti sulla chiave primaria
Molte persone si confondono sui miti di seguito relativi alle chiavi primarie in SQL Server.
- La tabella con chiave primaria non è una tabella heap
- Le chiavi primarie hanno l'indice raggruppato e i dati ordinati in ordine fisico
Chiariamoli.
La tabella con chiave primaria non è una tabella heap
Prima di approfondire, rivediamo la definizione della Chiave Primaria e della Tabella Heap.
La chiave primaria crea un indice cluster su una tabella se non sono disponibili altri indici cluster. Una tabella senza un indice cluster sarà una tabella heap.
Sulla base di queste definizioni, possiamo capire che la chiave primaria crea un indice cluster solo se non ci sono altri indici cluster sulla tabella. Se sono presenti indici cluster esistenti, la creazione della chiave primaria creerà un indice non cluster sulla tabella corrispondente alla chiave primaria.
Verifichiamolo eliminando HumanResources.Employees Tavolo e ricrearlo:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Possiamo specificare l'opzione dell'indice NON CLUSTERED per la chiave primaria (vedi sopra). È stata creata una tabella con un indice univoco, non in cluster per la chiave PK_Employees primaria .
Quindi, questa tabella è una tabella heap anche se ha una chiave primaria.
Vediamo se SQL Server può creare un indice non cluster per la chiave primaria se non specifichiamo la parola chiave Non cluster durante la creazione della chiave primaria. Usa lo script seguente:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
Qui abbiamo creato un indice cluster separatamente prima della creazione della chiave primaria. E una tabella può avere un solo indice cluster. Pertanto, SQL Server ha creato la chiave primaria come indice univoco, non cluster. Al momento, la tabella non è una tabella Heap perché ha un indice cluster.
Se cambiassi idea e lasciassi cadere l'indice cluster su First_Name e Cognome colonne utilizzando lo script seguente:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Abbiamo eliminato l'indice cluster con successo. Risorse umane.Dipendenti table è una tabella Heap anche se nella tabella è disponibile una chiave primaria:
Questo cancella il mito secondo cui una tabella con una chiave primaria può essere una tabella Heap se non sono disponibili indici cluster sulla tabella.
La chiave primaria avrà un indice raggruppato e dati ordinati in ordine fisico
Come abbiamo appreso dall'esempio precedente, una chiave primaria in SQL può avere un indice non cluster. In tal caso, i record non verrebbero ordinati in ordine fisico.
Verifichiamo la tabella con l'indice cluster su una chiave primaria. Verificheremo se ordina i record in ordine fisico.
Ricrea le HumanResources.Employees tabella con colonne minime e la proprietà IDENTITY rimossa per Employee_ID colonna:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Ora che abbiamo creato la tabella senza la chiave primaria o un indice cluster, possiamo INSERIRE 3 record in un ordine non ordinato per Employee_Id colonna:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Selezioniamo da HumanResources.Employees tabella:
SELECT *
FROM HumanResources.Employees
Possiamo vedere i record recuperati nello stesso ordine dei record inseriti dalla tabella Heap in questo momento.
Creiamo una chiave primaria su questa tabella Heap e vediamo se ha un impatto sull'istruzione SELECT:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Dopo la creazione della chiave primaria, possiamo vedere che l'istruzione SELECT ha recuperato i record in ordine crescente di Employee_Id (colonna Chiave primaria). È dovuto all'indice cluster su Employee_Id .
Se viene creata una chiave primaria con l'opzione non in cluster, i dati della tabella non verranno ordinati in base alla colonna Chiave primaria.
Se la lunghezza di un singolo record in una tabella supera i 4030 byte, un solo record può adattarsi a una pagina. L'indice cluster garantisce che le pagine siano in ordine fisico.
Una pagina è un'unità fondamentale di archiviazione nei file di dati di SQL Server con una dimensione di 8 KB (8192 byte). Solo 8060 byte di quell'unità sono utilizzabili per l'archiviazione dei dati. L'importo rimanente è per le intestazioni di pagina e altri interni.
Suggerimenti per scegliere le colonne della chiave primaria
- Le colonne dei tipi di dati interi sono più adatte per le colonne della chiave primaria poiché occupano dimensioni di archiviazione inferiori e possono aiutare a recuperare i dati più velocemente.
- Poiché per impostazione predefinita le colonne della chiave primaria hanno un indice raggruppato, utilizzare l'opzione IDENTITY sulle colonne dei tipi di dati interi per avere nuovi valori generati in ordine incrementale.
- Invece di creare una chiave primaria su più colonne, crea una nuova colonna intera con la proprietà IDENTITY definita. Inoltre, crea un indice univoco su più colonne originariamente identificate per prestazioni migliori.
- Cerca di evitare colonne con tipo di dati stringa come varchar, nvarchar, ecc. Non possiamo garantire l'incremento sequenziale dei dati su questi tipi di dati. Può influire sul rendimento INSERT su queste colonne.
- Scegli le colonne in cui i valori non verranno aggiornati come chiavi primarie. Ad esempio, se il valore della chiave primaria può cambiare da 5 a 1000, l'albero B associato all'indice cluster deve essere aggiornato con conseguenti lievi decrementi delle prestazioni.
- Se le colonne del tipo di dati stringa devono essere scelte come colonne della chiave primaria, assicurati che la lunghezza delle colonne del tipo di dati varchar o nvarchar rimanga piccola per prestazioni migliori.
Conclusione
Abbiamo esaminato le nozioni di base sui vincoli disponibili in SQL Server. Abbiamo esaminato in dettaglio i vincoli della chiave primaria e abbiamo imparato come creare, eliminare, modificare, disabilitare e ricostruire le chiavi primarie. Inoltre, abbiamo chiarito alcuni miti popolari sulle chiavi primarie con esempi.
Resta sintonizzato per il prossimo articolo!