Ti chiedi Come faccio a calcolare quali sono le città più strettamente correlate? Per esempio. Se stavo guardando la città 1 (Parigi), i risultati dovrebbero essere:Londra (2), New York (3) e in base al set di dati fornito c'è solo una cosa da mettere in relazione che sono i tag comuni tra le città, quindi le città che condividono i tag comuni sarebbero le più vicine sotto è la sottoquery che trova le città (diversa da quella fornita a trova le città più vicine) che condivide i tag comuni
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Lavorando
Presumo che inserirai uno degli ID o il nome della città per trovare quello più vicino nel mio caso "Parigi" ha l'id
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Troverà tutti i tag id che ha Parigi
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Recupererà tutte le città tranne Parigi che ha gli stessi tag che ha anche Parigi
Ecco il tuo Fiddle
Durante la lettura della somiglianza/indice di Jaccard ho trovato alcune cose da capire su cosa siano effettivamente i termini, prendiamo questo esempio, abbiamo due set A e B
Ora vai verso il tuo scenario
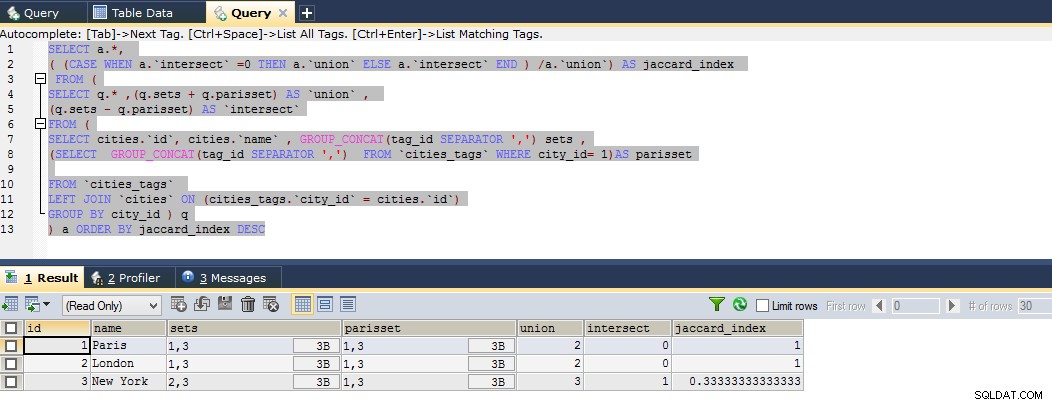
Ecco la query finora che calcola l'indice jaccard perfetto puoi vedere il seguente esempio di violino
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Nella query precedente ho derivato il set di risultati su due sottoselezioni per ottenere i miei alias calcolati personalizzati
Puoi aggiungere il filtro nella query precedente per non calcolare la somiglianza con se stessa
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Quindi il risultato mostra che Parigi è strettamente correlata a Londra e quindi a New York