Il tuo valore esadecimale è un GUID? Sebbene mi preoccupassi delle prestazioni di elementi così lunghi come gli indici, ho scoperto che nei database moderni la differenza di prestazioni anche su milioni di record è abbastanza insignificante.
Un problema potenzialmente più grande è la memoria che consuma l'indice (16 byte contro 4 byte int, ad esempio), ma sui server che controllo posso allocare per quello. Finché l'indice può essere in memoria, trovo che ci sia più sovraccarico da altre operazioni che la dimensione dell'elemento dell'indice non fa una differenza evidente.
Al rialzo, se si utilizza un GUID si ottiene l'indipendenza dal server per i record creati e una maggiore flessibilità nell'unione di dati su più server (che è qualcosa a cui tengo, poiché il nostro sistema aggrega i dati dai sistemi figlio).
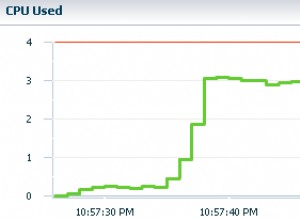
C'è un grafico su questo articolo che sembra sostenere i miei sospetti:Miti, GUID vs Autoincrement