Ecco come questi due approcci verranno rappresentati fisicamente nel database:
Analizziamo entrambi gli approcci...
Approccio 1 (entrambe le direzioni memorizzate nella tabella):
- PRO:query più semplici.
- CON:I dati possono essere danneggiati inserendo/aggiornando/cancellando solo una direzione.
- MINOR PRO:non richiede vincoli aggiuntivi per garantire che un'amicizia non possa essere duplicata.
- Sono necessarie ulteriori analisi:
- TIE:Un indice copertine entrambe le direzioni, quindi non hai bisogno di un indice secondario.
- TIE:requisiti di archiviazione.
- TIE:Performance.
Approccio 2 (solo una direzione memorizzata nella tabella):
- CON:Query più complicate.
- PRO:non è possibile corrompere i dati dimenticando di gestire la direzione opposta, poiché non esiste una direzione opposta .
- CON MINORE:Richiede
CHECK(UID < FriendID), quindi una stessa amicizia non può mai essere rappresentata in due modi diversi, e la chiave su(UID, FriendID)può fare il suo lavoro. - Sono necessarie ulteriori analisi:
- TIE:sono necessari due indici per coprire
entrambe le direzioni di interrogazione (indice composito su
{UID, FriendID}e indice composito su{FriendID, UID}). - TIE:requisiti di archiviazione.
- TIE:Performance.
- TIE:sono necessari due indici per coprire
entrambe le direzioni di interrogazione (indice composito su
Il punto 1 è di particolare interesse. MySQL/InnoDB sempre cluster dati e indici secondari possono essere costosi nelle tabelle raggruppate (vedi "Svantaggi del clustering" in questo articolo ), quindi potrebbe sembrare che l'indice secondario nell'approccio 2 consumerebbe tutti i vantaggi di un minor numero di righe. Tuttavia , l'indice secondario contiene esattamente gli stessi campi del primario (solo nell'ordine opposto), quindi non vi è alcun sovraccarico di archiviazione in questo caso particolare. Inoltre, non esiste un puntatore all'heap della tabella (poiché non esiste un heap della tabella), quindi è probabilmente ancora più economico in termini di archiviazione rispetto a un normale indice basato sull'heap. E supponendo che la query sia coperta dall'indice, non ci sarà nemmeno una doppia ricerca normalmente associata a un indice secondario in una tabella cluster. Quindi, questo è fondamentalmente un pareggio (né l'approccio 1 né l'approccio 2 hanno un vantaggio significativo).
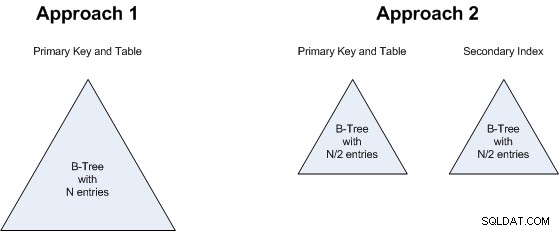
Il punto 2 è relativo al punto 1:non importa se avremo un B-Albero di N valori o due B-Alberi, ciascuno con N/2 valori. Quindi anche questo è un pareggio:entrambi gli approcci utilizzeranno all'incirca la stessa quantità di spazio di archiviazione.
Lo stesso ragionamento vale per il punto 3 :se cerchiamo un B-Tree più grande o 2 più piccoli, non fa molta differenza, quindi anche questo è un pareggio.
Quindi, per la robustezza, e nonostante le query un po' più brutte e la necessità di ulteriori CHECK , io andrei con l'approccio 2.