Il monitoraggio delle modifiche allo schema del database in MySQL/MariaDB fornisce un enorme aiuto in quanto consente di risparmiare tempo nell'analisi della crescita del database, delle modifiche alla definizione delle tabelle, della dimensione dei dati, della dimensione dell'indice o della dimensione della riga. Per MySQL/MariaDB, l'esecuzione di una query che fa riferimento a information_schema insieme a performance_schema fornisce risultati collettivi per ulteriori analisi. Lo schema sys fornisce visualizzazioni che fungono da metriche collettive molto utili per tenere traccia delle modifiche o dell'attività del database.
Se hai molti server di database, sarebbe noioso eseguire sempre una query. Devi anche digerire quel risultato in un testo più leggibile e più facile da capire.
In questo blog creeremo un'automazione che sarebbe utile come strumento di utilità per monitorare il database esistente e raccogliere metriche relative alle modifiche al database o alle operazioni di modifica dello schema.
Creazione dell'automazione per il controllo degli oggetti dello schema del database
In questo esercizio, monitoreremo le seguenti metriche:
-
Nessuna tabella chiave primaria
-
Indici duplicati
-
Genera un grafico per il numero totale di righe nei nostri schemi di database
-
Genera un grafico per la dimensione totale dei nostri schemi di database
Questo esercizio ti darà un'idea e può essere modificato per raccogliere parametri più avanzati dal tuo database MySQL/MariaDB.
Utilizzo di Puppet per IaC e automazione
Questo esercizio utilizzerà Puppet per fornire automazione e generare i risultati attesi in base alle metriche che vogliamo monitorare. Non tratteremo l'installazione e la configurazione di Puppet, inclusi server e client, quindi mi aspetto che tu sappia come utilizzare Puppet. Potresti visitare il nostro vecchio blog Distribuzione automatizzata di MySQL Galera Cluster su Amazon AWS con Puppet, che copre la configurazione e l'installazione di Puppet.
Utilizzeremo l'ultima versione di Puppet in questo esercizio, ma poiché il nostro codice è costituito da una sintassi di base, verrà eseguito per le versioni precedenti di Puppet.
Server database MySQL preferito
In questo esercizio utilizzeremo Percona Server 8.0.22-13 poiché preferisco Percona Server principalmente per i test e alcune implementazioni minori per uso aziendale o personale.
Strumento grafico
Ci sono tantissime opzioni da usare specialmente usando l'ambiente Linux. In questo blog userò il più semplice che ho trovato e uno strumento opensource https://quickchart.io/.
Giochiamo con il burattino
Il presupposto che ho fatto qui è che tu abbia configurato il server master con un client registrato che è pronto a comunicare con il server master per ricevere distribuzioni automatiche.
Prima di procedere, ecco le informazioni sul mio server:
Server principale:192.168.40.200
Server client/agente:192.168.40.160
In questo blog, il nostro server client/agente è il luogo in cui è in esecuzione il nostro server di database. In uno scenario reale, non deve essere appositamente per il monitoraggio. Finché è in grado di comunicare in modo sicuro con il nodo di destinazione, anche questa è una configurazione perfetta.
Imposta il modulo e il codice
-
Vai al server master e nel percorso /etc/puppetlabs/code/environments/production/module, creiamo le directory richieste per questo esercizio:
mkdir schema_change_mon/{files,manifests}
-
Crea i file di cui abbiamo bisogno
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Riempi lo script init.pp con il seguente contenuto:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Riempi il file graphing_gen.sh. Questo script verrà eseguito sul nodo di destinazione e genererà grafici per il numero totale di righe nel nostro database e anche per la dimensione totale del nostro database. Per questo script, rendiamolo più semplice e consentiamo solo il tipo di database MyISAM o InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Infine, vai alla directory del percorso del modulo o /etc/puppetlabs/code/environments /produzione nella mia configurazione. Creiamo il file manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Quindi riempi il file manifests/schema_change_mon.pp con i seguenti contenuti,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Se hai finito, dovresti avere la seguente struttura ad albero proprio come la mia,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppCosa fa il nostro modulo?
Il nostro modulo chiamato schema_change_mon raccoglie quanto segue,
exec { "mysql-without-primary-key" :...
Che esegue un comando mysql ed esegue una query per recuperare tabelle senza chiavi primarie. Allora,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :che raccoglie gli indici duplicati che esistono nelle tabelle del database.
Successivamente, le linee generano grafici basati sulle metriche raccolte. Queste sono le righe seguenti,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Una volta eseguita correttamente la query, genera il grafico, che dipende dall'API fornita da https://quickchart.io/.
Ecco i seguenti risultati del grafico:
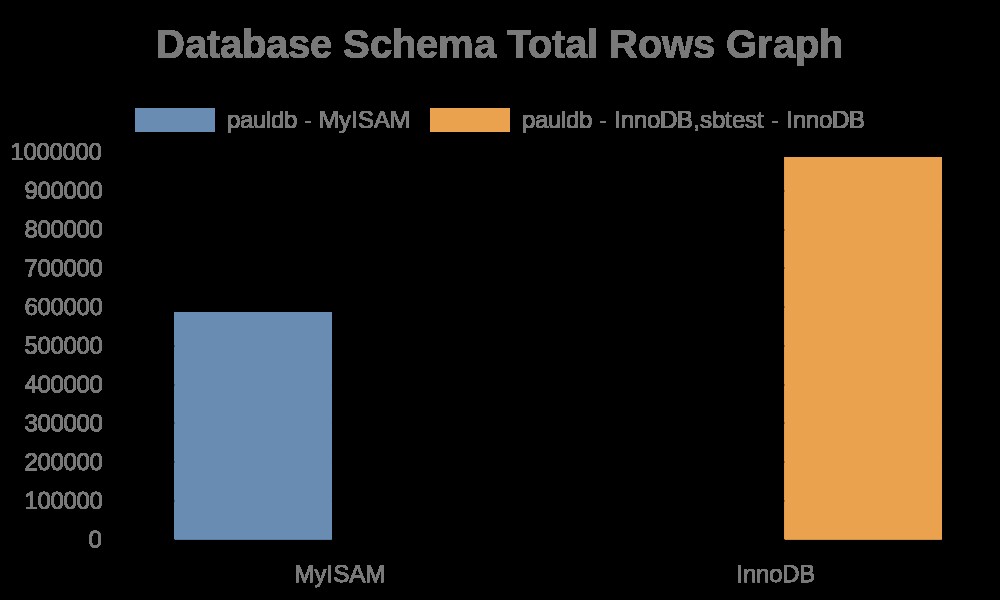
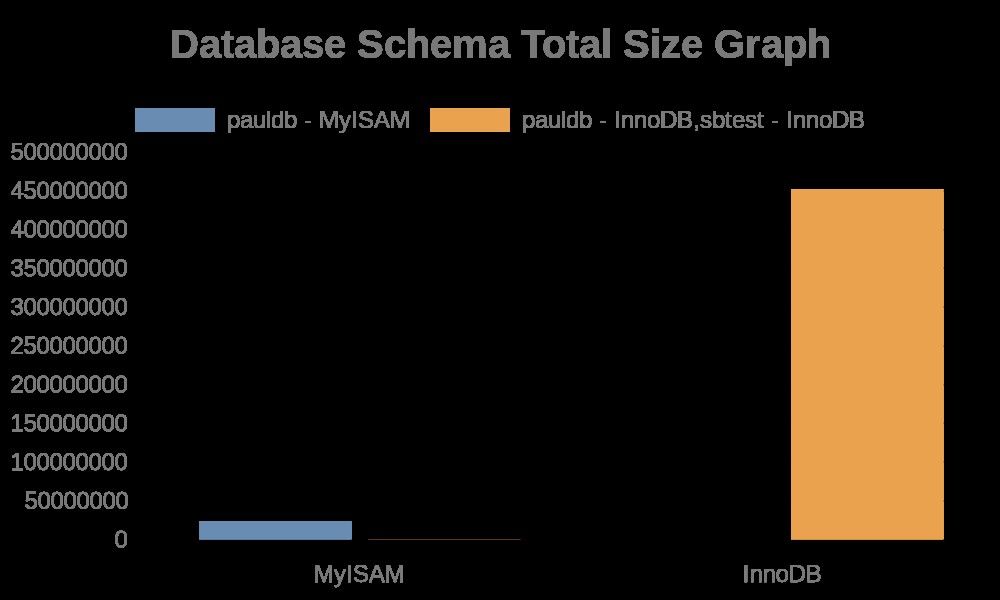
Mentre i log dei file contengono semplicemente stringhe con i nomi delle tabelle, i nomi degli indici. Vedi il risultato qui sotto,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBPerché non utilizzare ClusterControl?
Poiché il nostro esercizio mostra l'automazione e ottiene le statistiche dello schema del database come modifiche o operazioni, ClusterControl fornisce anche questo. Ci sono anche altre caratteristiche oltre a questa e non è necessario reinventare la ruota. ClusterControl può fornire i registri delle transazioni come deadlock come mostrato sopra o query a esecuzione prolungata come mostrato di seguito:
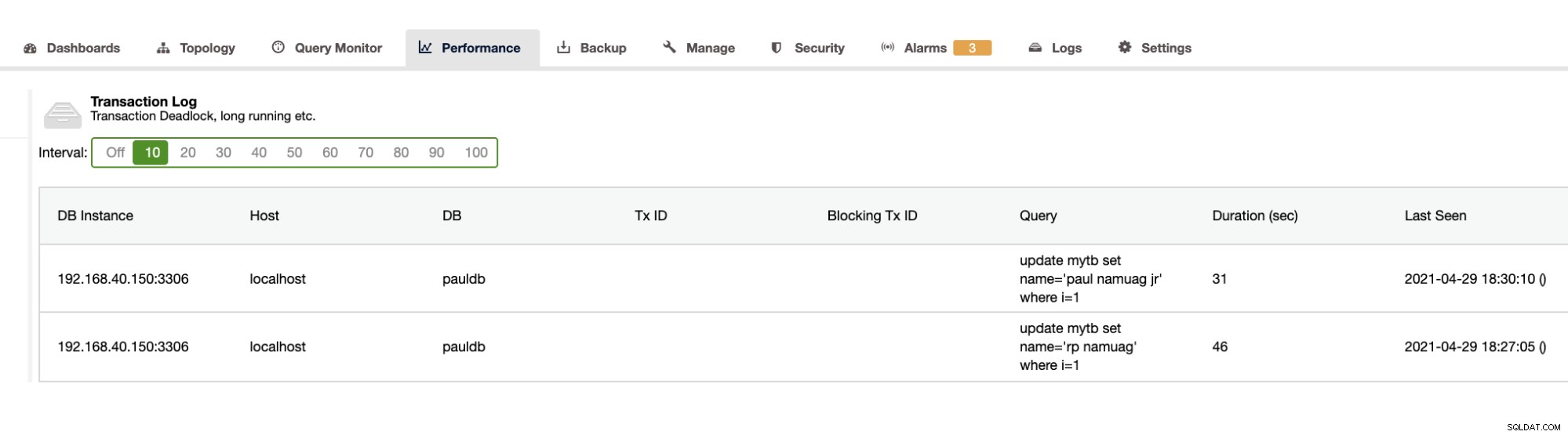
ClusterControl mostra anche la crescita del DB come mostrato di seguito,
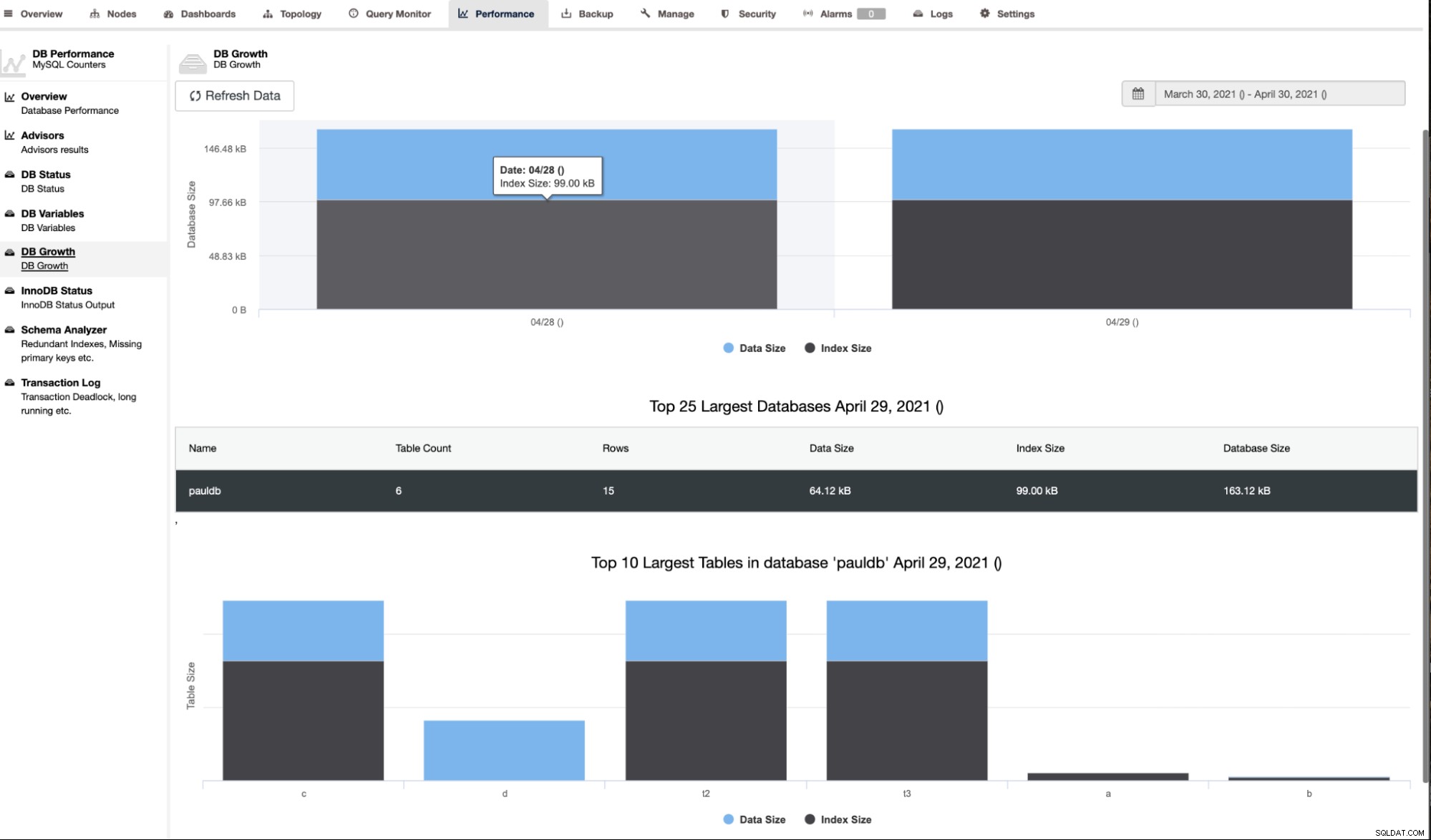
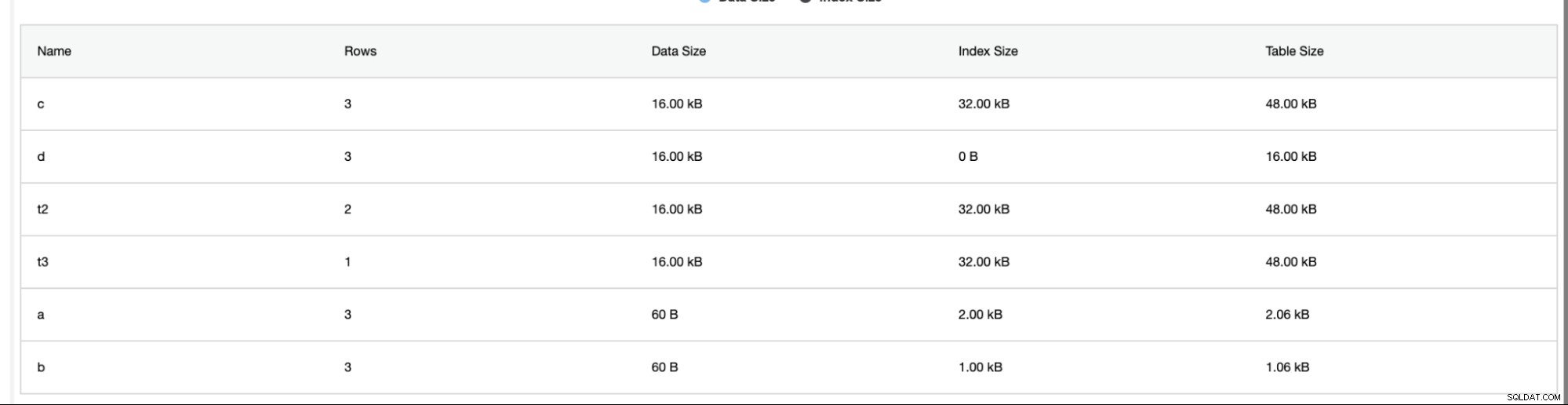
ClusterControl fornisce anche informazioni aggiuntive come il numero di righe, la dimensione del disco, la dimensione dell'indice e la dimensione totale.
L'analizzatore di schemi nella scheda Prestazioni -> Analizzatore di schemi è molto utile. Fornisce tabelle senza chiavi primarie, tabelle MyISAM e indici duplicati,

Fornisce anche allarmi nel caso vengano rilevati indici duplicati o tabelle senza primario tasti come di seguito,

Puoi controllare maggiori informazioni su ClusterControl e le sue altre funzionalità nella pagina del nostro prodotto.
Conclusione
Fornire l'automazione per monitorare le modifiche al database o qualsiasi statistica dello schema come scritture, indici duplicati, aggiornamenti operativi come modifiche DDL e molte attività del database è molto vantaggioso per i DBA. Aiuta a identificare rapidamente i collegamenti deboli e le query problematiche che ti darebbero una panoramica di una possibile causa di query errate che bloccherebbero il tuo database o renderebbero obsoleto il tuo database.