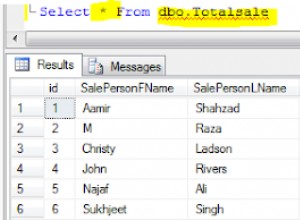
Non ci sono regole per le stringhe User-Agent, quindi non c'è modo di creare un parser completamente corretto e a prova di futuro. C'è però uno schema generale:
User-Agent: <engine-string> <engine-string> ...
Dove engine-string ha forma:
<agent-name> (<comment>; <comment>; ...)
Ogni stringa del motore (l'ho appena chiamata così da quanto ho capito, potrebbe non essere corretta) può avere o meno commenti.
Ad esempio:
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) ↲
AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e ↲
Safari/8536.25 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
(Questa è una singola stringa, l'ho appena suddivisa in righe.) Sembra che ogni volta che qualcuno fa un fork di un motore del browser, aggiunga semplicemente la sua cosa alla fine. Quindi abbiamo un browser astratto "Mozilla" (un'eredità della "First Browser War") che pensa sia su iPhone. Poi vediamo che c'è un WebKit (che ricorda che è nato come KHTML qualche tempo fa). Poi c'è qualche modifica alla versione/6.0, che è stata poi modificata in Mobile/10A5376e, che è diventato Safari/8536.25, che finalmente rivela il segreto che si tratta in realtà di un bot di Google mobile.
Un altro esempio:
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.4; ↲
InfoPath.1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; ↲
.NET CLR 3.5.30729; .NET CLR 1.1.4322)
Questo è un unico motore, ma ha molto da dire tra parentesi.
Quindi l'osservazione generale è:
- le ultime stringhe del motore sono le più importanti
- Gli ultimi commenti tra parentesi sono meno importanti.
Tenendo questo in mente, la mia idea sarebbe quella di analizzare la stringa in questi token del motore e dei commenti, quindi da ogni sezione del motore buttare via i commenti a partire, ad esempio, dal quinto. Poi, se ancora non bastasse, buttate via le sezioni del motore a partire dalla seconda (la prima è spesso un "Mozilla" astratto, ma spesso contiene commenti utili; inoltre a volte è effettivamente qualcosa di concreto, soprattutto per i web crawler).
Durante l'analisi, dobbiamo tenere conto del fatto che occasionalmente potrebbero esserci stringhe che non seguono questo formato. Possono essere salvati in un file di registro per un'ispezione successiva e quindi semplicemente tagliati alla lunghezza necessaria per adattarli al database.